- 一、深度学习-学前解说
-
二、深度学习-学前热身
-
2.1.环境搭建
-
2.2.从逻辑回归开始吧!
-
2.3.认识一下softmax喽
-
-
三、开始玩MLP啦
-
3.1.开始玩MLP啦
-
3.2.简单玩玩MLP
-
-
四、大型深层MLP
-
4.1.多层大型MLP咋搞
-
4.2.大型MLP如何训练
-
4.3.面向深度学习玩一玩MLP
-
- 五、简单玩玩CNN
- 六、简单玩玩RNN
-
本章结束语
-
7.1.结束语
-
 老饼讲解:一步一步上手深度学习
老饼讲解:一步一步上手深度学习
【代码】用pytorch-训练逻辑回归
好了,这节我们使用pytorch来训练一下逻辑回归模型。
学以致用,再爽不过~让我们开始吧!
一、用pytorch来训练一个逻辑回归模型
好了,下面我们看看怎么用pytorch来训练一个逻辑回归模型。这样可以复习之前学到的各种内容:pytorch的使用啦,逻辑回归模型啦,梯度下降算法啦,等等等等。
好了,直接上代码吧,用pytorch训练逻辑回归模型的代码如下:
# pytroch实现逻辑回归模型
# 本代码来自《老饼讲解-深度学习》www.bbblearn.com
import torch
import matplotlib.pyplot as plt
# ------训练数据----------------
x = torch.tensor([[2.5, 1.3, 6.2, 1.3, 5.4, 6 ,4.3, 8.2]
,[-1.2,2.5,3.6,4,3.4,2.3,7.2,3.9]]).T # 训练数据x
y = torch.tensor([0,0,1,0,1,1,1,1]) # 训练数据y
#-----------训练模型----------
w = torch.tensor([2.,2.],requires_grad=True) # 初始化模型系数w
b = torch.tensor([1.],requires_grad=True) # 初始化模型系数b
lr = 0.01 # 学习率
for i in range(1000):
L = (torch.log(1+torch.exp(x@w+b)) -y*(x@w+b)).sum() # 损失函数
print('第',str(i),'轮:',L) # 打印当前损失函数值
L.backward() # 用损失函数更新模型系数的梯度
w.data=w.data-w.grad*lr # 更新模型系数w
b.data=b.data-b.grad*lr # 更新模型系数b
w.grad.zero_() # 清空w的梯度,以便下次backward
b.grad.zero_() # 清空b的梯度,以便下次backward
# ----------画出结果-----------
print('--------最终结果-------')
W = w.detach().numpy() # 模型的系数,先转回numpy
B = b.item() # 模型的阈值,先转回数值
X = x.numpy() # x转回numpy
Y = y.numpy() # y转回numpy
print('W:',W) # 打印模型系数W
print('B:',B) # 打印模型系数B
x1 = X[:,0] # 绘制分割平面的x轴
x2 = (-B - W[0]*x1)/W[1] # 绘制分割平面的y轴
plt.scatter(X[:, 0], X[:, 1],c=Y) # 绘制样本
plt.plot(x1,x2) # 绘制分割平面
plt.axis([min(X[:,0])-1,max(X[:,0])+1,min(X[:,1])-1,max(X[:,1])+1]) # 设置坐标范围
plt.show() # 展示图象 运行结果如下:
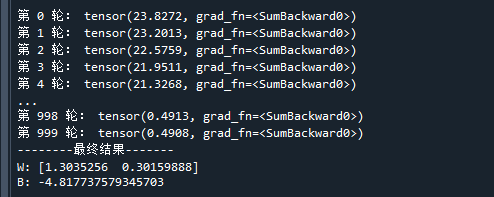
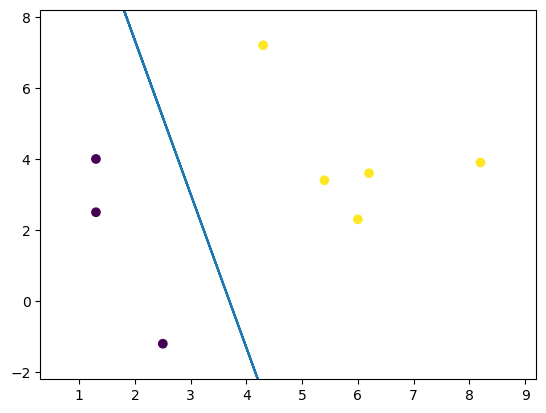
可以看到,训练了999步后,模型得到了参数,此时损失值为0.4908。再看逻辑回归模型的分割平面,它已经成功地识别出两类样本。
二、代码解说
好了,下面我们逐部分对代码进行解说,借着这些代码,学习pytorch再好不过了。
2.1. 数据导入-代码解说
首先是数据导入部分,这没什么好说的,就是训练样本的x和y。

2.2. 参数预设-代码解说

这部分我们初始化了参数,以及设置了学习率。
细心的朋友可能会发现,我们w = torch.tensor([2.,2.])中用了“2.”而不是"2",因为w是小数类型,如果直接用“2”可能会被认为是整数类型哦,加了一个点之后才会被认为是小数。
这里,都是参数,后面我们要让pytorch来计算它们的梯度,因此指定了requires_grad=True,而不需要,因为不需要计算它的梯度。
2.3. 模型训练-代码解说
好了,下面一起来看看模型训练的代码。

第15行就是我们的二分类交叉熵损失函数了,这里刚开始学习嘛,就自己写写公式,这样比较具体实在一点。其实pytorch内部已经提供了交叉熵函数给我们直接使用,以后我们一般都会直接调用函数,比较省代码一些。
好了,在计算了损失函数后,第17行我们就进行Backward了,这时pytorch就会拼命干活了,把L依赖的变量的梯度都计算出来,如果这时你去查看的梯度,就会发现backward完它们的梯度就改变了。
第18、19行没什么好说的,就是按负梯度去更新。
最后,第20、21行,我们把的梯度清零。为什么要清零呢?刚开始玩的朋友可能就有些不明白了。这是因为每次backward的时候,pytorch并不是计算梯度然后赋值,而是把新计算的梯度累加到参数原来的梯度上。即它是:w.grad = w.grad+grad,而不是w.grad = grad。所以我们这里清空它,下次计算梯度时才是我们想要的梯度。
2.4. 结果展示-代码解说
最后是我们展示结果、画出结果图的代码了,可以看,也可以不看,无关要紧的代码。

如果你要看,那我就说说。首先是因为画图时要用到,但它是tensor对象,画图对象plt不认这家伙,所以我要将它们转换回我亲爱的numpy对象。
细心的小朋友又会发现了,怎么转换回numpy对象时,使用的是detach().numpy(),而x和y却使用numpy()就行了。这是因为w是带梯度的对象,而x,y是普通的对象,由于说过了,带梯度的对象会被pytorch特别对待,它在backward时会开启一个运算图,所以需要先用detach(脱离)将它从运算图中拆卸出来,再转为numpy。就好比w被pytorch带到包间去款待了,现在要先从包间里叫他出来(detach),再一起搭车去当numpy。
哦,把b给漏了,我们这里直接用b.item()就行了,因为b是一个数值,所以直接item就能转换回python的普通数值类型了,而不需要转为numpy。
好了,后面就是计算模型的分割平面和画图了,没什么营养,就不看了。
总结
这节我们用pytorch来玩了玩逻辑回归模型的训练,主要亮点就是借用pytorch的自动梯度功能,这比起用一些传统编程语言要方便得多,因为不再需要自己计算梯度了。
通过本节玩完代码,相信小白朋友又可以更具体地习惯和熟悉一下pytorch的语法和使用方法了吧~!的确,这些语法一本正经的去学,非常枯燥和抽象,跟着代码一点一点的积累和熟悉最有效不过了。
 评论
评论
