目录
- 一、评分卡实践-bbbrisk-介绍
-
二、评分卡实践-bbbrisk-建模
-
2.1.评分卡-建模-示例
-
2.2.bbbrisk-建模-答疑
-
- 三、评分卡实践-bbbrisk-分箱
-
结束语
-
4.1.结束语
-
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【答疑】评分卡-直接用分组数据
作者 : 老饼
发表日期 : 2026-04-01 13:25:39
更新日期 : 2026-05-12 12:33:42
老饼讲解-简单易懂,干货满满,爽过嗦螺!
往往我们已经将数据处理为组号了,那么构建评分卡时就不需要再对数据进行分箱,好了,如果我们的数据是分组数据时,在bbbrisk中应该怎么构建评分卡呢?这也是非常简单的,下面就让我们直接用一个例子和代码来展示一下,马上就知道应该怎么干了~!
一、评分卡-实现代码-面向分组数据
这里我们以bbbrisk的bloan_grp数据为例,它是将bloan数据分箱后的数据,如下:
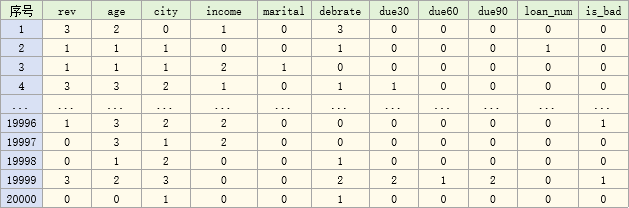
可以看到,每个变量的数据已经转换为组号了,下面我们展示在bbbrisk中如何用它来构建评分卡。
具体代码示例如下:
# 本代码展示当数据是分箱数据时,在bbbrisk中如何构建评分卡
# 本代码来自《老饼讲解-评分卡》www.bbblearn.com
import bbbrisk as br
#加载数据
data = br.datasets.load_bloan_grp() # 加载分组数据
x,y = data.iloc[:,:-1],data['is_bad'] # 样本变量与标签
# 构建评分卡
model,card = br.model.scoreCard(x,y,'grp',train_param={'random_state':0}) # 构建评分卡
score = card.predict(x[card.var]) # 用评分卡进行评分
card.featureScore # 评分卡-特征得分表
card.baseScore # 评分卡-基础分
# 打印结果
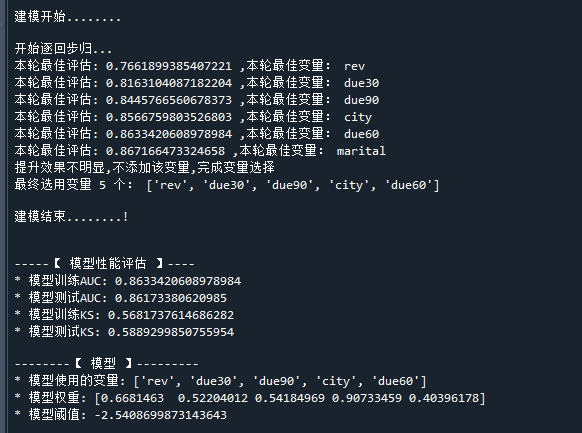
print('\n-----【 模型性能评估 】----')
print('* 模型训练AUC:',model.train_auc) # 打印模型训练数据集的AUC
print('* 模型测试AUC:',model.test_auc) # 打印模型测试数据集的AUC
print('* 模型训练KS:',model.train_ks) # 打印模型训练数据集的KS
print('* 模型测试KS:',model.test_ks) # 打印模型测试数据集的KS
print('\n--------【 模型 】---------')
print('* 模型使用的变量:',model.var) # 模型最终使用的变量
print('* 模型权重:',model.w) # 模型的变量权重
print('* 模型阈值:',model.b) # 模型的阈值
# 计算阈值表与分数分布图
thd_tb = br.report.get_threshold_tb(score,y,bin_step=10) # 阈值表
br.report.draw_score_disb(score,y,bin_step=10,figsize=(14, 4)) # 分数分布代码运行结果如下:
如何展示评分卡表、评分公式、阈值表等等,这里不再重述,参考《评分卡-实现代码-手动分箱》就可以了。
结束语
其实传入的不管是原始数据还是分箱数据,代码基本都是一样的,只不过如果是原始数据,那么在构建评分卡时就要传入分箱逻辑数bin_sets,而如果是分组数据,则用'grp'替代bin_sets可以了,以此说明传入的是"分组数据",那么model.scoreCard就会略去分箱的过程,直接用分组数据建模。
上一篇:
【答疑】评分卡-固定分数的区间
下一篇:
【答疑】评分卡-其它的常见答疑
 评论
评论
添加评论
- 教程
- bbbrisk
