- 机器学习-学前解说
- 第一课:机器学习初探
-
第二课:逻辑回归
-
3.1.认识信息与熵
-
3.2.认识梯度下降
-
3.3.认识逻辑回归
-
-
第三课:决策树
-
4.1.学前解说
-
4.2.CART分类树
-
4.3.其它决策树
-
-
第四课:聚类、分类、降维
-
5.1.朴素贝叶斯分类
-
5.2.k-means聚类
-
5.3.PCA主成分分析
-
- 第五课:建模与实践
-
机器学习入门-总结
-
7.1.总结
-
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【建模】建模步骤-模型的三要素
好了,经过上节的探索,我们已经有一点点知道机器学习在干什么,以及怎么干的啦。那么我们本节就来正式的归纳一下,建模的步骤,以及模型的要素。
一、机器学习-建模的三个步骤
好了,从上节的例子,我们已经知道,建模大概就三个步骤:数据处理、建模、效果评估,下面我们就来详细正式地说说它们。

1.1. 数据处理
数据处理其实是一个很笼统的说法,但它的目标很明确,就是把数据处理得规规整整、干干净净。反正数据处理就是在数据上进行的一系列工作,包括我们之前说的EDA、包括数据清洗等。例如拿到数据,那么我们就要EDA一下,看看数据长什么样,然后呢,如果发现数据有些缺失值,我们可能就要对缺失值进行填充,又或者我们发现有些数据明显是错误的,那么我们就要对这些数据纠正或删除等等。
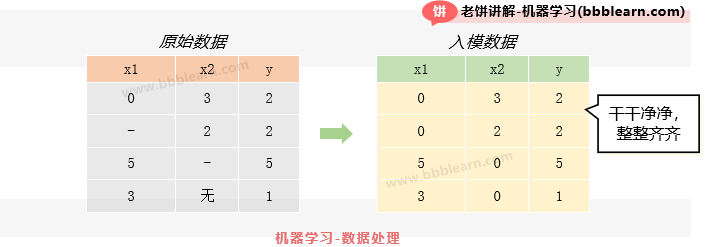
反正最后呢,就是把数据处理的规规整整的,有多少个变量、每个变量有哪些数值等等,很多时候,数据处理都是靠主观能力性的去处理,当然网上也有一套说法,说可以如何如何处理数据等等,大家可以进行参考,但我觉得,这东西,自己觉得应该怎么处理,就怎么处理就好了,没必要那么死板,难道看到数据错误,还不会自己去改一下或删一下吗?数据处理从来不是为了处理而处理,而是实践中需要这样处理,就自然会去处理。
1.2. 模型建立
建模一般是调用软件包中已有的模型,在我们确定了使用哪个模型之后,就把数据投进去训练就可以了,软件包会根据训练数据给出最终的模型,是个很简单的过程。如果要用多个模型进行综合使用,那也是多写几句代码,也不是一个很复杂的过程。当然,也可以自己整个模型,这种情况相对较少,这就要下点功夫了。

建模时呢,会有一些模型参数、或者训练超参数,就需要自己去根据模型特性、数据特性,去主观能力性的设置、尝试一下,当然,也会有一些方法来调参,这就是后话了,但更多时候,就是自己基于对模型、数据的理解,然后手动设一下,调一下。
1.3. 模型评估
模型评估用于评估建模的效果,可以使用一个指标,也可以用多个指标,至于用什么指标,就具体问题,具体确定,如果是私人问题,可能自己随便定一个,合理就可以,如果不是私人问题,就要找一个业内公认的指标了,这都是非常简单的事。
二、机器学习-模型的三个要素
好了,下面我们再来说说模型是怎么回事,通过上节的小例,我们可以看到,一个模型主要有三个重要部分:模型、损失函数和模型求解。

2.1. 模型表达式
模型表达式确定了要用什么样的结构去拟合数据点,
例如在小例中我们用的是直线:
模型确定了我们模型的基本性质和特点,例如,线性模型,它就是一条直线(或平面、超平面),如果x和y是条抛物线,那我们用线性模型就拟合不出来了,正因为如此,我们才需要不同的模型,对不同的业务,选择不同的模型。
2.2. 损失函数
损失函数也叫代价函数,损失函数用于说明我们采用某组w,b时,所要耗费的代价、损失。
在小例中我们的损失就是预测精度(误差)的损失:
损失函数指定了我们的求解目标,损失函数不一定等于评估函数,对同一个模型,一千个问题可以有一千种评估函数,因为评估函数只用于评估,不涉及其它,而损失函数则不同,它既要引导我们获得合理的解,又要考虑求解的难度,由于损失函数与求解高度绑定,一般来说,往往无法做到100%与具体问题的真实合理需求吻合,所以只要对一般问题,它是合理有效的就可以了。
2.3. 模型求解
模型中预留一些待定参数(这里是w和b),损失函数给我们指明了我们想要的参数是什么,而模型求解,则是根据损失函数,解出最符合我们要求的参数。模型求解也称为模型训练,随着模型越来越复杂,我们的求解过程、求解方法也会越来越复杂,所以模型求解基本都是一个模型最复杂的内容。
学习一个模型,主要就抓住模型的三要素,往往模型公式一看、背景意义一理解、损失函数看一看,十分钟不到就到手了,但复杂的模型有更复杂的求解方法,学习模型最耗时间的是模型的求解。
总结
总的来说,建模就三步:数据处理、构建模型、评估模型。而平时就要多去学习不同的模型,一个模型主要有三部分:模型结构、损失函数、模型求解,把这三个东西弄明,基本一个模型就到手了。
 评论
评论
