-
评分卡-逻辑回归-原理
-
1.1.逻辑回归-基本原理
-
1.2.逻辑回归-如何理解
-
- 评分卡-原理细节-详述
-
评分卡-变量分箱-原理
-
3.1.评分卡-变量分箱-原理
-
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【模型】逻辑回归-原理-快速上手
评分卡中使用的模型就是逻辑回归模型,有些同学可能对逻辑回归不够熟悉,这节我们来介绍一下逻辑回归模型的基础原理,并略为倾向评分卡所用的关于逻辑回归的内容。
一、逻辑回归模型
1.1. 逻辑回归-模型表达式
逻辑回归模型是一个用于二分类的模型,它给出样本属于正样本的概率。
逻辑回归的模型表达式如下:
其中,
如果喜欢把整个模型写为一个式子,则是:
可以看到,逻辑回归模型内部就是一个线性函数,外部则是一个sigmoid函数,下面我们着重看看sigmoid函数。
- sigmoid函数
sigmoid函数的图像如下:
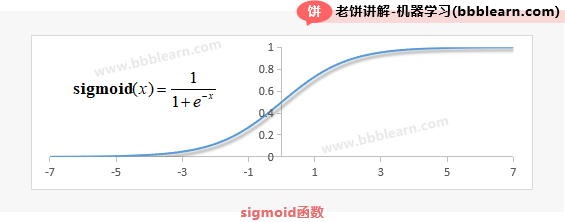
从图像易知,sigmoid函数的输出在(0,1)之间,所以不管x是什么,最终逻辑回归模型的输出p都在(0,1)之间,在逻辑回归模型中,它的输出p始终代表样本属于正样本的概率。
1.2. 如何理解-逻辑回归模型
好了,逻辑回归模型是什么意思呢?我们可以简单地从逻辑回归模型的表达式来理解它,它其实是把WX作为样本属于正样本的判别值,再在WX外面套了一个sigmoid函数来将判别值转为概率:
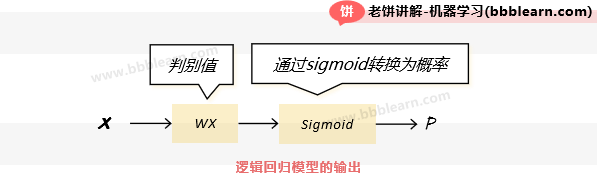
作为入门,一般这样理解就可以了,它的提出较为特殊,属于"先用后解释"的模型,在逻辑回归模型出现之前,sigmoid函数就已经在各个领域作为概率使用了,所以刚开始大家只是单纯地借鉴其它领域思路把sigmoid(WX)作为一个二分类的概率模型用起来,用着用着,再渐渐提出了各种理解和解释,所以,可以从许多角度去解释逻辑回归模型,但并没有统一的解释,而作为入门,把它当成一个" 线性回归应用于0、1逻辑判断(二分类)"的模型就好了。
二、逻辑回归模型-训练
2.1. 逻辑回归-损失函数
逻辑回归模型在训练参数W时,用交叉熵函数来作为损失函数:
其中,是样本数,是第i个样本的预测值。
逻辑回归的训练,就是通过算法来寻找一个W,使得L(W)尽量最小化。
2.2. 逻辑回归-训练算法
训练逻辑回归的算法有许多,比较常用的是梯度下降法、或者牛顿法。
以梯度下降法为例,它的算法流程就是先初始化一个W,然后每次再往L(W)的负梯度方向调整,直到梯度较小,就退出训练。
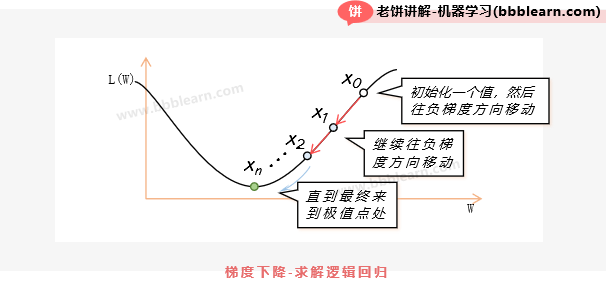
比较值得注意的是,在训练前将数据归一化,可以有助于梯度下降算法的训练速度,所以一般在训练前会把数据归一化到[0,1]之间,但这样训练出来的模型,一般在预测时,也需要按照训练时的归一化规则,把数据先进行归一化,再进行预测。
2.3. 逻辑回归-正则化
为了控制逻辑回归训练出来不要过大(过大往往会违背客观事实,容易导致模型过拟合),一般在训练逻辑回归时,可以在损失函数中加入L2正则项,即损失函数为:
其中,是惩罚系数。
可以看到,L2正则项其实就是各个系数的平方和,在加入L2正则项之后,在训练时为了让L(W)尽量的小,就会自然而然地避免了过大的系数。同时,为了能公平地惩罚各个系数,一般需要统一输入变量的量纲,也就是先将数据进行归一化,这样才能更好地达到我们惩罚系数的原始初衷。
所以,逻辑回归不管是出于"加速训练"、还是"正则项的公平",一般最好是对X进行归一化,再进行训练。
三、逻辑回归-使用示例
最后,我们来简单地看一下在sklearn中如何训练一个逻辑回归模型,代码如下:
"""
本代码展示在python中调用sklearn来训练逻辑回归模型
本代码来自《老饼讲解-机器学习》www.bbblearn.com
"""
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
import numpy as np
#----数据加载------
data = load_breast_cancer() # 加载breast_cancer数据
X = data.data[:,4:8] # 作为示例,只使用4个变量来建模
y = data.target # 类别标签
#-----训练模型-------------
clf = LogisticRegression() # 初始化逻辑回归模型
clf.fit(X,y) # 训练逻辑回归模型
#------打印结果------------
print("模型参数:"+str(clf.coef_)) # 打印模型系数
print("模型阈值:"+str(clf.intercept_)) # 打印模型阈值
# 模型预测
test_x = np.array([[0.11, 0.27, 0.30, 0.14]]) # 要预测的x
test_y = clf.predict(test_x) # 用模型进行预测类别
test_p = clf.predict_proba(test_x) # 用模型进行预测概率
print(test_x,'的类别:',test_y,'概率:',test_p) # 打印预测结果代码运行结果如下:

从结果可以看到,最终训练得到的模型为:
当输入x=[0.11,0.27,0.3,0.4]时,属于0类的概率为0.8674,属于1类的概率为0.1326,判别结果为0类。
- 代码说明
在sklearn中,使用LogisticRegression就可以初始化一个逻辑回归模型了,它默认使用L2正则项,从结果中我们可以看到,训练得到的系数并不会非常大,我们也可以设置更大的惩罚系数,使得训练出来的系数更加小。
备注:一般需要将X先进行归一化(特别是加入L2正则项时),这里我们只是图方便,没有进行归一化。
结束语
在这一节中,我们简单的讲述了逻辑回归模型是什么,以及它是如何训练的、训练时需要注意的地方,这些就是逻辑回归的一些基础知识了,后面我们再慢慢加深对逻辑回归的理解。
 评论
评论
- 教程
- bbbrisk
