- 一、深度学习-学前解说
-
二、深度学习-学前热身
-
2.1.环境搭建
-
2.2.从逻辑回归开始吧!
-
2.3.认识一下softmax喽
-
-
三、开始玩MLP啦
-
3.1.开始玩MLP啦
-
3.2.简单玩玩MLP
-
-
四、大型深层MLP
-
4.1.多层大型MLP咋搞
-
4.2.大型MLP如何训练
-
4.3.面向深度学习玩一玩MLP
-
- 五、简单玩玩CNN
- 六、简单玩玩RNN
-
本章结束语
-
7.1.结束语
-
 老饼讲解:一步一步上手深度学习
老饼讲解:一步一步上手深度学习
【训练】先认识一下梯度下降算法
好了,上节我们说到逻辑回归模型,它需要使用算法进行训练来求得使交叉熵最小化的参数w,b。
那怎么训练呢?比较朴素的方法就是使用梯度下降算法,这节我们先来认识一下梯度下降算法是什么。
一、什么是梯度下降算法
1.1.梯度下降算法的原理
梯度下降算法是机器学习中最基本的训练算法,它的原理如下:
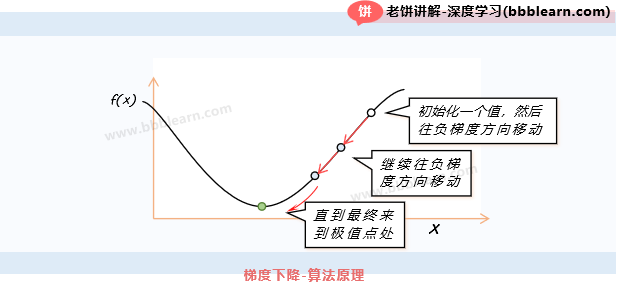
如图所示,它先随便初始化x,然后将参数不断往目标函数f(x)的负梯度调整,直到达到极值处,就终止训练。
1. 为啥要往负梯度调整呢?
负梯度就是令函数下降最快的方法,所以它往负梯度方向调整,这样做的好处是,只要调整步长足够小,目标函数就一定会下降,且负梯度是下降最快的方向。
2. 调整的步长
调整的步长一般由学习率来控制,即:
其中,是学习率,是梯度
学习率过大,可能会导致目标函数没有下降,因为梯度只能保证瞬时下降。而学习率过小,则会令学习过于缓慢。一般来说,学习率lr设为0.1、0.01或其它值,由具体问题具体决定。
3. 如何判断到达极值点了呢?
一般用梯度来判断是否到达极值点附近,因为在极值处的梯度为0,所以如果梯度很小就说明来到极值点附近了,此时就终止训练。
1.2. 梯度下降算法的算法流程
根据上面的原理,很容易就整理出梯度下降算法的算法流程
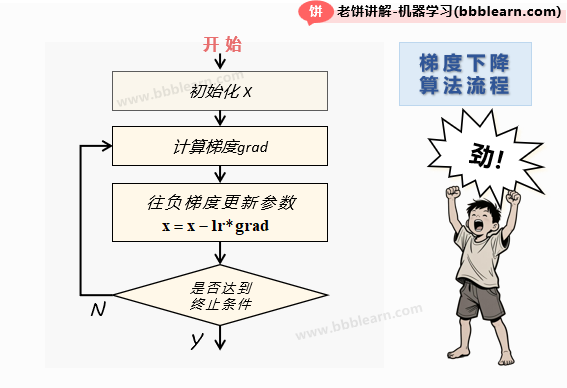
它只有简单的几步:
1. 先初始化参数
2. 计算梯度
3. 往负梯度调整参数
4. 检查是否达到终止条件,否则重复2、3
其中,终止的条件一般设为"达到最大训练次数"和"梯度过小"等等
二、梯度下降算法-应用于逻辑回归
下面我们以逻辑回归模型为例,看看如果用梯度下降法训练逻辑回归模型,应该怎么做。
我们知道,逻辑回归就是希望求一组w,b使得交叉熵损失函数L最小化。因此,使用梯度下降法训练逻辑回归,就只需不断令w,b不断往L的负梯度方向调整就行了,当梯度很小时,就是我们所需要的w,b了。具体如下:
一、超参数预设
先设置好训练超参数,如下:
学习率 :
最大训练步数:
最小梯度 :
二、参数初始化
逻辑回归中的参数就是w和b,因此需要先将它们初始化,这里简单起见,可以采用随机初始化。
1. 将初始化为[0,1]之间的随机数。
2. 将 初始化为[0,1]之间的随机数。
三、循环训练:
1. 计算当前参数梯度
逻辑回归的目标就是令交叉熵损失函数L最小化,其中L为:
因此计算L对于的梯度:
玩深度学习我们不需要具体的梯度公式,因为pytorch会帮我们计算,不能让它失业。
2. 往负梯度方向调整参数
3. 检查是否达到终止条件
如果达到终止条件,就退出训练,终止条件如下:
(1) 当前迭代步数大于最大训练步数。
(2) 梯度过小,即:
四、输出
输出最终的参数
好了,如果用梯度下降算法来训练逻辑回归的流程大概就是这样了,后来我们再用pytorch来按这流程训练一下逻辑回归吧~毕竟,现在我们连pytorch都还不会呢~
三、梯度下降算法的优缺点
好了,敲黑板,敲黑板!重点来了!
梯度下降法是机器学习中,是最基本的一种基于梯度的训练算法。简单是它的优势,但是简单带来的各种粗糙也是它的缺点。
3.1.梯度下降的缺点
下面简单来说一下它的两个较直接的缺点:
1. 没有跳出局部最优的能力
可以看到,梯度下降法就是不断地往负梯度方法调整,并最终达到局部最优点。
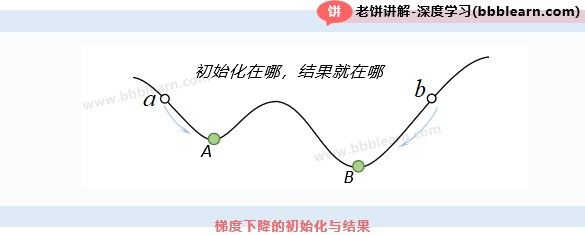
可以知道,它非常受我们初始化的影响,因为它找到的未必是最优值,而仅仅是局部最优值。如图所示,初始化在,最终就会找到局部最优点A,初始化在,最终就会找到局部最优点B。因此,一般可以多训练几次,再选择最优的结果。
2. 极值点附近收敛速度缓慢
梯度下降法就是朝着负梯度方向调整,它调整的步长为lr*grad。初看这没什么毛病,但是实践就会发现,这家伙在极值点附近调整特别慢。
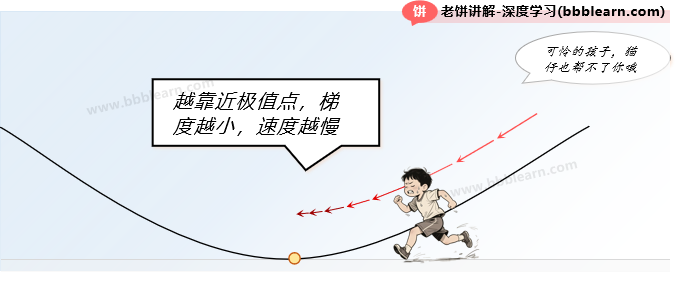
为什么呢?因为在极值点附近梯度grad会很小(梯度就代表着坡度,所以极值点附近的grad很小),那就非常矛盾了,它越靠近极值点,梯度就越小,它调整得就越慢,这样尽管它很努力的去跑,但极值点对它来说却是一个永远达不到梦想,这个追风的少年,风却不属于他。所以一般梯度已经极小时,我们就终止训练啦~
3.2.梯度下降的优点
好了,我们上面数落完梯度下降了,那它有没有优点呢?那肯定是有极极极大大大的优点呀,不然我们也不敢这样数落人家。但这里呢,只说它的一个相比其它训练算法的超级大优点--一定能下降!
对的,它最大的优点就是在学习率足够小的时候一定能保证下降,如果不能下降,那就是到达极值点了~!
所以呢,在其它算法不能下降的时候,就会来求救于它了,大佬大佬,我下降不了啦,你快来帮我下降一下吧!当然,其它算法往往不是光天化日地重新调用梯度下降法,这样太丢脸了,而是偷偷把它内嵌到自己中去使用,这样的白嫖简直爽过嗦螺~!
总结
好了,这节我们简单的认识了梯度下降算法,在所有基于梯度的训练算法中,它的流程是最简单的,原理也是最简单的,实现起来也非常的方便。
梯度下降算法可以说是所有基于梯度的训练算法的鼻祖,但也由于它有各种缺点,所以之后会不断的对它进行改进,以解决各种训练场景出现的困难。
 评论
评论
