- 一、深度学习-学前解说
-
二、深度学习-学前热身
-
2.1.环境搭建
-
2.2.从逻辑回归开始吧!
-
2.3.认识一下softmax喽
-
-
三、开始玩MLP啦
-
3.1.开始玩MLP啦
-
3.2.简单玩玩MLP
-
-
四、大型深层MLP
-
4.1.多层大型MLP咋搞
-
4.2.大型MLP如何训练
-
4.3.面向深度学习玩一玩MLP
-
- 五、简单玩玩CNN
- 六、简单玩玩RNN
-
本章结束语
-
7.1.结束语
-
 老饼讲解:一步一步上手深度学习
老饼讲解:一步一步上手深度学习
【函数】防止梯度消失--ReLu函数
好了,我们知道,MLP只要多层,就很容易梯度爆炸或者梯度消失,导致训练困难。很长一段时间,人们都无所谓,反正三层MLP在隐神经元足够多时就能拟合任意关系了。但到了深度学习就没办法了,深度学习注定有很多层(不然就不叫深度学习了),因此,不得不重新面对这个问题。
好了,第一个被推出来抵挡梯度大爆炸的英雄,它的名字就是--------ReLu激活函数!虽然ReLu是第一个出现的英雄,但直到至今,仍然无人撼动它作为深度学习激活函数的地位!
一、ReLu激活函数
ok,我们一起来看看ReLu激活函数是什么吧~
1.1. ReLu激活函数的图像
ReLu函数的图象如下:
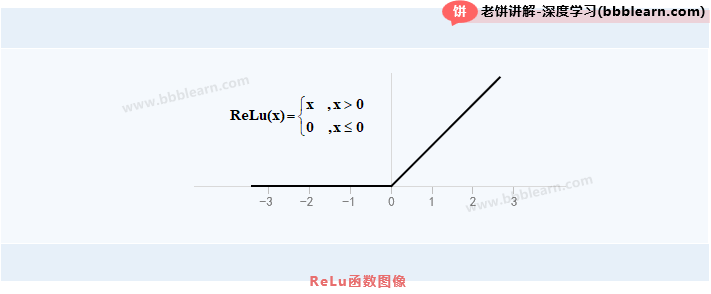
1.2. ReLu激活函数的表达式
ReLu激活函数的表达式如下:
或者
简单来说,ReLu激活函数就是在时为0,在时为自身。
1.2.ReLu激活函数的导数
易知,ReLu激活函数的导数如下:
ReLu激活函数的图像如下:
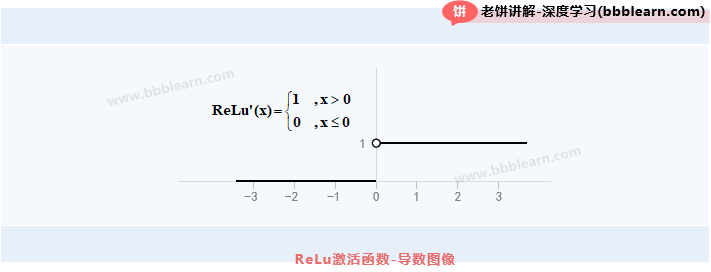
注意:由于ReLu函数本身在0处是不可导的,所以导数公式在0处是人为进行强制定义为0的。
二、如何理解ReLu激活函数
好了,ReLu激活函数为啥要设计成这样呢?而它为什么能缓解梯度爆炸、梯度消失呢?
2.1.ReLu激活函数的设计原理
ReLu激活函数设计成这样到底是个啥意思呢?
原文中表示,常见的生物神经激活中,负值一般是没反应的,即当x<0时激活值为0。另一方面,在生物中也不是所有神经元无时无刻一起干活的,该干活的好好干活,不干活的去睡觉,所以小于0时为0,大于0时为自身,这更贴切生物神经机制。而从数学意义上来说,让激活值变为0,可以令神经网络更好的达到真正的稀疏化。
ReLu激活函数出自2011年的论文《Deep Sparse Rectifier Neural Networks》,论文原本的出发点,并不是要去解决梯度爆炸问题,而是为了让神经网络稀疏化。
2.2.ReLu激活函数为什么work
虽然原文并不是奔着解决梯度爆炸去设计ReLu的,但是后来在实践中却发现,这家伙在深层网络中用得出奇!它的效果比S型函数好太多了!那为啥它能缓解梯度爆炸梯度消失呢?查不到非常严谨的文献,看了一些贴子和个人的理解,大概是这样:
首先,ReLu的特性是,不激活时梯度为0,激活时梯度为1。
当梯度为1时,那么在链式传导中,它不会对梯度有什么影响,也就是它不是梯度爆炸、梯度梯度的帮凶。
当梯度为0时,那么经过它继续传播的所有节点梯度将全是0,也就是它直接让整段罢工躺平、完全没梯度了。与S型函数对比,S型函数死亡的神经元也有微小的梯度,仍然在那诈尸。而ReLu则是让死亡的神经元躺平别动,让活跃的神经元好好干活就行了,死亡神经元只需等待队友救它就行。
总结
这一节我们又接触了ReLu激活函数,深度学习中基本都以它作为激活函数,因为它能缓解梯度爆炸、梯度消失引起的训练困难问题。除了ReLu之外,后来又提出了Leaky ReLU、ELU、PReLU、Swish、Softplus等等激活函数,但没一个能把ReLu打下擂台,所以现在大家还是在用ReLu函数。对于其它激活函数,几乎没什么人用,我就不管了,如果有兴趣的,自己去搜来看吧~!
 评论
评论
