- 机器学习-学前解说
- 第一课:机器学习初探
-
第二课:逻辑回归
-
3.1.认识信息与熵
-
3.2.认识梯度下降
-
3.3.认识逻辑回归
-
-
第三课:决策树
-
4.1.学前解说
-
4.2.CART分类树
-
4.3.其它决策树
-
-
第四课:聚类、分类、降维
-
5.1.朴素贝叶斯分类
-
5.2.k-means聚类
-
5.3.PCA主成分分析
-
- 第五课:建模与实践
-
机器学习入门-总结
-
7.1.总结
-
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【代码】逻辑回归模型-实现代码
前面我们已经学习了逻辑回归模型了,这一节我们就来看看如何实现逻辑回归模型,一方面是为了将梯度下降法学以致用,另一方面同时学习逻辑回归模型,一举两得,着数过中彩票,马上开始!
一、逻辑回归例子-数据与思路
1.1. 逻辑回归-数据
我们以乳腺癌数据(breast cancer)为例,它共569组数据,如下:
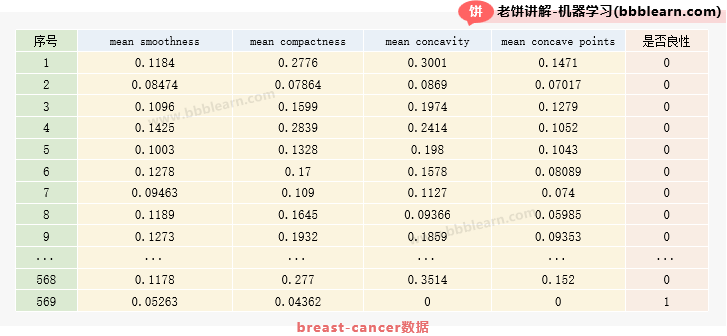
特征:平均平滑度、平均紧凑度、平均凹面、平均凹点,类别:0-恶性、1-良性
原数据中有30个特征,这里作为学习,我们这里只选4个,然后用这4个特征来预测是恶性还是良性。下面我们可以通过数据,训练一个逻辑回归,用于预测乳腺癌类别。
1.2. 逻辑回归-建模思路
不妨让我们先来捋一捋整体建模思路,如下:
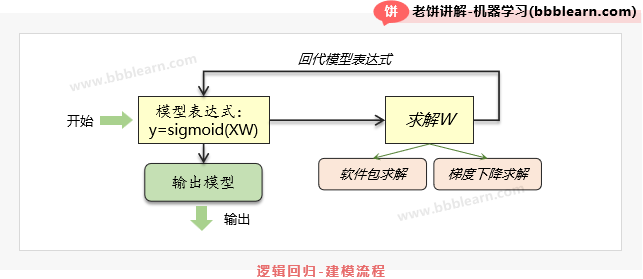
1、确定模型
在本实例中,我们假设X和Y符合逻辑回归模型,则有:
2、逻辑回归模型求解
用梯度下降法求解逻辑回归损失函数中的W,也就是先初始化一个W,然后不断按负梯度方向调整。
其中,梯度公式为:
3、将参数回代逻辑回归模型
将上述求得的W回代模型表达式即可得到最终的模型
二、逻辑回归例子-代码实现
逻辑回归模型的训练可以使用梯度下降算法,算法流程图如下:
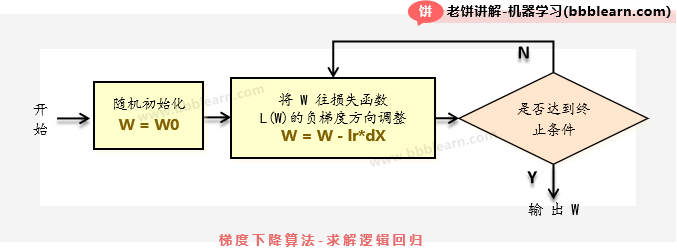
好了,按照上面的流程编写python代码就可以了,如下:
"""
本代码展示梯度下降求解逻辑回归的python代码实现
本代码来自《老饼讲解-机器学习》www.bbblearn.com
"""
from sklearn.datasets import load_breast_cancer
import numpy as np
#----数据加载------
data = load_breast_cancer() # 加载breast_cancer数据
X = data.data[:,4:8] # 作为示例,只使用4个变量来建模
y = data.target # 类别标签
xt = np.insert(X, X.shape[1], 1, axis=1) # 给X增加一列,作为阈值
#-----梯度下降求解w---------------
np.random.seed(888) # 设定随机种子,以确保每次程序结果一次
w = np.random.rand(xt.shape[1]) # 初始化权重
for i in range(10000): # 逐步训练权重
p = 1/(1+np.exp(-xt@w)) # 计算p
w = w - 0.01*(xt.T@(p-y)) # 往负梯度方向更新w
p = 1/(1+np.exp(-xt@w)) # 最终的预测结果
print("参数w:"+str(w)) # 打印参数代码运行结果如下:

将w回代模型,可以得到最终的模型如下:
进一步,我们对p值分布,统计各段中0,1标签的个数,如下:
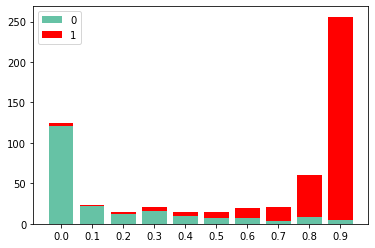
从图中可以看到,p值越高,属于1类别的就越多,这说明模型对样本已有较好的区分度。
事实上,逻辑回归模型一般用AUC或KS作为评估指标,后面再接触,这里就先不展开了。
三、逻辑回归算法实现-调用sklearn
在实际中我们一般都会直接调用sklearn来完成逻辑回归模型的训练,下面我们就来看看在sklearn中怎么训练逻辑回归模型,具体代码实现如下:
"""
本代码展示在python中调用sklearn来训练逻辑回归模型
本代码来自《老饼讲解-机器学习》www.bbblearn.com
"""
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
import numpy as np
#----数据加载------
data = load_breast_cancer() # 加载breast_cancer数据
X = data.data[:,4:8] # 作为示例,只使用4个变量来建模
y = data.target # 类别标签
#-----训练模型-------------
clf = LogisticRegression() # 初始化逻辑回归模型
clf.fit(X,y) # 训练逻辑回归模型
#------打印结果------------
print("模型参数:"+str(clf.coef_)) # 打印模型系数
print("模型阈值:"+str(clf.intercept_)) # 打印模型阈值
# 模型预测
test_x = np.array([[0.11, 0.27, 0.30, 0.14]]) # 要预测的x
test_y = clf.predict(test_x) # 用模型进行预测类别
test_p = clf.predict_proba(test_x) # 用模型进行预测概率
print(test_x,'的类别:',test_y,'概率:',test_p) # 打印预测结果代码运行结果如下:

如代码所示,在sklearn中只需要用LogisticRegression()函数就能初始化一个逻辑回归模型,然后用fit()来训练模型,最后预测样本类别时,就使用predict()方法来预测就可以了,但如果想输出样本属于类别1的概率,就要改用predict_proba()方法,就是这么的简单。
总结
实现逻辑回归模型时,可以自己使用梯度下降算法来训练,但更多时候会使用sklearn来实现,一方面是用sklearn会较方便一些,另一方面是自己实现的算法往往较为粗糙,在一些细节上没有处理得很好,因此效果有时没有软件的效果好,但作为学习,我们简单粗糙的写一下算法,能够加深对算法原理的理解。
 评论
评论
