- 一、深度学习-学前解说
-
二、深度学习-学前热身
-
2.1.环境搭建
-
2.2.从逻辑回归开始吧!
-
2.3.认识一下softmax喽
-
-
三、开始玩MLP啦
-
3.1.开始玩MLP啦
-
3.2.简单玩玩MLP
-
-
四、大型深层MLP
-
4.1.多层大型MLP咋搞
-
4.2.大型MLP如何训练
-
4.3.面向深度学习玩一玩MLP
-
- 五、简单玩玩CNN
- 六、简单玩玩RNN
-
本章结束语
-
7.1.结束语
-
 老饼讲解:一步一步上手深度学习
老饼讲解:一步一步上手深度学习
【语法】pytorch数据导入Dataset
玩机器学习时,简单的load一下就能把数据导进来玩了,但是深度学习不行,因为数据大、数据类型多种多样,所以不能load一下就开玩。这节我们详细来说说在pytorch中怎么导入自己的图片数据~其它数据也是类似的。事实上第一次尝试时,会比较费脑费心费神费时间,其实它并不难,只是比较需要耐心。这不,我们这里花一节特地去讲它。
好了,开始吧!
一、先了解Dataset
1.1. Dataset是什么
在pytorch中,由于数据集可能非常大、或者格式不一,所以并不是直接把数据放在一个tensor中,而是提供了Dataset类,用来指定如何去读数据。例如我数据非常大,那我只能把数据放在硬盘中,然后内存里只保留每条数据的名称,当我要某条数据时,再根据名称去硬盘读数据,如此如此,所以Dataset干的就是这个事,拿数据。

进一步,可以认为,数据集DataSet类是pytorch中约定好的、使用时的统一数据"接口",这样不管实际数据是些什么乱七八糟的格式、或者不管存在哪里,都没影响,因为面向使用者的,都是统一格式的DataSet类。
如果我们直接下载pytorch提供的数据,那么得到的就是一个Dataset类,而它里面会写好拿每条数据的逻辑。
1.2.如何写个Dataset导入自己的数据
好了,如果我们现在有一批数据,那么在pytorch中并不会直接用这些数据,而是要先写个DataSet类,然后通过DataSet来间接使用这些数据。
简单点来,假设我们的数据就4张图片,我们把图片和标签保存在D:\pytorch\data\mydata下,如下:
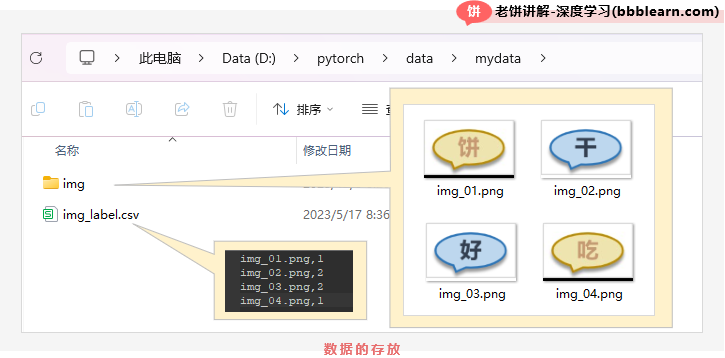
接下来呢,我们就要写个DataSet类了,直接上代码,如下:
# 定义数据集
import os
import pandas as pd
from torchvision.io import read_image
from torch.utils.data import Dataset
# 自定义DataSet数据类
class myDataset(Dataset):
def __init__(self, annotations_file, img_dir, transform = None, target_transform = None):
self.img_labels = pd.read_csv(annotations_file, header = None) # 从CSV中读取图象标签
self.img_dir = img_dir # 存放图片的文件夹
self.transform = transform # 图片的转换函数
self.target_transform = target_transform # 标签的转换函数
def __len__(self):
return len(self.img_labels) # 标签的长度就是样本个数
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0]) # 图片路径
image = read_image(img_path).float() # 读取图片
image = image[0:3,:,:] # 避免4通道图片
label = self.img_labels.iloc[idx, 1] # 读取标签
if self.transform: # 如果有图片的转换函数
image = self.transform(image) # 就对图片进行转换
if self.target_transform: # 如果有标签的转换函数
label = self.target_transform(label) # 就对标签进行转换
return image, label # 返回图片和标签我们把它保存为MyDataset.py,然后使用时呢,则如下:
# 展示数据集的使用
from MyDataset import myDataset
from torchvision import transforms
import matplotlib.pyplot as plt
import torch
img_dir = r'D:\pytorch\data\mydata\img' # 图象文件夹
label_file = r'D:\pytorch\data\mydata\img_label.csv' # 标签文件
data = myDataset(label_file,img_dir) # 初始化数据类
x,y = data[0] # 读取第0条数据的x和y
plt.imshow(transforms.ToPILImage()(x.to(torch.uint8))) # 绘图
plt.show() # 展示画布代码是简单的,就是打印了第0条数据的图片,运行结果如下:

可以看到,在定义了数据集DataSet后,只要初始化了数据集,不管我们的数据存在哪,只要用data[0]马上就能读出我们的第0条数据了,方便得很。
二、代码解说
好了,下面我们逐行来说下数据集DataSet类的代码分别是什么意思。
2.1. 数据类定义
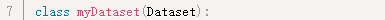
第7行,数据类定义,它需要继承DataSet类,并实现以下三个方法:
__init__:用于初始化。
__len__:用于获取数据长度。
__getitem__:用于获取单个数据。
好了,继续往下看。
2.2. 数据类的初始化
第8-12行,这里是数据类初始化时执行的方法
第8行,__init__函数定义头,在这里定义函数的入参。
第9行,读取类别标签CSV文件,读取完后img_labels就是我们在CSV里所存放的两列:文件名、类别。
第10、11、12行将图片文件夹路径、图片转换函数、标签转换函数作为类的私有变量,供__getitem__使用。
2.3.数据长度函数
好了,下面重写了数据类长度定义函数。
如第15所示,标签的长度就是我们样本个数的长度。
2.4. 重写单个数据获取方法
下面重写了第idx个数据获取的方法。
第18行,先在img_labels中获取第idx个数据的图片名称,再与文件夹路径拼接在一起,就是图片完整路径了。
第19行,用read_image读取图片。
第20行,在img_labels中获取图片的标签。
第21、22行,如果初始化时,传入了图片的转换方法,那就将图片进行转换。同理地,第23、24行,如果初始化时,传入了标签的转换方法,那就将类别标签进行转换。
最后返回图片和标签。
结束语
好了,这节我们认识了pytorch的Dataset,总的来说,就是深度学习的数据是多样化的,所以呢,就要统一写一个Dataset来读取数据,核心就是要实现__getitem__方法,指出索引所对应返回的数据是什么。
 评论
评论
