- 一、深度学习-学前解说
-
二、深度学习-学前热身
-
2.1.环境搭建
-
2.2.从逻辑回归开始吧!
-
2.3.认识一下softmax喽
-
-
三、开始玩MLP啦
-
3.1.开始玩MLP啦
-
3.2.简单玩玩MLP
-
-
四、大型深层MLP
-
4.1.多层大型MLP咋搞
-
4.2.大型MLP如何训练
-
4.3.面向深度学习玩一玩MLP
-
- 五、简单玩玩CNN
- 六、简单玩玩RNN
-
本章结束语
-
7.1.结束语
-
 老饼讲解:一步一步上手深度学习
老饼讲解:一步一步上手深度学习
【开始】从逻辑回归Sigmoid开始
好了,在我们正式学习深度学习之前,先简单的围绕逻辑回归模型来上手一些基础内容吧!
前言
有机器学习基础的同学,应该已经了解逻辑回归了,事实上,逻辑回归并不属于深度学习的范畴,它与深度学习没太大关系。但由于吴恩达的视频从逻辑回归入手,"逻辑回归"成了许多深度学习同学的通识,为了知识对齐,我们不妨也从逻辑回归模型开始,另一方面,逻辑回归的确包含了许多深度学习的基础知识与概念,从它上手的确是个好方法。
一、逻辑回归模型
好了,什么是逻辑回归模型呢?
逻辑回归模型是一种用于二分类的模型,它输出样本属于1类标签的概率P,逻辑回归的模型数学表述为:
其中,
如果从模型表达式来理解,则部分相当于评估样本属于1类标签的判别量,而sigmoid函数则进一步把这个"量"转换为概率值。sigmoid在机器学习、深度学习中经常用到的一个函数,它的曲线图像如下:
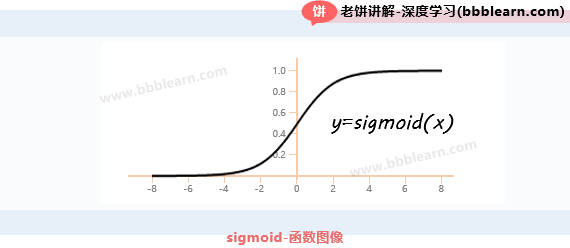
可以看到,sigmoid函数的输入范围是,而它的输出范围为,在x=0时取值为0.5。它的这个特性,很适合用来将量转换为概率。当然,这是从数学性质上的一种简单粗暴理解,也可以从其它更具背景意义来推导它。
所以,归根到底,逻辑回归的判别功能靠的还是线性部分,sigmoid只是将它转为概率。当时,,当时,。因此,也把所确定的平面称为逻辑回归的判别平面。
二、逻辑回归模型的损失函数
2.1. 逻辑回归的交叉熵损失函数
w,b是逻辑回归模型的参数,而训练模型就是希望找到一个w,b,使得模型的预测准确。那逻辑回归在训练时用什么来衡量模型是否准确呢?它使用如下的交叉熵作为损失函数:
其中,m是样本个数,y是样本真实标签,P是模型预测的概率
有些兄弟可能一时不明白上述式子是什么意思,那咱一起来解说解说。
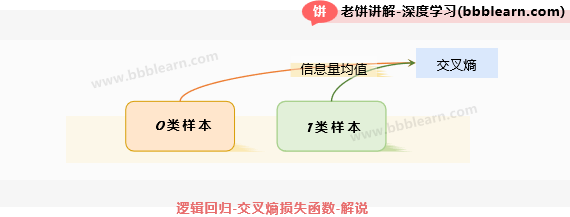
仔细看就会发现它分为两部分:
对于0类样本,模型觉得它属于0类的概率为,所以知道真实标签时获得的信息量为。
对于1类样本,模型觉得它属于1类的概率为,所以知道真实标签时获得的信息量为。
则按模型的认知,将从所有样本中获得的信息量进行平均,就是信息量期望,也就是交叉熵了。
交叉熵越小,说明模型对真实标签的认知越准确,因此,训练模型时,只需令交叉熵最小化就可以了。
2.2. 二分类交叉熵损失函数的风骚表述
事实上,交叉熵损失函数在二分类时还有另一种表述,如下:
当时,中括号内就变为,而时,中括号内就变为,因此,它实际就跟上面的交叉熵损失函数是一样的。但它比较风骚,把上面的交叉熵表述的两个连加号合并为了一个。
这种表述也是经常见到的,遇到了别不认识它哦。
2.3. 逻辑回归损失函数的计算形式
由于逻辑回归损失函数往往会在计算时,产生数值问题,所以往往在编程时采用如下形式:
只需把代入2.2中的形式,再进一步化简就能得到它了。这不是我们学习的重点,这里我们就不展示它的推导过程了~仅仅是因为后面我们写代码时需要用到,避免大家蒙圈~
总结
在这一节,我们讲述了逻辑回归sigmoid模型以及它的交叉熵损失函数的几种形式。
其中,sigmoid函数和交叉熵函数是深度学习中非常常用的内容,sigmoid用于把判别量转换为概率,而交叉熵损失函数则用于评估模型的认识是否准确。至于逻辑回归模型嘛,相信很多机器学习的同学已经非常熟悉它了,而不熟悉的也不用担心,深度学习中一般不怎么使用这个模型~就按上面所说的简单了解一下就可以了~
 评论
评论
