- 一、深度学习-学前解说
-
二、深度学习-学前热身
-
2.1.环境搭建
-
2.2.从逻辑回归开始吧!
-
2.3.认识一下softmax喽
-
-
三、开始玩MLP啦
-
3.1.开始玩MLP啦
-
3.2.简单玩玩MLP
-
-
四、大型深层MLP
-
4.1.多层大型MLP咋搞
-
4.2.大型MLP如何训练
-
4.3.面向深度学习玩一玩MLP
-
- 五、简单玩玩CNN
- 六、简单玩玩RNN
-
本章结束语
-
7.1.结束语
-
 老饼讲解:一步一步上手深度学习
老饼讲解:一步一步上手深度学习
【原理】多类别预测-softmax回归
好了,我们都知道,在二分类时,可以用sigmoid来把"属于1类的判别量"转换为概率。现在问题来了,如果做多分类时,应该怎么把各个类别的判别量转换为概率呢?这个sigmoid可搞不定了~这就得它大佬--softmax出场了!
我们一如继往,让softmax函数伴随着softmax回归模型出场!掌声欢迎!
一、softmax回归
下面我们就来讲讲softmax模型是如何解决多类别预测问题的。
1.1. softmax回归的模型表达式
softmax回归一般被认为是逻辑回归的扩展,它用于多类别预测。
softmax回归模型的拓扑结构图如下:
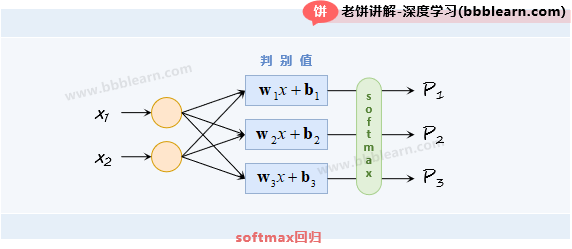
如图所示,softmax回归先通过来得到样本属于第个类别的判别值,然后再通过softmax函数将各类的判别值转换为判别概率。softmax回归的具体模型数学表达式如下:
其中,
1.2. softmax回归的计算例子
下面来个具体的例子,设有2个输入,然后判别属于类别1、2、3的哪一个。
设:
这里(W的第i行)、分别代表第i个类别的判别权重和阈值
则,各类别的判别值如下:
进一步地,用softmax来将判别值g转换为概率值p,如下:
二、softmax回归的损失函数
softmax回归与逻辑回归一样,使用交叉熵作为损失函数就可以了。
即,softmax回归的损失函数为:
其中,是类别个数,是样本个数
有的同学还不习惯交叉熵,我们继续来解说解说就好了。
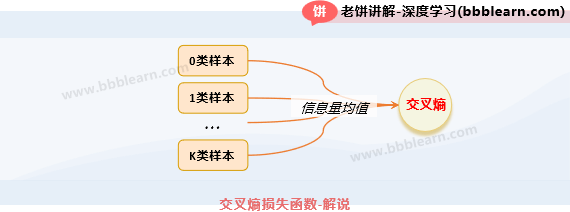
公式中,交叉熵就是所有类别的信息量均值。对于第k类的样本,模型预测它属于第k类的概率为,因此,知道第i个样本的真实标签时,获得的信息量为,第k类样本的总信息量为:,进一步地,所有类别之和(即所有样本)的信息量为:,最后,求平均就是信息量期望(也就是交叉熵)了。
三、 one-hot编码
3.1. 初识什么是one-hot编码
在softmax回归中,我们可以看到,一个样本属于各个类别的判别值用判别向量Z表示,概率则用概率向量P来表示。对应地,一个样本属于各个类别的标签,则用标签向量来表示,如下:
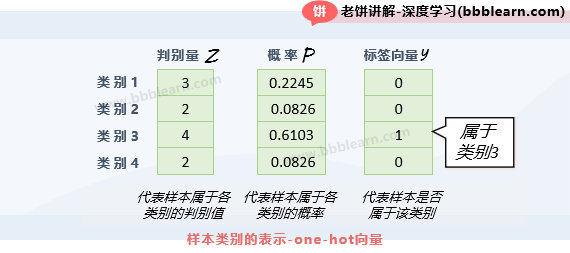
可以看到,它就是样本属于哪个类别,哪个元素就为1,其余为0。这种只有一个元素为1的表示方法,就称为one-hot编码。
3.2. 什么时候用one-hot编码
one-hot编码并不只应用于类别的表示,事实上,在机器学习中,所有枚举变量一般都会转为为one-hot向量来表示。例如性别变量,它有三个枚举值:男、女、其它,则用one-hot向量表示时,取值男、女、其它时,分别表示为[1,0,0],[0,1,0],[0,0,1]。
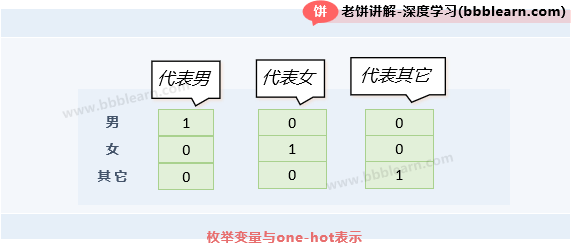
有的乡亲父老会问,为什么不用1,2,3这样的序号来表示男、女、其它,而要用one-hot向量?这是因为 1,2,3这样的序号之间是有大小关系的,3明显与2更近、与1更远,所以序号表示法不能满足枚举值之间的平等关系。
总的来说,为了让枚举变量合理的数值化,一般就会把它转换为one-hot编码。
总结
好的,这节我们又玩上了softmax回归,认识了softmax函数、one-hot编码、交叉熵损失函数等等,具体如下:
1. softmax函数:用于把判别向量转换为概率向量。
2. one-hot编码:用于把枚举值(例如类别标签)进行数值化。
3. 交叉熵损失函数:它就是所有样本的信息量均值,一般按类别进行计算。
 评论
评论
