- 一、深度学习-学前解说
-
二、深度学习-学前热身
-
2.1.环境搭建
-
2.2.从逻辑回归开始吧!
-
2.3.认识一下softmax喽
-
-
三、开始玩MLP啦
-
3.1.开始玩MLP啦
-
3.2.简单玩玩MLP
-
-
四、大型深层MLP
-
4.1.多层大型MLP咋搞
-
4.2.大型MLP如何训练
-
4.3.面向深度学习玩一玩MLP
-
- 五、简单玩玩CNN
- 六、简单玩玩RNN
-
本章结束语
-
7.1.结束语
-
 老饼讲解:一步一步上手深度学习
老饼讲解:一步一步上手深度学习
【原理】BP与梯度消失、梯度爆炸
好了,在MLP使用梯度下降等算法进行训练时,会涉及参数的梯度计算,它是MLP的一个核心内容。由于现在我们都不怎么真的动手去计算,而是依赖pytorch这些框架自动梯度了,所以这里我们只是简单的从理论上讲一下它的原理,而不进行详细具体的梯度公式推导。因为原理可以帮助我们理解一些理论方析,但具体的梯度计算不仅非常复杂、烧脑,而且用不上。
在以前,没有深度学习框架,上来就是一大堆的梯度计算公式推导,一个头两个大,简直就是拦路虎,而现在不需要理会这些了,好好享受这一福利吧!好了,让我们开始吧!
一、MLP的梯度计算方法-BP算法
BP算法可以说是神经网络发展的一个里程碑,它给前馈型模型提供了一个梯度计算的方法,是的,这里不仅是MLP的梯度计算,而是所有前馈型模型的一种通用计算方式。最初BP是专为MLP的梯度计算而提出的,它是MLP的特色,所以MLP在那段时间也被称为"BP神经网络",但是深度学习里到处都是前馈型神经网络,BP算法也就不再是MLP的特色了,所以在深度学习中又被重新称回MLP神经网络,而不是BP神经网络(我猜的,没去严谨考证,大家听听就好)。
1.1.前馈模型的数学表述
好了,这里我们直接以前馈模型的来讲解BP算法,一个前馈型模型的结构示图如下:
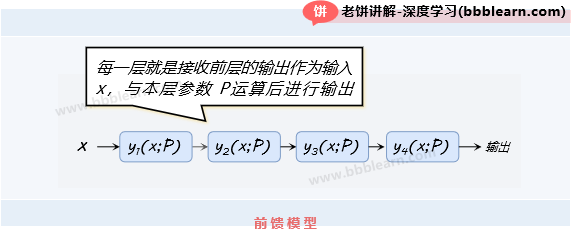
如图,每层接受前层的输入,并通过该层的运算,得到输出,然后将输出传给下一层,如下:
特殊地,对于MLP模型,它每层的运算都为:
那么,最终模型的结果其实就是一个套娃式的复合函数:
如果加上最后损失函数的套娃,那么则是:
上面的数学表述看着有些晕,其实我们就只看具体的某一层(不妨记为k)就好了:
1.2.输出节点的梯度计算
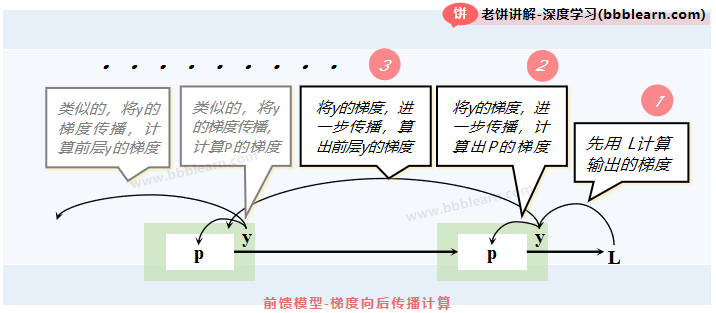
我们暂且抛开参数的梯度不谈,先来说输出节点的梯度,有了它,下面参数的梯度一下就到位了。
好了,根据链式求导法则,第k层的输入(也就是k-1层的输出)梯度为:
好家伙,也就是当知道第k层输出的梯度时,再乘以就是k-1层输出的梯度了。
于是有:
:直接求出
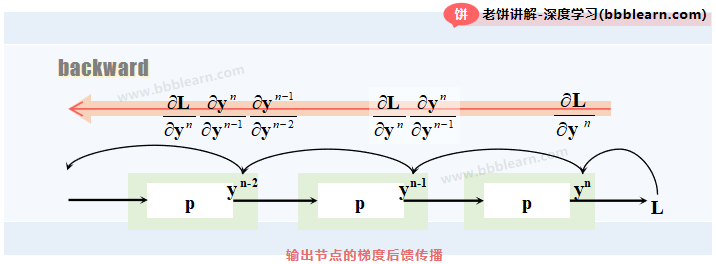
注意,下一层输出的梯度,是前一层输出梯度的基础上再乘以一个哦。因此,只要从最后一层开始逐层后馈,就能计算出所有层的输出梯度了。
补充一下,在计算各层输出节点梯度时,有两个要计算的东西,但它们的计算都是简单的:
1. 最后一层的输出梯度
它就是损失函数对模型输出的梯度,例如L为mse时,就有:
2. 当层输出对前层输出的梯度
由于前层输出就是本层输入,所以它实际就是当层输出对当层输入的梯度,计算起来也很简单。例如MLP,它每一层的运算都是,计算一下它对的梯度就行了。
1.3.参数的梯度计算
好了,在知道了每层的输出梯度,那每层的参数梯度就好计算了。
因为根据链式求导法则,第k层的参数梯度为:
所以,每层的参数梯度只需要计算当前层输出对参数的梯度就可以了。它也是容易计算的,例如MLP,它每一层的运算都是,计算一下它对或的梯度就行了。
1.4. BP算法-小结
总的来说,先最后一层输出的梯度,然后就可以逐层后馈式地计算出每层的输出梯度。同时,在算出当层输出梯度时,就可以算出该层的参数梯度,如下:
其中,知道当前输出梯度时,当层的参数梯度与前层的输出梯度公式分别如下:
,与
好了,我们大概理解一下就好了。
二、梯度爆炸与梯度消失
2.1.梯度信号的传递
好了,从上面可以看到,前馈型模型就是一个链式函数,对参数求导时只需逐层后馈式(反向传播)计算就可以了。也可以理解为,前馈型模型的梯度从最后一层开始逐层向后传播,也曾称为误差后馈传播。
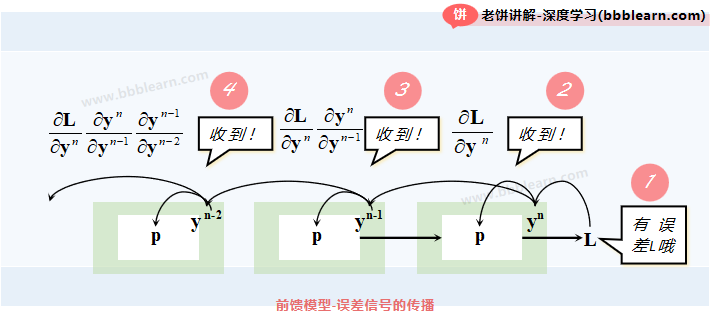
比较形象的理解方式是,样本的预测值(最后一层的输出)与真实值有误差时,说明模型不行,然后最后一层就把这个误差信号告诉前层,前层又告诉前前层,如此如此。哈哈哈哈,这群家伙真会说故事。
2.2.梯度消失和梯度爆炸
现在问题来了,如果模型很多很多很多层,那么梯度层层后向传播,我们光看输出节点梯度的公式:
好家伙,误差信息层层传递,每层都加一点自己的料,到了第k层,误差信息都面目全非了~!而且它们加料时都是累乘,那么如果每一层对前层传播的梯度都<1,即缩小一点点,那么,最终累乘下来梯度趋于0,就梯度消失了。反过来,如果每一层传播梯度都>1,层层传播后,梯度就极大了,也就梯度爆炸了~
当k层的输出节点梯度消失或爆炸时,用它来计算第k层参数的梯度,自然也是梯度消失或爆炸的,因此,不管初始误差信号是什么,如果发生梯度消失或梯度爆炸,k层参数的梯度要么躺平要么过激反应,这都导致训练乱七八糟。
总结
这节我们大概地了解了BP算法,也就是MLP等等前馈模型使用的梯度计算方法。而比较值得注意的是,多层容易引起梯度消失或梯度爆炸,这会使训练困难。
 评论
评论
