- 一、深度学习-学前解说
-
二、深度学习-学前热身
-
2.1.环境搭建
-
2.2.从逻辑回归开始吧!
-
2.3.认识一下softmax喽
-
-
三、开始玩MLP啦
-
3.1.开始玩MLP啦
-
3.2.简单玩玩MLP
-
-
四、大型深层MLP
-
4.1.多层大型MLP咋搞
-
4.2.大型MLP如何训练
-
4.3.面向深度学习玩一玩MLP
-
- 五、简单玩玩CNN
- 六、简单玩玩RNN
-
本章结束语
-
7.1.结束语
-
 老饼讲解:一步一步上手深度学习
老饼讲解:一步一步上手深度学习
【训练】认识一下--SGD训练算法
如果说,梯度下降算法是机器学习最基本的训练算法,那么,SGD算法,就算是深度学习的最基本的训练算法。这节我们认识一下SGD算法,这样我们才能正正经经地开启深度学习模型的训练。
SGD算法全称为Stochastic Gradient Descent(随机梯度下降),事实上,深度学习中常说的SGD算法并不是纯粹的机器学习中的SGD算法,而是"随机批量-动量-梯度下降法"。因此,我们拆为两部分讲,一部分是随机批量-梯度下降法,另一部分是动量-梯度下降,最后将它们结合,才是深度学习的SGD算法。
一、什么是SGD算法
我们这里讲的SGD,是随机-批量-梯度下降法,也就是传统机器学习中的SGD算法。
1.1. 什么是随机梯度下降法
先说随机梯度下降法,它指的是在梯度下降法中,每次只随机选择一个样本来计算梯度,然后按负梯度下降,接着又随机选一个样本计算梯度,然后按负梯度下降....如此如此,即每次计算一个样本的梯度就马上去调整参数了。

为啥这样做?因为这样比全量计算再调整梯度的效果更加好。
详细原理我也没去详细考究、不想搞得这么累。但是,简单理解一下也能知道它效果好呀!你想想,整体100个样本,我抽一个样本计算梯度、并以它作为对整体梯度的评估,这估计效果肯定倍,因为从1到100逐个增加样本去估算这100个样本的梯度,从边际效应来说,第1个的效益肯定是最大的,然后效果逐步减少,所以1个样本的估算效果肯定>整体的1/100。好了,我调整一次的效益大于你整体的1/100,那么我调整100次肯定就大于整体调整了,而两者的代价同样是计算100个样本的梯度。好了,详细原理是真的不想去考究了,就大概这样理解吧~
1.2. 什么是随机-批量-梯度下降法
好了,理解了随机梯度下降法,那么随机批量梯度下降就好理解了。它就是一次随机抽一批来计算梯度,然后调整参数。毕竟,随机梯度下降法每次只抽一个样本就调整一次参数,太累了,电脑会有意见。另一方面,样本多的时候,例如100万个样本,抽一个就太吝啬了,估算效果可能有点渣,豪爽点!抽100个给它又怎么样~这都还能抽一万次呢!嗯,一豪爽,就是随机批量梯度下降了~
所以,在深度学习中,一般都是成批成批的抽,而不是一个一个的抽,毕竟深度学习的样本个数至少都是以万为单位的。

其实SGD说那么多,实施起来就一句话,就是将样本逐批逐批进行训练。
二、动量梯度下降法
在深度学习中,梯度下降法往往是不够打的,最基本也要动量梯度法出来才能hold住场子,好了,下面看看为啥要动量梯度下降法呢?这家伙又是个啥呢?
2.1. 为什么需要动量梯度下降法
我们知道,梯度下降法有个缺点,就是完全没有跳出局部最优的能力。
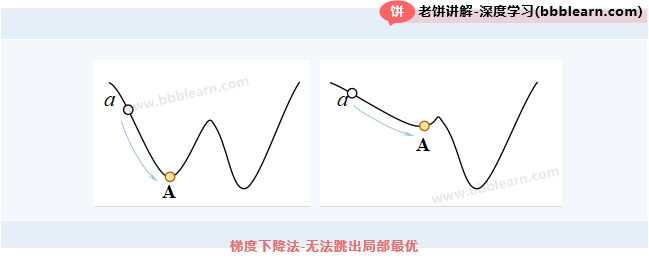
如图所示,如果初始化在a点,那么就只能找到局部最优值A。左图没什么可惜的,再看右图,右图仅仅是一个小坑,就把梯度下降法给坑住了!这可亏大了!于是,动量梯度下降法出场了,专治这些小坑小洼。
2.2. 动量梯度下降法-原理与公式
动量梯度下降法的原理很简单,就是模仿石头滚下山时能跳出小坑的原理,为什么石头能跳出小坑呢,因为石头具有速度,当遇到小坑时,由于动量的原因,小坑就困不住石头。不妨看一下动量梯度下降法的效果:
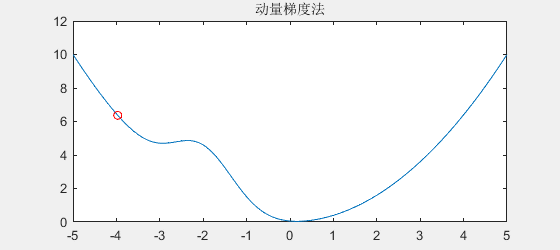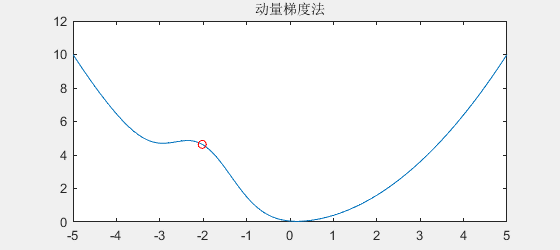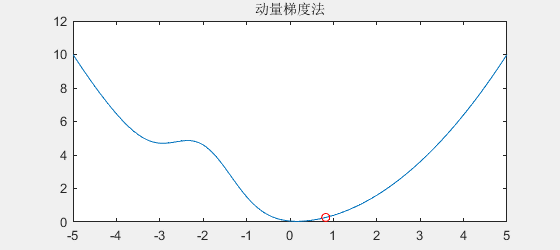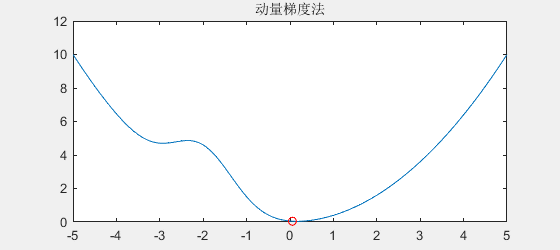
可以看到,动量梯度法的效果就像石头下山一样,小小的坑是拦不住它的。
那么,动量梯度下降法具体是怎么做的呢,它不用梯度直接更新参数,而是引入速度,用梯度来更新速度,再用速度来更新参数,它的更新公式如下:
其中,
:速度
:梯度
:学习率
:动量系数
:阻尼系数
大哥,别慌,它的公式其实很简单的,就是用梯度来更新速度,再用速度来更新参数,较难理解的只是速度的更新公式,其实它也很简单,来来来,详细解读一下它的意义,如下:
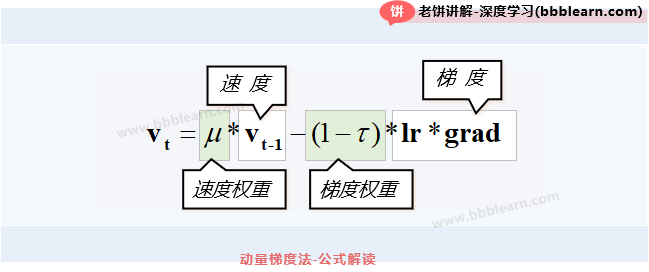
一般来说,动量系数默认与与阻尼系数一样,这时候与的和就为1,也就是如果设为0.3时,那么梯度的权重就是0.7。
三、深度学习中的SGD
3.1. 深度学习-SGD-算法流程
好了,通过上面的学习,差不多就整明白深度学习中的SGD大概是怎么样的了,它就是随机批量、加动量的梯度下降法。大概流程如下:
- 训练N步(epoch):
将样本顺序打乱,并将样本分为M批(Batch)
- 逐批(Batch)样本进行训练:
1. 用当前批样本计算梯度
2. 用梯度更新速度
3. 用速度更新参数
3.2. 深度学习-SGD-意义
好了,梯度下降法一般来说在深度学习中是不够打的,要搞SGD来才行。为啥呢?
先说分批。一方面是分批可以提升训练速度,另一方面,深度学习的数据往往非常大,不分批跑不也不行。
再说说动量梯度法。一方面动量梯度法可以提升训练的速度,因为它顺风时会越滚越快,不像梯度法那样保守。另一方面深度学习的模型复杂,损失函数坑坑洼洼的地方可能比较多,加入动量才能跳出这些小坑小洼。
好了,深度学习中的SGD训练算法大概就是这样了,下节再写个代码来玩玩它吧~!
总结
好了,这一节我们既认识了随机批量法,又认识了动量梯度下降法,简直赚大了。它们是深度学习中最基础的训练方法。很长一段时间都是靠着它来训练,直到后来又出现了其它的训练算法,现在呢,一般都用Adam算法来训练,但SGD仍然是一种基础训练算法。
有的同学又会问Adam算法是什么,别别别,先别急,现在先玩古法烧鸡,等你去开店了再去弄高科技狠活烤鸡法,不然你都无法体验烧鸡的发展历程,而且高科技一直在变,今天是Adam,明天就是Adam-Max了。
 评论
评论
