- 一、深度学习-学前解说
-
二、深度学习-学前热身
-
2.1.环境搭建
-
2.2.从逻辑回归开始吧!
-
2.3.认识一下softmax喽
-
-
三、开始玩MLP啦
-
3.1.开始玩MLP啦
-
3.2.简单玩玩MLP
-
-
四、大型深层MLP
-
4.1.多层大型MLP咋搞
-
4.2.大型MLP如何训练
-
4.3.面向深度学习玩一玩MLP
-
- 五、简单玩玩CNN
- 六、简单玩玩RNN
-
本章结束语
-
7.1.结束语
-
 老饼讲解:一步一步上手深度学习
老饼讲解:一步一步上手深度学习
【代码】自己写写--SGD训练MLP
好了,这节又来讲点什么呢,就自己按SGD的算法流程,来写个代码训练一个MLP吧!
图啥?没图啥,就是刚开始学,想踏实点,所以自己来实现一下SGD,以后调用pytorch的各种内置训练方法时心里更加踏实。ok,那就让我们开始吧!
一、SGD训练MLP神经网络
SGD的流程之前已经说过了,MLP也玩过了,那这里就用SGD来训练一个MLP吧~
这里也就是为了看下SGD训练MLP,所以我们简单点来,仍然用MLP拟合sin函数的任务来做示例吧!
SGD训练MLP拟合sin函数,具体代码实现如下:
# 本代码用于展示:SGD训练MLP拟合sin函数
# 本代码来自《老饼讲解-深度学习》www.bbblearn.com
import torch
import matplotlib.pyplot as plt
import random
torch.manual_seed(99) # 设定torch的随机种子,使每次结果一样
random.seed(99) # 设定python的随机种子,使每次结果一样
# -----计算网络输出:前馈式计算------
def forward(w1,b1,w2,b2,x):
return w2@torch.tanh(w1@x+b1)+b2
# ----计算损失函数: 使用均方差------
def loss(y,py):
return ((y-py)**2).mean()
# -----样本分批函数-----------------
def data_split(x,y,batch_size):
sample_num = x.shape[1] # 样本个数
batch_num = int(sample_num/batch_size) # 计算批数
idx = list(range(sample_num)) # 样本索引
random.shuffle(idx) # 对索引随机打乱
idx = idx[:batch_num*batch_size] # 只抽取batch_num*batch_size个样本
x_batch = x[:,idx] # 打乱x的顺序
y_batch = y[:,idx] # 打乱y的顺序
x_batch = x_batch.view(batch_num,x_batch.shape[0],batch_size) # 转换x的维度
y_batch = y_batch.view(batch_num,y_batch.shape[0],batch_size) # 转换y的维度
return x_batch,y_batch # 返回分批后的数据
# ------训练数据----------------
x = torch.linspace(-5,5,20).reshape(1,20) # 在[-5,5]之间生成20个数作为x
y = torch.sin(x) # 模型的输出值y
#-----------训练模型------------------------
in_num = x.shape[0] # 输入个数
out_num = y.shape[0] # 输出个数
hn = 4 # 隐节点个数
w1 = torch.randn([hn,in_num],requires_grad=True) # 初始化输入层到隐层的权重w1
b1 = torch.randn([hn,1],requires_grad=True) # 初始化隐层的阈值b1
w2 = torch.randn([out_num,hn],requires_grad=True) # 初始化隐层到输出层的权重w2
b2 = torch.randn([out_num,1],requires_grad=True) # 初始化输出层的阈值b2
lr = 0.01 # 学习率
mu = 0.9 # 动量系数
lamb = 0.0005 # 权重衰减系数
batch_size = 3 # 样本批大小
w1_v = 0 # 初始化w1的速度
b1_v = 0 # 初始化b1的速度
w2_v = 0 # 初始化w2的速度
b2_v = 0 # 初始化b2的速度
for epoch in range(5000): # 训练5000步
# 对样本进行分批,逐批训练
x_batch,y_batch = data_split(x,y,batch_size) # 对样本进行分批
for i in range(x_batch.shape[0]): # 逐批次训练
# 计算梯度
py = forward(w1,b1,w2,b2,x_batch[i]) # 计算网络的输出
L = loss(y_batch[i],py) # 计算损失函数
L.backward() # 用损失函数更新模型参数的梯度
# 更新速度
w1_v = mu*w1_v -lr*(1-mu)*(w1.grad+ lamb*w1) # 更新w1的速度
b1_v = mu*b1_v -lr*(1-mu)*(b1.grad+ lamb*b1) # 更新b1的速度
w2_v = mu*w2_v -lr*(1-mu)*(w2.grad+ lamb*w2) # 更新w2的速度
b2_v = mu*b2_v -lr*(1-mu)*(b2.grad+ lamb*b2) # 更新b2的速度
# 更新参数
w1.data=w1.data+w1_v # 更新模型系数w1
b1.data=b1.data+b1_v # 更新模型系数b1
w2.data=w2.data+w2_v # 更新模型系数w2
b2.data=b2.data+b2_v # 更新模型系数b2
# 清空梯度
w1.grad.zero_() # 清空w1梯度,以便下次backward
b1.grad.zero_() # 清空b1梯度,以便下次backward
w2.grad.zero_() # 清空w2梯度,以便下次backward
b2.grad.zero_() # 清空b2梯度,以便下次backward
# 计算当前的整体损失函数
py = forward(w1,b1,w2,b2,x) # 计算网络的输出
L = loss(y,py) # 计算损失函数
print('第',str(epoch),'轮:',L) # 打印当前损失函数值
if(L.item()<0.005): # 如果误差达到要求
break # 退出训练
px = torch.linspace(-5,5,100).reshape(1,100) # 测试数据,用于绘制网络的拟合曲线
py = forward(w1,b1,w2,b2,px).detach().numpy() # 网络的预测值
plt.scatter(x, y) # 绘制样本
plt.plot(px[0,:],py[0,:]) # 绘制拟合曲线
plt.show() # 展示画布
print('\n训练后的模型参数:') # 打印模型参数
print('w1:',w1) # 打印w1
print('b1:',b1) # 打印b1
print('w2:',w2) # 打印w2
print('b2:',b2) # 打印b2运行结果如下:
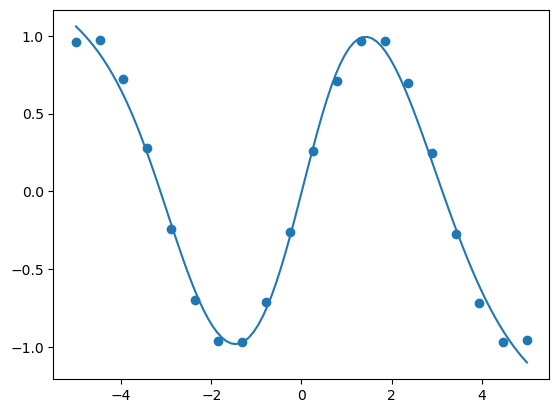
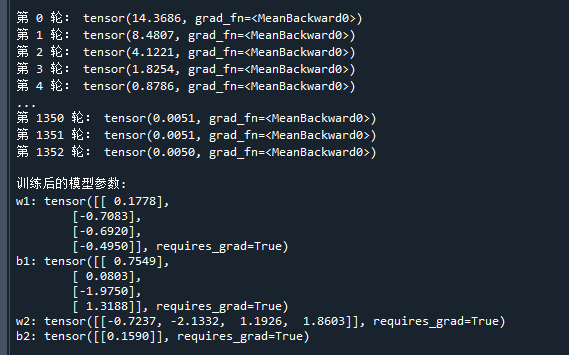
跟预想之中一样,轻轻松松就完成训练了,模型成功地拟合了训练样本点。
但这不是我们的重点,更多的是希望看看SGD算法是如何具体实现的。
二、代码解说
好了, 下面我们详细来解读一下每行代码都干了什么~顺便熟悉一下pytorch的语法。
1.1. 数据加载
这里我们直接从30行开始看,这里是数据加载,生成sin函数的x和y的数据。

1.2. 模型参数初始化
接下来我们简单的初始化模型的参数

第35-37先确定好MLP的输入个数、隐节点个数和输出个数,后面方便使用。
第38-39就是初始化模型参数了,这里我们简单的用正态分布随机数来初始化。
1.3. 超参设置与训练变量初始化
接下来设置训练所用的超参数,以及初始化训练所用到的变量。

第43-46设置了学习率、动量系数、权重衰减系数、批大小等等。
其中,权重衰减系数是为了训练时参数的绝对值不要太大而对参数进行衰减的一个系数,下面使用时再讲解。"批大小"指定了批训练时每批数据的样本个数,由于数据较少,这里设为3个。
第48-51则初始化了各个参数的速度。这是因为我们要用动量梯度法,所以要引入"速度"变量。
1.4. 模型训练
好了,下面看看训练部分的代码
第52行就开始训练了,一共训练5000步。
第54行先从数据中读取出本批数据,其中data_split是在17-28行定义的数据分批函数。返回的x_batch大概长这样:[第一批x,第二批x,...,第n批x],y是类似的。[第一批y,第二批y,...,第n批y]。这里分批我们自己写函数来实现比较麻烦,就不解读了,以后我们会借用pytorch的DataLoader来帮我们对数据进行分批。
第55行就开始按批历遍,逐批数据进行训练。
第57行根据x和参数,计算MLP模型的输出y。forward是我们在第9-10行定义的用于计算模型输出的函数。
第58行计算损失值,其中loss是13-14行定义的计算损失值的函数。
第59行通过backward来更新参数的梯度。
第61至64行用梯度对速度进行更新。这里加入了权重衰减,避免权重过大,进行权重衰减在一定程度上有利于抵抗过拟合、且避免神经元死亡。
第66-69就用速度更新参数了。
第71-74清空梯度方便下次backward。
第76-80:好了,当完成一轮训练时,我们就打印一下当前的损失值是多少,方便观察训练得怎么样了。并检查损失是否已经足够小了,如果足够小,就退出训练。
1.5. 打印训练结果
最后,在81-90行,我们打印模型的训练结果。
第81-85行:利用训练好的模型对样本进行预测,并画出样本点与模型的拟合曲线。
第86-90行:打印模型的参数。
总结
好了,这节又自己实现了SGD训练算法,成就感满满。
通过代码,就更加知道SGD其实就只是这么简单,分批、随机训练,并通过速度来更新参数。
 评论
评论
