- 一、深度学习-学前解说
-
二、深度学习-学前热身
-
2.1.环境搭建
-
2.2.从逻辑回归开始吧!
-
2.3.认识一下softmax喽
-
-
三、开始玩MLP啦
-
3.1.开始玩MLP啦
-
3.2.简单玩玩MLP
-
-
四、大型深层MLP
-
4.1.多层大型MLP咋搞
-
4.2.大型MLP如何训练
-
4.3.面向深度学习玩一玩MLP
-
- 五、简单玩玩CNN
- 六、简单玩玩RNN
-
本章结束语
-
7.1.结束语
-
 老饼讲解:一步一步上手深度学习
老饼讲解:一步一步上手深度学习
【深入】看看CNN神经网络怎么玩
好了,我们都知道,基础CNN用卷积层和池化来提取特征,然后用全连接拟合输出,虽然原理就是这么简单,但对于不同输入的任务,仍然需要自行设计具体的CNN结构,至于具体怎么设计,这就因个人而异了,这里分享我的经验给大家,大家随便看看就好,觉得有道理就借鉴一下,觉得没道理直接忽略就好了。
一、CNN-模型结构
1.1. 基础CNN-结构回顾
我们先来简单回顾一下基础CNN的结构,如下:
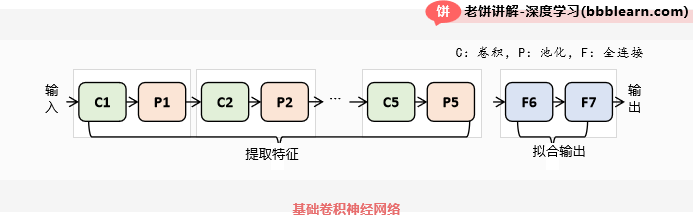
如图所示,卷积神经网络的结构一般由{卷积(relu)+池化层}×N->全连接层(relu)->全连接->softmax构成。
1. 前N层通过卷积和池化不断地将输入图片的信息进行提取与压缩,得到较小的、有效的的图片特征。
2. 使用全连接层拟合图片特征与图片类别的关系,得到图片的类别信息(类别判别值)。
3. 使用softmax函数将类别信息转换为类别的概率。
- 关于基础CNN的说明
1.关于卷积:这里的卷积是带阈值的卷积。
2.关于激活函数:卷积后都带一个Relu激活函数。
添加激活函数的目的是给网络增加非线性功能,由于卷积+池化构成一个完整的信息降维层,所以一般只需添加一个Relu,要么在卷积后Relu、要么在池化后Relu,比较常见的是在卷积后ReLu。
3. 关于全连接层:具有两个(或三个)全连接层,最后一个全连接层没有激活函数
全连接层主要用于特征与输出的拟合,两个全连接层再加上输入,就是经典的三层全连接层。
4. 关于softmax:softmax往往只具形式意义
输出阶段的softmax往往只有形式上的意义,因为只需根据判别值大小,就可确定图片的类别了。
除了最后输出层的全连接层,其余全连接层(神经元较多情况下)一般都使用Dropout(p=0.5)的方式进行训练,这样做可以增强模型的泛化能力。
二、基础CNN-常见设计方法
好了,下面分享一些我所知道的、基础CNN常见的一些设计方法与思路。
2.1. CNN结构设计-卷积的常用设置
先来说说卷积层的设计。卷积层一般将卷积核的大小k设为奇数,然后对输入上下左右各进行(k-1)/2的填充:

对输入进行(k-1)/2的填充,共有两个好处:
1. 在卷积前进行填充,这样对边缘的像素相对公平。
2. 这样的设置可以令输出与输入的Size一致,有利于结构的修改。
2.2. CNN结构设计-池化的常用设置
我们继续看看池化层的设置。
为了避免一次性降维过快而导致信息损失过于严重,一般使用2x2,步幅为2的池化窗口进行池化,因此,在卷积神经网络的结构设计中,往往尽量让第一个池化的输入的高宽都为偶数,以这样的设计,可以使得FeatureMap一直以半倍进行缩小,让卷积神经网络的结构设计更加便利。
这并非是绝对的,只是这种设置是卷积神经网络结构设计中最常用、最基本的核心方法与思路。
2.3. CNN结构设计-特征压缩过程的设计
我们都知道,卷积与池化主要用于特征压缩,一般需要通过反复使用卷积与池化来将特征进行逐步压缩,而要用多少个(卷积+池化)、以及卷积核的Size,则需要根据具体问题具体确定。例如,图片像素特别高,那么卷积核的Size理论上需要更大一些,这样视野相对更大一些。
CNN特征压缩的过程常见的三种方案如下:
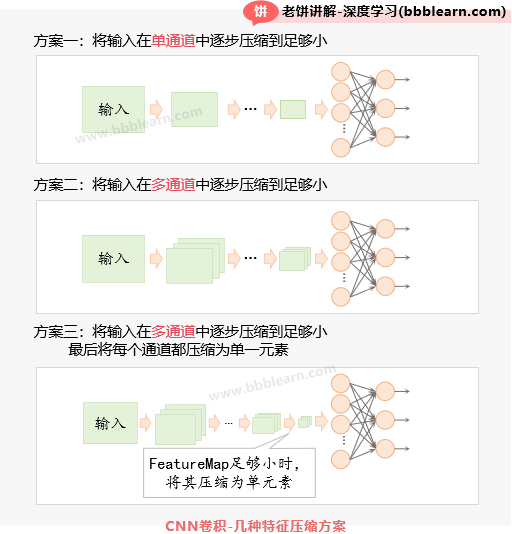
1. 直接使用单通道压缩,直到特征个数足够小。
2. 分解为多通道进行压缩,最后把各个通道都压缩到足够小。
3. 分解为多通道进行压缩,把各个通道都压缩到足够小后,再用一个卷积/池化将所有通道压缩为一个单一特征。
- CNN特征压缩设计的核心思想
事实上,将特征压缩仅仅是这部分的首要目的,它同时肩负"特征提取"的任务,因此,在中间过程不必过于在意是否升维还是降维,而是"如何有利于提取特征"。
总的来说,"卷积+池化"部分只需要保障的以下两点:
1. 参数的数量需要控制在可承受范围内。
2. 最终的输出个数在全连接层的承受范围内。
在整个过程中,FeatureMap一般会越来越小,而通道数则渐进式扩大到一定数量,FeatureMap的减小与通道数的扩大往往是同时进行的,这样可以减小FeatureMap缩小时带来的信息损失。
结束语
这里展示的一些经验,更多是倾向基础CNN的,等我们学习了VGG、ResNet这些模型,就会有更多、更先进的模块和技术供我们使用了,当然,一步一步来,这里我们不妨先玩玩基础CNN,后面再从具体模型中吸取更多技术借鉴。
 评论
评论
