- 一、深度学习-学前解说
-
二、深度学习-学前热身
-
2.1.环境搭建
-
2.2.从逻辑回归开始吧!
-
2.3.认识一下softmax喽
-
-
三、开始玩MLP啦
-
3.1.开始玩MLP啦
-
3.2.简单玩玩MLP
-
-
四、大型深层MLP
-
4.1.多层大型MLP咋搞
-
4.2.大型MLP如何训练
-
4.3.面向深度学习玩一玩MLP
-
- 五、简单玩玩CNN
- 六、简单玩玩RNN
-
本章结束语
-
7.1.结束语
-
 老饼讲解:一步一步上手深度学习
老饼讲解:一步一步上手深度学习
【开篇】信息量、信息熵与交叉熵
在深度学习中经常会用到交叉熵的概念,它是一个用来衡量认知偏差的指标。
由于交叉熵是由信息量进一步定义出来的,而实际中也会偶尔会用到信息量、信息熵等概念。因此,在这里我们统一花一张文章来把这三个概念从头到尾认识一遍好了,避免之后用到时不认识。
一、信息量是什么
下面我们先来说说信息量,它是信息学中最基本的概念,它最初由香农提出。
1.1. 信息量的定义与公式
一般所说的信息量,都是指香农信息量,即一件事发生的概率为p,那么该事件包含的信息量就为:
不要问为什么就是信息量,它仅仅是信息量的一种常用定义,如果你喜欢,也可以搞个别的信息量定义出来,只是大家喜不喜欢用你的定义又是另一回事了。
为了更形象,我们不妨看看香农信息量的曲线图像:
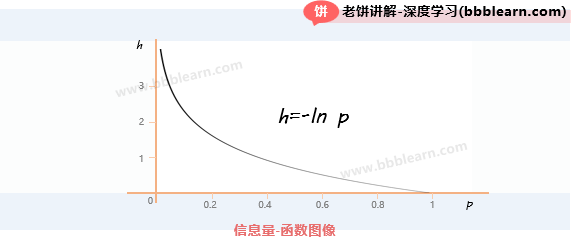
可以看到,信息量是一个与概率p正反比的量,即概率越小,信息量就越大。
1.2. 为什么要这样定义信息量
为什么要把信息量定义为 ?因为这样定义有比较多合理的地方,例如:
1. 概率越小,信息量就大。
这样是比较符合信息量的实际背景的,我们知道的事情越是低概率的,那么我们获得的信息量就越大。如果一件事情人尽皆知,我们在事件中所获得的信息量就越小。例如牛一般都有两个角,现在我知道小李家的牛有两个角,那么我拿着这个事跟谁说他都不会觉得这个信息有什么信息量,因为这太正常了~
2.独立事件的信息量可以相加。
设事件A、B相互独立,则它们一起发生的概率为。而对信息量而言,事件A、B的息量分别为、,它们一起的信息量为,这与事件AB同时发生时的信息量是一致的。可见,这样定义信息量,符合独立事件信息量可相加的特性。
如此等等,所以就将信息量定义为,不要纠结,它就只是一种比较合理的定义。
1.3. 信息量有什么用
信息量其实只是一个与概率直接挂勾的量而已,它的一个重大意义是,给我们提供了一个从信息学角度来看待事件、分析问题的方法。
就像我们还没学概率论时,总喜欢说"可能性",但学了概率论,就喜欢从概率角度来讨论问题,同理的,引入了信息量,玩久了,你可能也喜欢从信息学角度去讨论问题。例如,某一天当你不确定下午下不下雨时,你会抬头看看天来习惯性获取一些"下不下雨的信息",而不是"下不下雨的概率"。
好了,说得越多就越乱,只要进入了深度学习,就会有长期的时间来慢慢习惯信息学对问题的表述与分析。
二、信息熵是什么
好了,开始说信息熵了,熵这一概念来自于热力学,但这里的信息熵跟热力学的熵没啥直接关系。
2.1. 信息熵的定义与公式
信息熵是指信息量期望,当我们知道小李家的牛有2个角这一信息时,我们就会获得一定的信息量。但是,如果现在我们还不知道他家的牛有没有两个角呢?小李说明天才带我去看,那请问,我明天获得信息量的期望是多少?值不值得我跑一趟呢?这很简单,计算一下就行了。

假设牛有一个角的概率为0.001,有两个角的概率为0.999,那么信息量期望为:
OK,这就是信息量期望了,应该能看得明吧?就是"单角、双角"两种情况下所获得的信息量的加权和。
注意,这里我们用了H来表示这个信息量期望,它一般被称为信息熵。更正式的,信息熵的计算公式为:
其实不用记什么公式,记住信息熵就是事件揭晓答案时获得的信息量期望就行了。
2.2. 信息熵有什么用
信息熵可能有很多用途,但在机器学习中最常见的作用就是用来评估事件的混沌性。

当事件的信息熵越大,说明事件具有的信息量期望越多、越不确定,也就是事件本身越混沌。这也就是为什么把"信息量期望"称为"信息熵"了,因为热力学用熵来描述系统的混沌,所以仿照着,就叫它信息熵。
看,用概率就没办法描述事件的不确定性吧~但信息学却可以用"信息熵"这样的指标来描述事件的不确定性。
三、交叉熵是什么
终于说到交叉熵了!没错,玩深度学习可以不认识信息量、信息熵,但不可以不认识交叉熵,不然后面用到的各种交叉熵、KL之类的公式都不知道怎么解释~
3.1. 交叉熵的定义与公式
好了,还是小李带我去看牛,现在我要计算一下这件事能获得多少信息量来决定我明天跟不跟他去。同样地,假设牛有一个角的概率为0.001,有两个角的概率为0.999,现在的问题是,我并不知道这个真实概率,我觉得牛有一个角的概率为0.002,有两个角的概率为0.998,那么,我在这一个认知偏差下,计算的信息量期望为:
可能有的兄弟就看不明了,下面我们详细解释解释一下。
式子就是"单角、双角"两种情况下所获得的信息量的加权和。由于我认为单角的概率为0.002,所以牛是单角时,我获得的信息量为,而单角的真实概率为0.001,所以获得的信息量期望就为。
同理,牛是双角时期望获得的信息量为,两者相加,就是总的信息量期望了。
总的来说,交叉熵就是:在认知概率分布q下看待真实概率分布为p的事件时,所获得的信息量期望。
交叉熵的计算公式为:
交叉熵的公式也是不用强记的,因为它可能有各种形式,而记住定义"在认知分布下得知真相时获得的信息量期望",可以更灵活地使用交叉熵。
3.2. 交叉熵有什么用
交叉熵是在"认知分布"下的信息量期望,可以证明,当"认知分布q"与"真实分布p"一样时,交叉熵达到最小值,当q偏离p越大时,交叉熵越大。因此,交叉熵可以用来评估"认知分布q"是否贴切"真实分布p",也就是评估认知得准不准确。

在机器学习、深度学习进行类别预测时,往往用它来作为损失函数。例如类别预测时,模型给出样本属于各个类别的概率分布,那么可以使用交叉熵来评估模型给出的分布与真实分布的差异。
总结
好了,这节我们主要讲了信息量、信息熵和交叉熵,简单来说,它们的意思分别如下:
1. 信息量是定义出来的,它是一个与概率直接挂勾的量,公式为h = -ln p。
2. 信息熵是知道事件时获得的信息量期望,一般用来描述事件的混沌性。
3. 交叉熵是指基于某个认知下知道事件时获得的信息量期望,一般用来描述认知的准确性。
 评论
评论
