- 机器学习-学前解说
- 第一课:机器学习初探
-
第二课:逻辑回归
-
3.1.认识信息与熵
-
3.2.认识梯度下降
-
3.3.认识逻辑回归
-
-
第三课:决策树
-
4.1.学前解说
-
4.2.CART分类树
-
4.3.其它决策树
-
-
第四课:聚类、分类、降维
-
5.1.朴素贝叶斯分类
-
5.2.k-means聚类
-
5.3.PCA主成分分析
-
- 第五课:建模与实践
-
机器学习入门-总结
-
7.1.总结
-
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【原理】梯度下降算法-原理解说
前面我们说过了,模型的求解往往没办法用数学的方法来得到精确解,所以就有了许多的优化算法,来寻找目标函数的最优值,而梯度下降算法就是机器学习中最基本、最常见的优化算法,这节我们就来学习一下梯度下降算法。
一、梯度下降算法
梯度下降算法就是一种优化算法,也就是如何我们想找出x取何值时,能令目标函数最小化,那这时候就可以用梯度下降算法来干这事了,下面就让我们来看看它是怎么干的吧。
1.1. 什么是梯度下降算法
好了,梯度下降算法是怎么找到函数的最小解的呢?其实它不是一步到位的,它是先初始化一个解,然后再逐步往负梯度方向迭代,然后慢慢的就找到了函数的最小值:
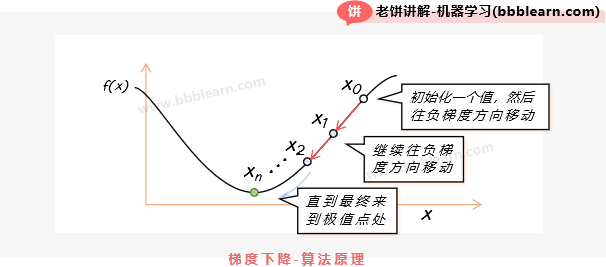
如图所示,梯度下降算法先取一个初始值,然后进行迭代,每次都往梯度的反方向调整它,直到梯度很小时就退出训练,因为梯度很小时,就代表已经很平缓了,也就意味着可能达到局部最低点了。
有的同学可能忘记梯度是什么了,其实梯度就是导数,在一元函数中称为导数,在多元函数就称为梯度。
1.3. 梯度下降-算法流程
好了,我们正式的来看一下梯度下降算法的算法流程,直接上图:
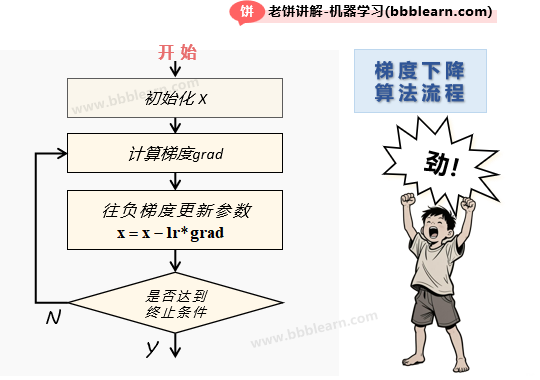
梯度下降法算的流程其实只有简单的几步:
1. 先初始化参数
2. 计算梯度
3. 往负梯度调整参数
其中,lr是学习率,代表调整的步长
4. 检查是否达到终止条件,否则重复2、3
终止的条件一般设为"达到最大训练次数"和"梯度过小"。
有同学可能会问lr是什么,lr是学习率(learning rate),它用于控制调整的步长,一般设为0.1或0.01。
二、梯度下降法-进一步理解
梯度下降算法是简单的,但我们不妨加深一点对它的理解。
2.1. 为什么要往负梯度方向调整?
为什么梯度下降算法每次都要往负梯度方向调整呢?
在一元函数中,负梯度就是导数的反方向,在多元函数中,负梯度就是各个变量偏导数的反方向:
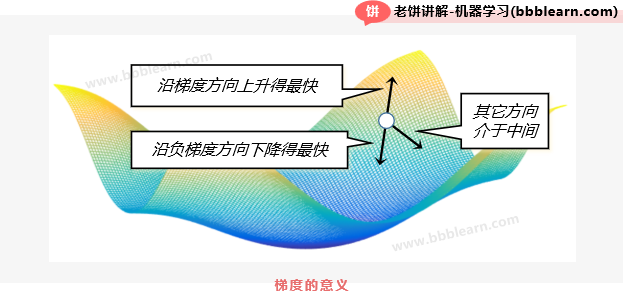
如图,可以看到,梯度是函数瞬时上升最快的方向,而负梯度呢,就是函数瞬时下降最快的方向了,所以往负梯度方向调整,只要步长足够小,就能保证目标函数一定能下降,而且是下降最快的方向,也正因为这样,梯度下降算法往往也称为最速下降算法。
2.2. 关于初始化
事实上,梯度下降法对初始值是非常敏感的,我们先来上个图:
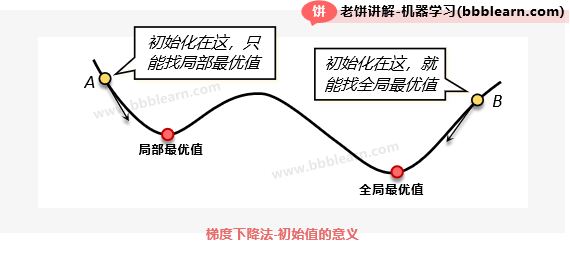
如图所示,如果初始化在点A,那么最终能找到的就是局部最优值,而初始化在点B,最终就会找到全局最优值。总的来说,梯度下降法只能找到离初始值最近的局部极小值,如果初始化不好,找到的结果也不好。所以在用梯度下降法时,往往会采用随机初始化,然后多试几次,看看哪次的结果最好。
2.3. 梯度下降法的学习率
梯度下降算法设置学习率的目的是为了保证按负梯度方向调整一定能下降,由于负梯度方向能下降是瞬时的,如果调整步长过大,则不一定能保证函数能下降:

因此,梯度下降法引入了学习率lr(learn rate),保障调整步长足够小,使得目标函数能下降:
即通过学习率控制调整的步长,以保障梯度下降算法能持续令目标函数下降,。
梯度下降算法的学习率一般设为0.1或0.01,具体问题具体设定,但可以参考这个数值。
总结
梯度下降算法简单来说,就是先初始化一个值,然后再不断往负梯度方向调整就行了,就是这么的朴素无华,下一节我们再手算一遍梯度下降算法就会非常具体和清晰了,这节大概了解就可以了。
 评论
评论
