目录
- 一、评分卡实践-bbbrisk-介绍
-
二、评分卡实践-bbbrisk-建模
-
2.1.评分卡-建模-示例
-
2.2.bbbrisk-建模-答疑
-
- 三、评分卡实践-bbbrisk-分箱
-
结束语
-
4.1.结束语
-
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【详述】city变量-详细分箱过程
作者 : 老饼
发表日期 : 2026-03-24 10:37:56
更新日期 : 2026-05-12 15:41:38
老饼讲解-简单易懂,干货满满,爽过嗦螺!
本文展示city变量(城市)的详细分箱过程,以及代码实现示例。
一、city变量-分箱过程
city变量是"客户的城市",它是一个枚举变量,本节展示city变量的详细分箱过程。
1.1. city变量-分箱过程
在正式分箱前,先对city变量粗略分箱,试探city变量的取值分布与badrate趋势,由于city是一个不太多的枚举变量,因此我们直接枚举出它所有的取值可能,统计结果如下:
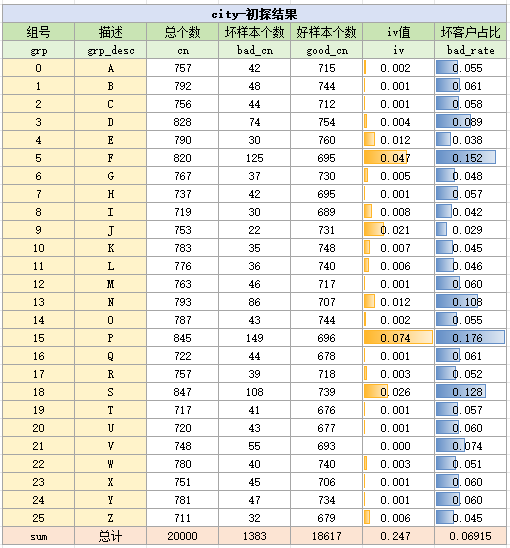
这样是不太好观察的,不妨将它按badrate进行排序,以方便分析,按badrate排序后的结果如下:
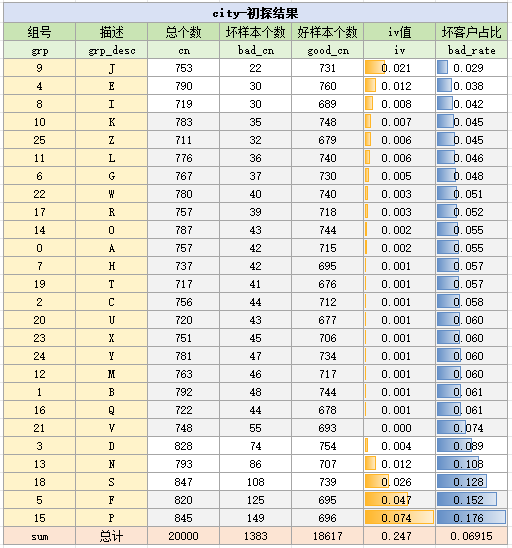
根据上述分析,我们将badrate相近的城市作为一组,即(J,E,I)、其它、(D,N,S)和(F,P),共分为4个箱,具体分箱结果如下:
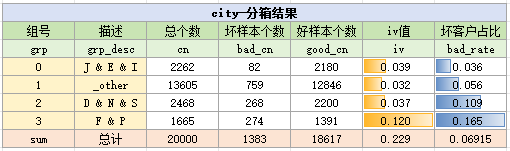
注意,在实际中需要检查那些偏坏的城市,是否符合实际,例如某个城市在数据表现上较坏,但实际不应该那么坏,就要追溯原因。
1.2. city变量-自动分箱结果
下面我们使用卡方分箱与ks分箱,看看两种算法对city变量的分箱结果。
卡方自动分箱结果如下:
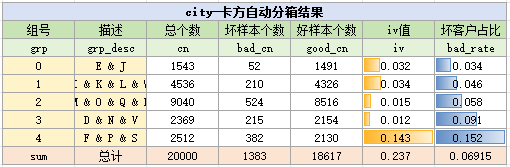
ks自动分箱结果如下:

对比手动分箱,卡方分箱和KS分箱和手动分箱的结果差不多,都是0.22、0.23左右。
二、city变量-分箱代码
本节展示city变量分箱过程中每一步的详细代码
2.1. city变量分箱-代码示例
上述分箱的每一步过程,所对应的具体代码实现如下:
import bbbrisk as br
from bbbrisk import bins
# 加载数据
data = br.datasets.load_bloan() # 加载数据
x = data['city'] # city变量
y = data['is_bad'] # 标签
br.display.pd.set(width=300,max_colwidth=30,max_rows=30) # 美化pandas的显示方式
# 列举所有城市的分箱情况
bin_set = bins.merge.allEnum(x)
bin_stat = bins.Bins(bin_set).binStat(x,y)
print(bin_stat)
print(bin_stat.sort_values(by='bad_rate'))
# 城市的分箱结果
bin_set = [('J','E','I'),'_other',('D','N','S'),('F','P')]
bin_stat = bins.Bins(bin_set).binStat(x,y)
print(bin_stat)
# 自动分箱-卡方分箱
bin_set = bins.merge.chi2Enum(x,y)
bin_stat = bins.Bins(bin_set).binStat(x,y)
print(bin_stat)
# 自动分箱-KS分箱
bin_set = bins.merge.ksEnum(x,y)
bin_stat = bins.Bins(bin_set).binStat(x,y)
print(bin_stat)运行上述代码,每一步都会打印出如下的结果:
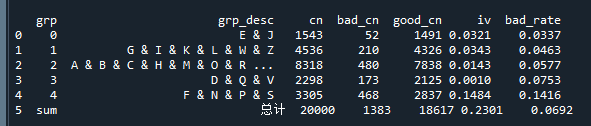
从结果中就可以看到每组的样本数、badrate和IV等等信息。
好了,以上就是city变量的详细分箱过程,以及代码实现了~
结束语
城市在评分卡中是一个经典的枚举变量,各个城市之间几乎没有太大直接的关系,它纯粹是按贷后表现差异来对城市进行分组,但是分组后也仍然需要从业务背景去审查一下,城市表现差是不是"差得有原因的",例如这个城市特别多人喜欢从诈骗等等。
上一篇:
【详述】age变量-详细分箱过程
下一篇:
【详述】income-详细分箱过程
 评论
评论
添加评论
- 教程
- bbbrisk
