- 机器学习-学前解说
- 第一课:机器学习初探
-
第二课:逻辑回归
-
3.1.认识信息与熵
-
3.2.认识梯度下降
-
3.3.认识逻辑回归
-
-
第三课:决策树
-
4.1.学前解说
-
4.2.CART分类树
-
4.3.其它决策树
-
-
第四课:聚类、分类、降维
-
5.1.朴素贝叶斯分类
-
5.2.k-means聚类
-
5.3.PCA主成分分析
-
- 第五课:建模与实践
-
机器学习入门-总结
-
7.1.总结
-
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【概念】机器学习-信息学的概念
大学时很多人都没接触过信息学,这么好用的东西竟然没学,真是一种遗憾。而在机器学习中必须用到一点点,是的,仅仅是一点点信息学,其实也就只是四个概念而已:信息量、信息熵(H)、交叉熵(CE)、相对熵(KL),这节我们简单的来看看这4个东西,这样在解释一些机器学习中的原理时比较方便,ok,让我们开始吧!
一、信息量-是什么
信息量就是信息的量化,只有量化了信息,才会有信息学,它是打开信息学大门的钥匙,所以一切从信息量开始。
1.1. 信息量的定义
信息量是香农提出的,它用来描述一个事件中所包含的信息的多少,公式定义如下:
这里的p是事件发生的概率,h就是事件的信息量
刚开始接触时,我会在想,为什么事件发生的概率是p,信息量就是呢?这问题困扰了我很久,后来才发现,这家伙只是一种定义,所以没有为什么,就像1+1=2一样,仅仅是一种定义,没有那么多为什么。我们反而要关注的是,为什么要这样定义,这样定义有什么好处。
1.2. 信息量的特性
好了,我们来看看信息量的特点,自然也就了解它这样定义的好处了。
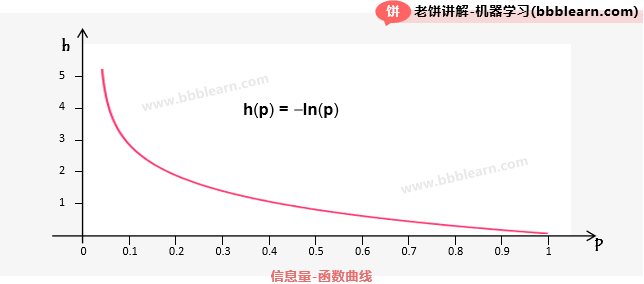
信息量的特性如下:
1. 信息量与事件的概率成反比
从公式可以知道,信息量h与p成反比,这样就与我们现实相符合,概率越小的事情,包含的信息量就越多,概率越大的事情,信息量就越少。例如你告诉我明天的太阳还会升起来,这件事就没什么信息量,因为太阳基本都会升起来,反而是很多瓜里包含的信息量就非常大,因为大家都没想到会是这样。
2. 信息量的可加性
两个独立事件的信息量可以直接相加,证明如下:
这就非常符合常识,吃了一个瓜,再吃一个瓜,两个瓜一起得到的信息量,就是总的信息量。
好了,信息量了解到这里就可以了,其实总的来说,也就是香农提出了一个度量"事件中包含了多少信息"的尺子,而他的这个尺子呢,又符合"与概率成反比、独立事件可相加"的客观事实,所以大家就都跟着他去用这个尺子来度量各种事件的信息量了。
二、信息熵-是什么
有了信息量,就有了更多的衍生概念,信息熵、交叉熵、相对熵都是机器学习中常用的概念,下面我们一个一个来说说它们,都很简单。
2.1. 信息熵是什么
好了,当事件发生时,我们获得的就是信息量,那么事件还没发生时,我们怎么预估我们获得的信息量呢?那当然就是用信息量的期望了,它是我们所要说的信息熵,简单来说,信息熵其实就是信息量的期望。
假设一个事件x有n种可能,取值为时的概率为,那么获得的信息量期望就称为信息熵:
这个公式应该很好理解,当x取为时,获得的信息量为 ,而这种情况的概率为,所以期望获得的信息量就为,最后所有情况相加,就是所能获得的信息量的期望了。
2.2. 为什么叫信息熵
好了,这就是信息熵了,是不是很简单?那明明是信息量的期望,为什么叫信息熵呢?

这是因为它代表了事件的混沌程度,如果一个事件越清晰,那么当我们知道真相时获得的信息量期望(信息熵)也就越少,而一件事情越混沌、越不确定,这时候知道真相时,所获得的信息量期望就越大。而物理学中用熵来度量混沌性,所以信息学中相应地就把事件的混沌性称为信息熵了。
三、交叉熵-是什么
3.1. 交叉熵是什么
那么交叉熵又是什么呢?交叉熵也是信息量的期望,只不过它是建立在我们的认知下、所得到的信息量期望。
假设一个事件x有n种可能,取值为时的概率为,而我们认为取值为时的概率为,那么获得的信息量期望就称为交叉熵:
这个公式也是很好理解的,当取为时,获得的信息量为 ,而这种情况的概率为,所以期望获得的信息量就为,最后所有情况相加,就是所能获得的信息量的期望了。
3.2. 交叉熵用来干什么
大家应该会注意到,交叉熵和信息熵的定义其实很像,刚开始接触时很容易把它们混淆,但事实上,这两个家伙是很不同的两样东西,我们不妨一起来看看不同在哪里。不妨先回顾一下交叉熵与信息熵的定义:
1. 信息熵 :信息熵指的是在客观概率p下,知道真相时所获得的信息量的期望
2. 交叉熵 :交叉熵指的是在认知概率q下,知道真相时所获得的信息量的期望

交叉熵与信息熵看起来很像,但它们又很不同,不同在哪呢?主要是它们的评估对象不同:
信息熵的评估对象主要是事件本身,它用于评估事件本身的混沌程度,不清晰度。
交叉熵的评估对象则是"我们",它用于评估我们对"事件的概率分布"认知的准确程度。
通俗来说,信息熵在描述事件,而交叉熵的焦点在于描述我们,信息熵是描述一件事所带来的震惊程度,而交叉熵则描述这个事件会怎么震惊我们,信息熵是注定的、不可变的,而交叉熵则是可变的,它随着我们认知的提高而降低。
值得注意的是,交叉熵在认知分布q与真实分布p相同时,取得最小值,证明略。
四、相对熵-是什么
好了,终于说到最后一个概念“相对熵”了。相对熵也称为KL散度(Kullback-Leibler divergence)、KL距离等等,那它是个什么东西呢?让我们慢慢道来。
4.1. 相对熵是什么
相对熵其实跟交叉熵差不多是同一个东西,理解了交叉熵就很容易理解相对熵了,我们都知道,交叉熵的意义就是衡量认真分布p与真实分布q的差异,但它的最小取值未必是0,所以相对熵就进一步把交叉熵的最小取值统一拉到0上,也就是:
先看第一个等号,由于认知分布Q与真实分布P相同时,交叉熵取得最小值,所以KL就是把交叉熵减去它的最小值,从而使得它的最小值为0,说到这里,大家应该就理解它为什么叫相对熵了。
4.2. 相对熵用来干什么
事实上,更多时候我们不叫它相对熵,而是叫它KL散度或KL距离,因为它一般用来度量两个分布之间的距离,也就是认知分布Q与真实分布P之间的距离:
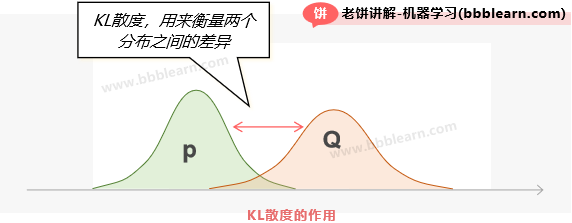
但值得注意的是,KL距离并不是对称的,也就是KL(P||Q)不等于KL(Q||P),所以需要记住它的背景意义就是,度量认知分布Q与真实分布P之间的距离,也就是认知与真实的差距。
总结
说了这么多,其实很简单,就四个概念,如下:
信息量(h) :信息的量化,它打开了信息学的大门。
信息熵(H):知道真相时,所能获得的信息量期望。一般用于评估事件的混沌性。
交叉熵(CE):基于认知分布Q下,知道真相时,所能获得的信息量期望。一般用于评估认知分布Q的准确性。
相对熵(KL):将交叉熵的最小值取为0。一般用于评估认知分布Q与真实分布P的距离。
就是这么几个概念,没必要强记,大概有个印象就可以了,哪怕不理解也没关系,以后遇到多了,自然就会慢慢熟悉了,这里只需要知道有这几个东西就可以了。
 评论
评论
