- 一、深度学习-学前解说
-
二、深度学习-学前热身
-
2.1.环境搭建
-
2.2.从逻辑回归开始吧!
-
2.3.认识一下softmax喽
-
-
三、开始玩MLP啦
-
3.1.开始玩MLP啦
-
3.2.简单玩玩MLP
-
-
四、大型深层MLP
-
4.1.多层大型MLP咋搞
-
4.2.大型MLP如何训练
-
4.3.面向深度学习玩一玩MLP
-
- 五、简单玩玩CNN
- 六、简单玩玩RNN
-
本章结束语
-
7.1.结束语
-
 老饼讲解:一步一步上手深度学习
老饼讲解:一步一步上手深度学习
【代码】训练MLP来识别手写数字
好了,下面我们看看如何使用MLP来实现手写数字识别,在这里我们顺便熟悉一下SGD算法、pytorch的模型、pytorch的优化器等等的使用。
一、MLP实现手写数字识别-代码实现
闲话不多说,直接上代码、看效果,下面再慢慢讲解代码。
MLP实现手写数字识别,具体代码实现如下:
# 本代码用于展示:训练一个MLP实现手写数字识别
# 本代码来自《老饼讲解-深度学习》www.bbblearn.com
import torch
from torch import nn
from torch.utils.data import DataLoader
import torchvision
import numpy as np
#--------------------模型结构----------------------
# 定义神经网络的结构
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.stack=nn.Sequential(
nn.Flatten(), # 对输入进行展平
nn.Linear(28*28, 100),
nn.Tanh(),
nn.Linear(100, 10)
)
def forward(self, x):
y = self.stack(x)
return y
#-----------------------模型训练-----------------
# 训练函数
def train(dataloader,model,optimizer,epochs,goal):
for epoch in range(epochs):
for batch, (x, y) in enumerate(dataloader):
# -----训练模型-----
optimizer.zero_grad() # 将优化器里的参数梯度清空
py = model(x) # 计算模型的预测值
loss = lossFun(py, y) # 计算损失函数值
loss.backward() # 更新参数的梯度
optimizer.step() # 更新参数
acc_rate = calAcc(model,dataloader) # 计算数据集的准确率
print(f"第{epoch}步,准确率:",acc_rate) # 打印准确率
if(acc_rate>=goal): # 检查退出条件
break
# 计算数据集的准确率
def calAcc(model,dataLoader):
py = np.empty(0) # 初始化预测结果
y = np.empty(0) # 初始化真实结果
for batch, (imgs, labels) in enumerate(dataLoader): # 逐批预测
cur_py = model(imgs) # 计算网络的输出
cur_py = torch.argmax(cur_py,axis=1) # 将最大者作为预测结果
py = np.hstack((py,cur_py.detach().cpu().numpy())) # 记录本批预测的y
y = np.hstack((y,labels)) # 记录本批真实的y
acc_rate = sum(y==py)/len(y) # 计算测试样本的准确率
return acc_rate
#--------------主流程脚本----------------------
#-------------------加载数据------------------------
train_data = torchvision.datasets.MNIST(
root = 'D:\\pytorch\\data' # 路径有,就从路径中加载,否则联网获取
,download = True # 是否下载,选为True,就下载到root下面
,train = True # 获取训练数据
,transform = torchvision.transforms.ToTensor() # 转换为tensor数据
,target_transform= None)
test_data = torchvision.datasets.MNIST(
root = 'D:\\pytorch\\data' # 路径有,就从路径中加载,否则联网获取
,download = True # 是否下载,选为True,就下载到root下面
,train = False # 获取测试数据
,transform = torchvision.transforms.ToTensor() # 转换为tensor数据
,target_transform= None)
#-------------------模型训练--------------------------------
trainLoader = DataLoader(train_data, batch_size=100, shuffle=True) # 将训练数据装载到DataLoader
testLoader = DataLoader(test_data , batch_size=100) # 将测试数据装载到DataLoader
model = MLP() # 初始化模型
lossFun = torch.nn.CrossEntropyLoss() # 定义损失函数为交叉熵损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=0.05,momentum =0.9) # 初始化优化器
train(trainLoader,model,optimizer,1000,0.99) # 训练模型
# -----------模型效果评估---------------------------
print("\n--训练结果--:") # 打印训练结果
train_acc_rate = calAcc(model,trainLoader) # 计算训练数据集的准确率
print("训练数据的准确率:",train_acc_rate) # 打印准确率
test_acc_rate = calAcc(model,testLoader) # 计算测试数据集的准确率
print("测试数据的准确率:",test_acc_rate) # 打印准确率运行结果如下:
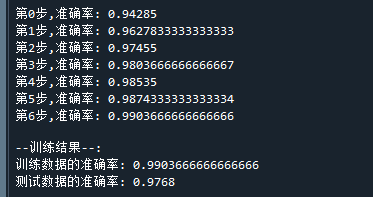
可以看到,经过6步的训练之后 ,训练样本的准确率已经达到99%,而测试数据达到97.6%,效果已经较不错了。说明MLP用于识别手数数字问题是有效的。
二、代码解说
2.1. 模型结构定义

这里我们定义了我们的模型结构,在初始化函数中,我们定义了一个前馈序列,然后在forward函数直接调用前馈序列进行计算就行了。核心内容只在13-18行中定义的前馈序列。
第14行,用nn.Flatten()对输入用展平。因为我们的图片是28*28的矩阵,所以要先把它展平为向量。
第15行,进行线性运算,即wx+b,其中输入为28*28,输出为100。
第16行,进行tanh运算,也就是以tanh作为激活函数。这里我们不用Relu函数,毕竟我们的层数也不多。
第17行,进行线性运算,即wx+b,其中输入为100,输出为10。
可以看到,我们就是定义了一个三层的MLP,其中输入为28*28,隐层为100,输出层为10。这里我们的隐层使用100,是因为输入是图片,图片中的冗余信息较多,所以相对于输入,隐层应大大减少神经元个数。手写数字共10个类别,所以我们的输出个数是10。事实上,我们用于类别识别,输出应该加上softmax,但由于pytorch已经把softmax嵌入到交叉熵损失函数中了,所以这里不再进行softmax,因此,模型输出的意义是"各个类别的判别值"。
2.2.数据加载
好了,先跳到主流程的数据加载部分,如下代码
在这里我们直接使用torchvision为我们提供的写手数字数据集,只需通过torchvision.datasets.MNIST就可以将数据下载回来了。
第54行,root,数据存放的路径。如果路径中有数据,就会直接去路径中加载数据,如果没有,就会联网把数据下载回来,所以第一次运行可能会慢些,第二次本地有数据了,就很快了。
第55行,download,是否下载到本地,True就会下载到root设置的路径中。
第56行,train,是否下载训练数据。为True时,代表下载训练数据,False时代表下载测试数据。
第57行,transform,是每次读取图片时使用的转换函数。
第58行,target_transform,是每次读取图片时类别使用的转换函数。
这里我们分别下载了训练数据与测试数据。
pytorch的torchvision.dataset还提供了许多图片、文本、视频数据集,具体链接地址如下:
👉 图 片 数 据: https://pytorch.org/vision/stable/datasets.html
👉 文 本 数 据: https://pytorch.org/text/stable/datasets.html
👉 视 频 数 据: https://pytorch.org/audio/stable/datasets.html
每个数据下载的入参是不同的,需要自己去看说明。
1.3.训练与结果主流程
好了,下面我们先来简单看看模型训练与训练结果的主流程。
第67行、68行,先将训练、测试数据集装载到DataLoader中进行分批,每批1000个数据,其中,训练数据每次分批前先对数据打乱。
第69行,初始化MLP模型。
第70行,定义训练时使用的损失函数,这里因为是预测类别,所以使用交叉熵损失函数。
第71行,初始化训练模型时使用的优化器,这里使用SGD算法,把模型的参数交给优化器,并设置了学习率、动量系数等。
第72行,调用训练函数对模型进行训练。后面再详细讲具体怎么训练。
最后,在第75-79行,计算与打印模型的训练数据、测试数据的准确率。其中calAcc是在第40行定义的用于计算模型准确率的函数。
1.4. 训练过程详解
好了,下面说说训练函数
第26行,逐步训练。
第27行,每一步对数据进行逐批训练。
模型的训练也是很简单的,先清空梯度(29行),然后计算模型的输出(30行)和损失函数(31行),最后将损失函数进行backward来更新梯度,更新之后就让优化器对参数进行更新。
第34-37行,计算模型的准确率,如果准确率已经达到目标值,就退出训练。其中calAcc是在第40行定义的用于计算模型准确率的函数。在这里我们每一步都全量重新计算准确率,其实是很费性能的,但作为学习,简单点无所谓,反正数据不大。
总结
从这个例子,我们具体的使用了MLP来解决类别预测问题,同时接触了以图片作为输入变量时的处理方法。总的来说如下:
1. 作为类别预测时,MLP的输出层需要用softmax函数。
但实际编程中,只需输出wx+b就可以了,因为softmax已经被pytorch嵌入到了交叉熵损失函数中。
2. 当输入是图片时,可以把二维的图片转换为一维向量,再作为输入。
 评论
评论
