- 一、深度学习-学前解说
-
二、深度学习-学前热身
-
2.1.环境搭建
-
2.2.从逻辑回归开始吧!
-
2.3.认识一下softmax喽
-
-
三、开始玩MLP啦
-
3.1.开始玩MLP啦
-
3.2.简单玩玩MLP
-
-
四、大型深层MLP
-
4.1.多层大型MLP咋搞
-
4.2.大型MLP如何训练
-
4.3.面向深度学习玩一玩MLP
-
- 五、简单玩玩CNN
- 六、简单玩玩RNN
-
本章结束语
-
7.1.结束语
-
 老饼讲解:一步一步上手深度学习
老饼讲解:一步一步上手深度学习
【代码】来训练一个-softmax回归
好了,这一节我们使用pytorch来训练一个softmax回归,用于多类别的预测。
一方面可以更具体的熟悉softmax回归,另一方面也可以加强pytorch的代码实现能力。
一、softmax回归-实现代码
好了,闲话少说,pytorch实现softmax回归的实现代码如下:
# 本代码用于展示:pytroch训练softmax回归模型
# 本代码来自《老饼讲解-深度学习》www.bbblearn.com
import torch
# ------训练数据----------------
x = torch.tensor([[2.5, 1.3, 6.2, 1.3, 5.4, 6 ,3.3, 7.2]
,[-0.2,3.5,3.6,4,3.4,2.3,0.2,3.9]],dtype=float) # 训练数据x
y = torch.tensor([[0,1,0,1,0,0,0,0]
,[0,0,1,0,1,1,0,1]
,[1,0,0,0,0,0,1,0]],dtype=float) # 训练数据y
#-----------训练模型----------
w = torch.zeros(3,2,dtype=float,requires_grad=True) # 初始化模型系数w
b = torch.rand(3,1,dtype=float,requires_grad=True) # 初始化模型系数b
lossFun = torch.nn.CrossEntropyLoss() # 定义损失函数为交叉熵损失函数
lr = 0.1 # 学习率
for i in range(1000): # 训练1000轮
py = w@x+b # 计算模型预测值
L = lossFun(py.T,y.T) # 计算损失函数值
print('第',str(i),'轮:',L.item()) # 打印当前损失函数值
L.backward() # 更新模型参数的梯度
w.data = w.data-w.grad*lr # 更新模型参数w
b.data = b.data-b.grad*lr # 更新模型参数b
max_g = max(w.grad.abs().max(),b.grad.abs().max()) # 计算参数梯度的最大绝对值
if(max_g<0.01): # 如果梯度过小
break # 退出训练
w.grad.zero_() # 清空w的梯度,以便下次backward
b.grad.zero_() # 清空b的梯度,以便下次backward
p = torch.softmax(w@x+b,dim=0) # 计算模型的预测概率
true_lable = torch.argmax(y,dim=0) # 样本的真实标签值
predit_label = torch.argmax(p,dim=0) # 样本的预测标签值
print("真实类别:",true_lable) # 打印真实标签值
print("预测类别:",predit_label) # 打印预测标签值运行结果如下:
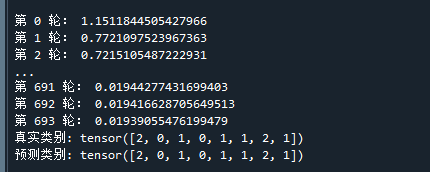
可以看到,当训练了693步时,由于梯度过小,就退出了训练。
最终,用模型对训练样本进行预测,可以看到,预测类别与真实类别一致,说明模型已训练成功。
二、代码解说
好了,下面我们逐段讲解一下代码内容,这样又可以学习一下pytorch的语法。
2.1. 数据导入
第一部分是数据导入,没什么好说的,无非就是导入x和one-hot形式的y。

在这里我们指定数据类型为float,避免后面使用一些函数时数据类型对不上。
2.2. 模型训练
好了,下面讲讲模型训练部分的代码。

先是第13、14行,这是参数的初始化。这里我们将w初始化为全0矩阵,b则随机初始化。同样地,我们指定它们的数据类型为float。
在第15行,我们以pytorch提供的交叉熵损失函数作为我们的损失函数,下面调用它来计算损失值就行了。
接下来是训练部分的代码了。
第18、19行是计算损失值L。眼尖的同学会发现,这里计算完后就扔给CrossEntropyLoss去计算损失值了,理论上softmax回归的输出不该是么?这就不得不说pytorch的CrossEntropyLoss函数了,它实际上是包含了softmax的,它并不是我们所理解的CrossEntropy(p,y),而是CrossEntropy(softmax(p),y)。所以这里我们计算完wx+b就要放到CrossEntropy计算损失了,如果使用会令softmax的计算重复。
好了,计算完损失值L后,第21行将它进行backward,就会更新参数w,b的梯度了。
接下来22、23行按梯度下降法,将参数往负梯度方向调整。
第24-26行则判断当前梯度是否过小了,如果过小,则说明到达极值点附近,则终止训练。
最后,27、28清空梯度,避免下次backward时累计梯度。
2.3.结果打印
训练完模型后,我们在29-33行使用模型对样本进行预测、并打印结果,它的代码如下:

这没什么好说的,第29行就是计算模型的输出值,然后30、31行分别计算样本的真实、预测标签,最后是打印结果。这里可以看到,对于softmax、argmax函数我们都用dim来指定维度。
结束语
好了,这节我们简单地用pytorch实现了一个softmax,进一步熟悉了pytorch的相关使用,并认识了pytorch中的CrossEntropyLoss交叉熵函数的使用方法,简简单单,又学到了新知识。
 评论
评论
