- 一、深度学习-学前解说
-
二、深度学习-学前热身
-
2.1.环境搭建
-
2.2.从逻辑回归开始吧!
-
2.3.认识一下softmax喽
-
-
三、开始玩MLP啦
-
3.1.开始玩MLP啦
-
3.2.简单玩玩MLP
-
-
四、大型深层MLP
-
4.1.多层大型MLP咋搞
-
4.2.大型MLP如何训练
-
4.3.面向深度学习玩一玩MLP
-
- 五、简单玩玩CNN
- 六、简单玩玩RNN
-
本章结束语
-
7.1.结束语
-
 老饼讲解:一步一步上手深度学习
老饼讲解:一步一步上手深度学习
【模型】认识一下-pytorch的模型
从这节开始,我们要开始熟悉使用pytorch来构建模型的方法了。
在这里,我们只要能够依葫芦画瓢地构建一个MLP模型就算很不错了~后面我们再继续模仿其它模型的实现,等我们写得多了,再来详细地说说它的语法到底是怎么回事、然后彻底弄懂它。总的来说,先动手后理解是再好不过好的方式了,这一节我们就先模仿就好了。好了,让我们开始吧!
一、pytorch的前馈模型
MLP是前馈模型的经典,我们这里以MLP模型为例,先学会怎么用pytorch来定义一个MLP模型。
1.1. pytorch前馈模型-代码示例
我们直接上一个三层MLP的代码,然后跟着代码来学。
# 本代码用于展示:用pytorch搭建MLP
# 本代码来自《老饼讲解-深度学习》www.bbblearn.com
import torch
from torch import nn
class MLP(nn.Module): # 定义一个模型,继承nn.Module
def __init__(self,xn,hn,yn): # 模型的初始化函数
super(MLP, self).__init__() # 调用上级初始化
self.stack = nn.Sequential( # 定义一个前馈序列
nn.Linear(xn, hn), # 定义一个线性层
nn.Tanh(), # tanh运算
nn.Linear(hn, yn) # 定义一个线性层
)
def forward(self, x): # 模型的输出
y = self.stack(x) # 计算模型的输出
return y # 返回输出值
model = MLP(2,4,2) # 初始化模型
x = torch.tensor([[3.,2.]]) # 输入数据
y = model(x) # 计算模型的输出
print("模型的输出:",y) # 打印结果运行结果如下:

这就是用pytorch定义了一个2输入、4隐层、2输出的MLP后,模型得到的输出结果。
二.、代码解说
好了,下面解释下代码是怎么回事。
1.1. 模型的定义
好了,我们先来看看模型定义的部分,如下:

第5行,MLP(nn.Module)中的MLP是我们的模型名称,名称可以改任意名称,但nn.Module必须照着写,它代表我们的模型继承了nn.Module类,它需要实现__init__与forward方法,__init__用于模型的初始化,而forward则用于模型的计算,不要急,看下去就会明白了。
第6行是模型初始化时所调用的函数__init__,由于我们构建的是三层MLP,所以我们这里指定了xn,hn,yn三个初始化时需要传入的参数,它们分别代表模型的输入个数、隐节点个数、输出节点个数。
第7行代表调用上级的初始化,照着写就行了,需要注意的是这里的MLP需要我们上面定义的模型名称一致。
第8行用nn.Sequential来定义一个前馈序列,括号里的东西就会按顺序运算。这里我们把它赋值给模型私有(self)变量stack,因为我们后面forward中要调用它,stack只是个变量名称,可以自己随便改。
第9行nn.Linear(xn, hn)代表一个线性运算层,即wx+b,括号里的(xn,hn)代表线性层的输入、输出维度。
第10行nn.Tanh()就是tanh函数了,用它将线性层的输出进行激活。也可以换成nn.ReLU()来玩玩。
第11行就是输出层的线性运算层了。
到了这里,初始化就结束了,主要是定义了一个前馈序列stack,它包含了线性层->tanh->线性层这样的运算。开始说forward了,它代表给模型一个输入后,模型如何进行输出,而之前初始化中定义的东西,就可以在这使用了。
第13行,forward函数的定义,这里我们定义forward函数必须传入一个x。
第14行,直接调用__init__中定义的stack对x计算,即,将x按序列中的线性层->tanh->线性层计算来得到y。
第15行,直接返回结果,没什么好说的。
好了,再整体回顾一下,其实就是继承nn.Module类来定义一个自己的模型,然后初始化部分先定义好forward里要用的东西,再写写forward里具体的计算流程。先依葫芦画瓢就行了,无非就是改改模型的神经元个数、激活函数之类的,后面慢慢就会懂了的,不要急。
1.2.模型的使用
好了,下面再来说说模型的使用。

第16行,初始化一个MLP模型,这里传入了(2,4,2),它就是之前在模型定义的入参:xn,hn,yn。
第17、18、19行,先设置一个x,然后用model(x)来计算模型的输出,然后打印结果。值得说的是,当我们调用model(x)时,模型就会调用forward函数来计算输出,也就是13-15行的内容。
三、模型的参数
上面我们定义了模型,模型里写了具体的运算,但并没有体现出模型的参数在哪。
好了,下面我们说说小白上手时对模型参数的相关疑问。
3.1. 怎么看模型的参数
好了,有的小伙伴就会问,如果要查看模型的参数,怎么办?
其实很简单,用model.parameters()或model.named_parameters()就可以得到模型的参数了。其中parameters()是不带名称的,而named_parameters()是带名称的。
具体示例如下:
print("\n参数列表(不带名称):")
print(list(model.parameters()))
print("\n参数字典(带名称):")
print(dict(model.named_parameters()))运行结果如下: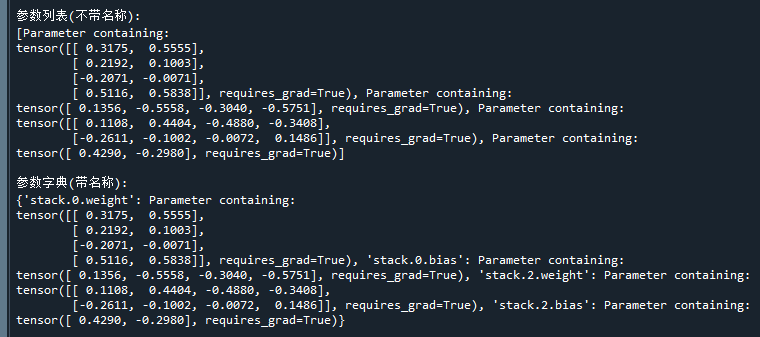
可以看到,这样就能获取到模型中的权重、阈值等参数了。
其中,model.parameters()一般搭配list来强制转化为列表对象,方便使用,而model.named_parameters()则搭配dict来强制转化为字典对象,方便使用。
3.2. 模型参数从何而来
好了,有的小伙伴又疑问了,模型中全程没看到W,B这些参数的定义,怎么model.parameters()就能冒出这些参数来了呢?
其实在我们使用nn.Linear(xn, hn)时,它所返回的对象中就包含了参数了。其实我们也可以自己在模型中定义一些参数,只是现在基本都只是调用pytorch提供给我们的模型就能搭建一般的模型了,所以用不着自己定义参数,这里先不说,以后用到时再说。但简单来说,就是你可以在模型定义时,告诉它哪些是参数,然后模型就会把它管理起来。而nn.Linear(xn, hn)里就做了这样的定义,指明了w,b是模型参数。然后进一步地,它就被我们的模型管理起来了,用model.parameters()时就能打印出这些参数了。
3.3. 如何对模型初始化
如果想对模型参数进行初始化,最简单、原始的方法就是直接把参数拿出来,然后一个一个初始化就行了。这里我们就不演示了,以后在综合的代码中看到就会了。
结束语
这次我们又学会了如何用pytorch来定义模型,又离专业更近一步了。不过这节里我们只是简单的认识它,后面再边学习模型、边在代码中慢慢的更加熟悉、深刻地了解它,在这阶段我们能够依葫芦画瓢就已经很棒了,后面在《Part-2-CNN》中我们再来详细讲解它到底是怎么回事。
 评论
评论
