目录
- 一、评分卡实践-bbbrisk-介绍
-
二、评分卡实践-bbbrisk-建模
-
2.1.评分卡-建模-示例
-
2.2.bbbrisk-建模-答疑
-
- 三、评分卡实践-bbbrisk-分箱
-
结束语
-
4.1.结束语
-
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【详述】age变量-详细分箱过程
作者 : 老饼
发表日期 : 2026-03-24 10:37:47
更新日期 : 2026-05-12 15:39:52
老饼讲解-简单易懂,干货满满,爽过嗦螺!
本文展示age变量(年龄)的详细分箱过程,以及代码实现示例。
一、age变量-分箱过程
age变量是"客户的年龄",它是一个整数数值变量,本节展示age变量的详细分箱过程。
1.1. age变量-分箱过程
在正式分箱前,先对age变量粗略分箱,试探age变量的取值分布与badrate趋势,由于age的取值是不太大的整数,不妨先以每5岁作为一个间隔,进行等距分箱,统计结果如下:
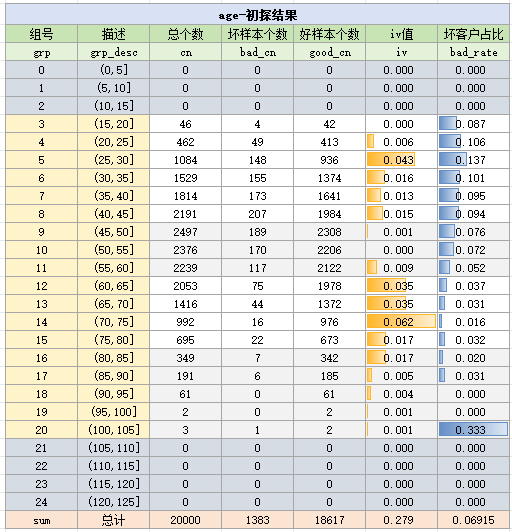
通过以上结果,我们初步分箱为<45、(45,60]、(60,80]与>80,分箱后的结果如下:
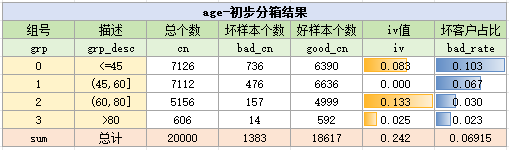
进一步地,我们观察每个年龄分割阈值附近的badrate,以方便把区间划得到精致,具体结果如下:
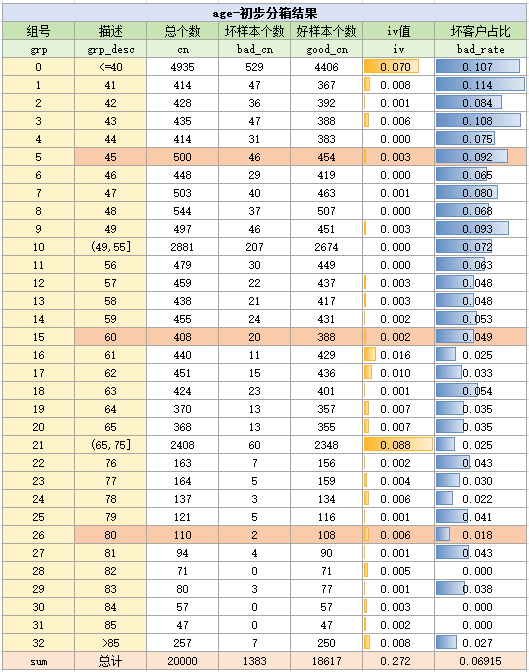
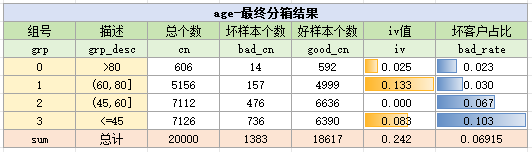
经过观察后,可以发现45、60、80的确最适合作为分箱切割点,因此保持分箱不变,但为了保持分箱的badrate单调上升,所以最终将分组顺序倒排,最终结果如下:
1.2. age变量-自动分箱结果
下面我们使用卡方分箱与ks分箱,看看两种分箱的结果如何。
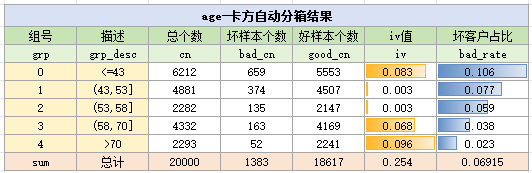
卡方自动分箱结果如下:
ks自动分箱结果如下:
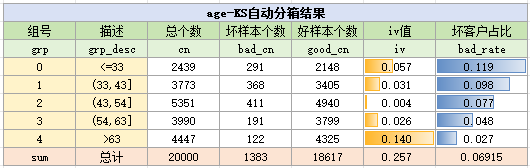
对比手动分箱,卡方分箱和KS分箱的IV都为0.25,而手动分箱的IV为0.24,可以参考卡方分箱与KS分箱对手动分箱进行调整,也可以不进行调整,需要注意的是,在调整分箱时,需要考虑是在业务逻辑是否能解释通畅。
二、age变量-分箱代码
本节展示age变量分箱过程中每一步的详细代码。
2.1. age变量分箱-代码示例
上述分箱的每一步过程,所对应的具体代码实现如下:
import bbbrisk as br
from bbbrisk import bins
# 加载数据
data = br.datasets.load_bloan() # 加载数据
x = data['age'] # age变量
y = data['is_bad'] # 标签
br.display.pd.set(width=300,max_colwidth=30,max_rows=30) # 美化pandas的显示方式
# 以5为间隔,生成25个分箱
bin_set = [[i*5,(i+1)*5] for i in range(25)]
bin_stat = bins.Bins(bin_set).binStat(x,y)
print(bin_stat)
# 初步分箱结果
bin_set = [['-',45],[45,60],[60,80],[80,'+']]
bin_stat = bins.Bins(bin_set).binStat(x,y)
print(bin_stat)
# 探测45、60、80附近的分布明细
bin_set = [['-',40],41,42,43,44,45,46,47,48,49
,[49,55],56,57,58,59,60,61,62,63,64,65
,[65,75],76,77,78,79,80,81,82,83,84,85
,[85,'+']]
bin_stat = bins.Bins(bin_set).binStat(x,y)
print(bin_stat)
# 最终的分箱结果
bin_set = [[80,'+'],[60,80],[45,60],['-',45]]
bin_stat = bins.Bins(bin_set).binStat(x,y)
print(bin_stat)
# 卡方自动分箱
bin_set = bins.merge.chi2(x,y)
bin_stat =bins.Bins(bin_set).binStat(x,y)
print(bin_stat)
# KS自动分箱
bin_set = bins.merge.ks(x,y)
bin_stat = bins.Bins(bin_set).binStat(x,y)
print(bin_stat)运行上述代码,每一步都会打印出如下的结果:
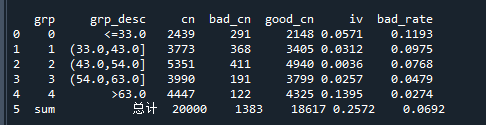
从结果中就可以看到每组的样本数、badrate和IV等等信息。
好了,以上就是age变量的详细分箱过程,以及代码实现了~
结束语
年龄变量的分箱是一个特殊、经典的分箱例子,它一般会影响到客户是否逾期,但它与客户逾期的关系又不是简单的单调关系,不是年龄越大就越容易逾期,所以一般要将数据分析与业务背景结合来对它分箱,在划分出合理的年龄段的同时,又能保证在业务上可以解释通畅。
上一篇:
【详述】rev变量-详细分箱过程
下一篇:
【详述】city变量-详细分箱过程
 评论
评论
添加评论
- 教程
- bbbrisk
