目录
- 一、评分卡实践-bbbrisk-介绍
-
二、评分卡实践-bbbrisk-建模
-
2.1.评分卡-建模-示例
-
2.2.bbbrisk-建模-答疑
-
- 三、评分卡实践-bbbrisk-分箱
-
结束语
-
4.1.结束语
-
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【详述】loan_num-分箱的过程
作者 : 老饼
发表日期 : 2026-03-24 10:39:06
更新日期 : 2026-05-12 15:45:13
老饼讲解-简单易懂,干货满满,爽过嗦螺!
本文展示loan_num变量(在贷笔数)的详细分箱过程,以及代码实现示例。
一、loan_num变量-分箱过程
loan_num变量是"客户的在贷笔数",它是一个整数数值变量,下面详细讲解loan_num变量的分箱过程。
1.1. loan_num变量-分箱过程
在正式分箱前,先对loan_num变量粗略分箱,试探loan_num变量的取值分布与badrate趋势。由于loan_num的取值是不太大的整数,因此我们直接枚举出它所有的取值可能,统计结果如下:
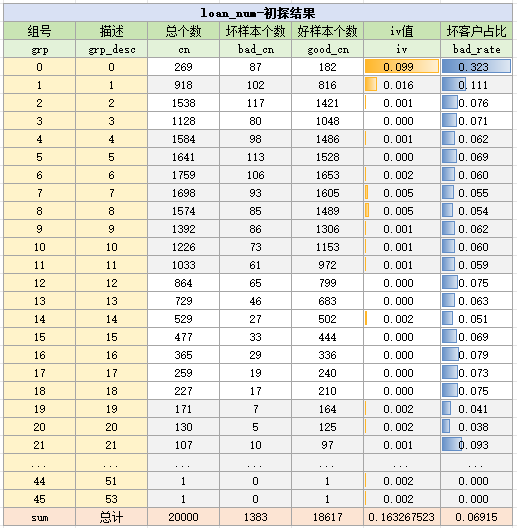
将badrate较连续相似的合并,最终分箱为:0,1,[2,3],(3,11],(11,18],>18,分箱结果如下:
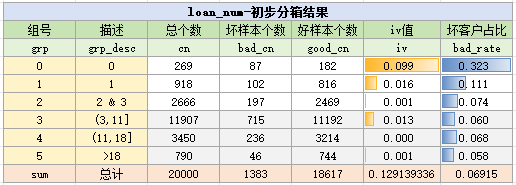
由于3、4、5组区分不大,进一步地,我们将它们合并,最终分箱结果如下:
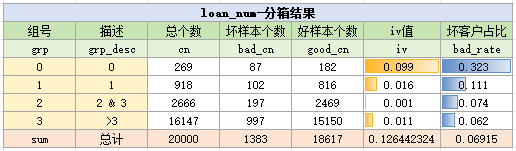
1.2. loan_num变量-自动分箱结果
下面我们使用卡方分箱与ks分箱,看看两种算法对loan_num变量的分箱结果。
卡方自动分箱结果如下:
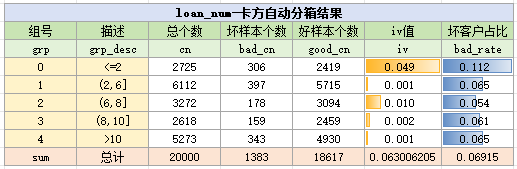
ks自动分箱结果如下:
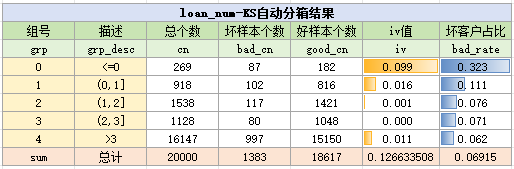
可以看到,KS分箱和手动分箱效果类似,IV值都为0.126,而卡方分箱则略差,这是因为=0的样本过少,卡方分箱没有将0作为一个独立组别。
二、loan_num变量-分箱代码
本节展示loan_num变量分箱过程中每一步的详细代码
2.1. loan_num变量分箱-代码示例
上述分箱的每一步过程,所对应的具体代码实现如下:
import bbbrisk as br
from bbbrisk import bins
# 加载数据
data = br.datasets.load_bloan() # 加载数据
x = data['loan_num'] # 变量
y = data['is_bad'] # 标签
br.display.pd.set(width=300,max_colwidth=30,max_rows=30) # 美化pandas的显示方式
# 枚举所有的值进行分箱
bin_set =bins.merge.allEnum(x)
bin_stat = bins.Bins(bin_set).binStat(x,y)
print(bin_stat)
# 初步分箱结果
bin_set = [0,1,(2,3),[3,11],[11,18],[18,'+']]
bin_stat = bins.Bins(bin_set).binStat(x,y)
print(bin_stat)
# 最终分箱结果
bin_set = [0,1,(2,3),[3,'+']]
bin_stat = bins.Bins(bin_set).binStat(x,y)
print(bin_stat)
# 自动分箱-卡方分箱
bin_set = bins.merge.chi2(x,y)
bin_stat = bins.Bins(bin_set).binStat(x,y)
print(bin_stat)
# 自动分箱-KS分箱
bin_set = bins.merge.ks(x,y,min_sample=200)
bin_stat = bins.Bins(bin_set).binStat(x,y)
print(bin_stat)运行上述代码,每一步都会打印出如下的结果:
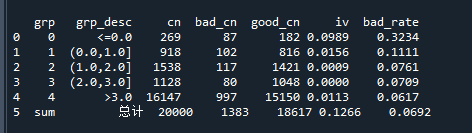
从结果中就可以看到每组的样本数、badrate和IV等等信息。
好了,以上就是loan_num变量的详细分箱过程,以及代码实现了~
结束语
整数变量一般直接枚举出所有取值的badrate,然后进行分析、合并分箱就可以了,某种意义上也算是枚举变量,但略为不同的是,整数变量具有"连续性",需要按段来初步分箱,再进一步合并分箱就可以了。
上一篇:
【详述】due90 - 详细分箱过程
下一篇:
【例子】评分卡-bbbrisk-使用总结
 评论
评论
添加评论
- 教程
- bbbrisk
