- 一、深度学习-学前解说
-
二、深度学习-学前热身
-
2.1.环境搭建
-
2.2.从逻辑回归开始吧!
-
2.3.认识一下softmax喽
-
-
三、开始玩MLP啦
-
3.1.开始玩MLP啦
-
3.2.简单玩玩MLP
-
-
四、大型深层MLP
-
4.1.多层大型MLP咋搞
-
4.2.大型MLP如何训练
-
4.3.面向深度学习玩一玩MLP
-
- 五、简单玩玩CNN
- 六、简单玩玩RNN
-
本章结束语
-
7.1.结束语
-
 老饼讲解:一步一步上手深度学习
老饼讲解:一步一步上手深度学习
【改进】防止过度拟合--DropOut
好了,玩过深度学习肯定都知道DropOut,不玩过的,可能也听过它,因为它是大型神经网络抵抗过拟合的一种最最最最常用、有效的手段之一,这节我们就来详细说说DropOut是个什么东西,以及如何计算。
一、什么是DropOut
1.1.先说个故事
我们知道,当神经元越多、模型参数越多,那么神经网络的拟合能力就越强,这时候就越容易出现过拟合。而对于深度学习中,往往玩的都是大型神经网络,那肯定就非常容易过拟合了。这时候,工程师们就要祭出DropOut手段了,专治这些大型胖子神经网络的过拟合问题。
好了,以三层MLP为例,如果我们有10000000000000个神经元,那肯定非常容易过拟合了。
所以呢,人太多了,办事很不干净,惹事生非,角里角落的都会去拟合一下。但我又不能炒掉它们,毕竟就需要这么多人才能干这么多的活。

那怎么让它们办事干脆点呢?OK!那训练时每次都随机派10个小兵让它们带上全军队的力量出去锻炼吧!这样力量又足够,人少不生事!由于训练时他们都习惯办事利落了,等全军出战时,自然也就不会婆婆妈妈了。
1.2. DropOut是什么
好了,dropout就是在神经元非常多时,对每个神经元都以概率p进行禁用,不禁用的以1/p倍输出。如下:
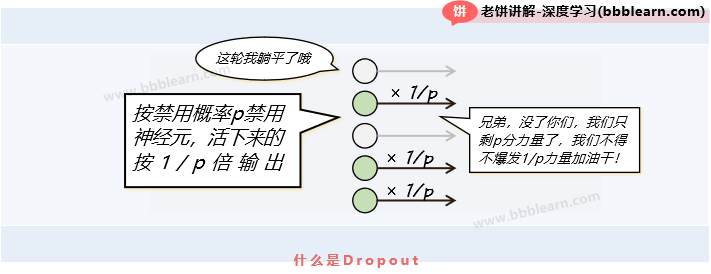
假设现在有一个三层MLP,它的隐层神经元非常多,那么我们对它使用禁用概率p为0.3的DropOut,则会:按概率p=0.3禁用(drop)隐层各个神经元,也就是理论上只有70%的神经元会保留有效状态。然后这70%的神经元以1/0.7=1.428倍进行放大后(这是为了保持全体出动时的大概输出值),再传输给输出层。
刚提出时一般p都代表"禁用(drop)概率",但后来更喜欢用p来表示"保留(keep)概率"。
所以我们改用保留概率一说吧,如果将上面的计算简单后,那就是每个神经元都按keep概率p来保留并放大神经元1/p倍,不保留的则置为0。一时可能反应不了,自己细想一下就明白了。
1.3. DropOut计算举例
设现在MLP的某层有5个神经元,它们的输出值(即激活值)为
现在,对它施以keep概率为0.4的dropout,则我们通过随机数来确定每个神经元是否保留。例如现在对5个神元经生成的随机数为:
由于第1、3、4个随机数大于keep概率,因此第1、3、4个神经元被dropout,而第2、5个神经元被保留,并以倍进行输出。则,经过dropout之后的输出为:
备注:这里的小眼睛代表哈玛达积哦,即元素与元素对应相乘
所以呢,经过dropout之后,最终下层接收到的输入值就是了。
二、再聊dropout
好了,我们再来看看使用dropout时需要注意什么地方,别踩坑了。
2.1. 使用dropout需要注意的地方
1. 仅限于大量神经元使用
如果神经元非常的少,那就不要使用dropout,这东西主要是给大量神经元时使用的。当神经元少的时候,按keep概率p不一定是精准的保留p%神经元,因此放大1/p倍也仍然会导致输出量减少。
有的小伙伴又会说了,哎呀,我修改下放大系数不就行了吗?去去去,核心是这东西就是奔着神经元多时而设计出来,别老想着强行玩好吗。
2. dropout仅限于训练时使用
只是在训练阶段才使用dropout方式,在用dropout训练完模型后,用于预测时,得按全量神经元去预测,也就是预测时不能使用dropout。
dropout仅仅是为了让模型训练得更加健壮些、泛化能力更强些,训练好之后,dropout的任务就完成了。如果预测时还用dropout,那预测结果就不够准确了~锻炼时用7分力,生死拼杀也用7分力,那就别怪对手不留情了。
3. dropout不能用于输出层
从dropout的原理就能知道,它传给下层的值是不太准的,如果把输出层给dropout,那就是瞎来,不知图什么。总的来说,不能把dropout用到输出层。
总结
这里我们简单说了dropout是什么,可能还有些抽象,没事的,在后面我们代码里用几次就感觉具体了,这里只是一些简单讲解,有个概念就好了,无非就是神经元非常多时,就使用一下dropout。
 评论
评论
