- 一、评分卡实践-bbbrisk-介绍
-
二、评分卡实践-bbbrisk-建模
-
2.1.评分卡-建模-示例
-
2.2.bbbrisk-建模-答疑
-
- 三、评分卡实践-bbbrisk-分箱
-
结束语
-
4.1.结束语
-
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【例子】评分卡-bbbrisk-使用总结
学习了这么久的bbbrisk评分卡,内容比较繁杂,这里我们进一步对之前接触过的内容进行梳理,来作为最后的总结,这样使用起来思路就会更加清晰一些,也方便查漏补缺。
一、评分卡-实践-总结
下面我们来简单总结一下bbbrisk的使用,以此梳理出更清晰的使用思路。
首先,我们以分箱逻辑为核心,把评分卡的建卡工作一分为二:
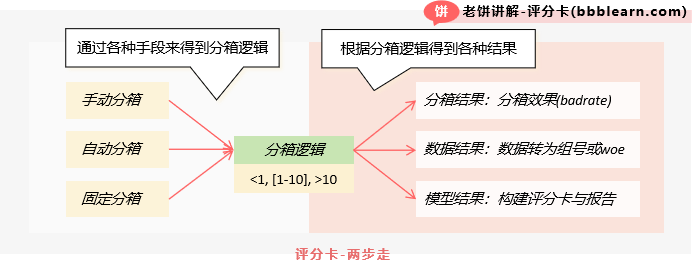
如图,一边是怎么对变量分箱,另一方面是分好箱之后,如何获得相关结果。
下面我们就围绕这两方面,来整理和总结一下bbbrisk在这两方面是如何应用、如何实现的。
二、如何获得变量的分箱
2.1. 单个变量的分箱
对于单个变量的分箱,可以直接设置分箱逻辑,也可以通过自动分箱来获得分箱逻辑。
单变量,如果是连续变量,可以用bins.merge.eSample、bins.merge.eDist、...、bins.merge.tree等函数。
单变量,如果是枚举变量,可以用bins.merge.chi2Enum、...、bins.merge.allEnum等函数。
设置好分箱逻辑后,就可以通过bins.batch.bin_stats来打印分箱的badrate效果了:
import bbbrisk as br
from bbbrisk import bins
data = br.datasets.load_bloan() # 加载数据
x,y= data['rev'], data['is_bad'] # x和y
bin_set = [['-',0],[0,0.1],[0.1,0.37],[0.37,0.64],[0.64,1.2],[1.2,2],[2,'+']] # 手动设置分箱
bin_set = bins.merge.chi2(x,y) # 或者使用自动分箱
bin_stat = bins.Bins(bin_set).binStat(x,y) # 统计分箱结果
br.display.pd.set(width=300,max_colwidth=30,max_rows=30) # 美化pandas的显示方式
print(bin_stat) # 显示分箱结果运行结果:
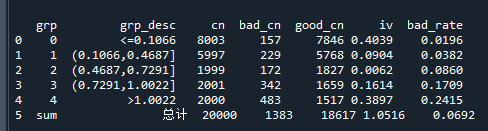
根据badrate或iv值,来决定如何调整分箱,并判断变量的有效性。
2.2. 整体变量的分箱
通过对单个变量的分析,我们就可以得到所有变量的分箱逻辑,然后把它们合并在一起,事实上,也可以直接用bins.batch.autoBins来一次性通过自动分箱来获得所有变量的分箱结果,如下:
# 手动合并所有变量的分箱
bin_sets = {
'rev' :[[0,0.1],(['-',0],[0.1,0.37]),[0.37,0.64],([0.64,1.2],[2,'+']),[1.2,2],]
,'age' :[[80,'+'],[60,80],[45,60],['-',45]]
,'city' :[('J','E','I'),'_other',('D','N','S'),('F','P')]
,'income' :[[1000,5000],[5000,9000],(['-',1000],[20000,'+'],None),[9000,16000],[16000,20000]]
,'marital':[1,0,2]
,'debrate':[([0,0.1],[850,'+']),([0.1,0.5],[5,850]),([0.5,0.8],0),[0.8,5]]
,'due30' :[0,1,2,(3,4),[4,'+']]
,'due60' :[0,1,2,[2,'+']]
,'due90' :[0,1,[1,'+']]
,'loan_num':[[3,'+'],(2,3),1,0]
}
# 也可以直接自动分箱
bin_sets = br.bins.batch.autoBins(x, y,enum_var=['city','marital']) 如此一来,变量的分箱就告一段落了,下面就是如何用变量的分箱,来获得各种结果。
三、获得各种结果
3.1. 获得评分卡结果
要想获得评分卡,只需要调用model.scoreCard函数就可以了。
model,card = br.model.scoreCard(x,y,bin_sets,train_param={'random_state':0}) # 构建评分卡然后返回的card 就存放了评分卡,model则是逻辑回归模型。
1. 获取评分卡
card.baseScore是基础分,card.featureScore是特征得分,合并它们就是评分卡表了。
2. 获取评分的其它参数
card.d、B、k、S 是模型转评分时的所用的四个参数。
card.factor、card.offset是模型转评分时的缩放因子和偏移量。
3. 获取模型系数
model.w、model.b以woe为输入时的模型系数。
model.w_norm、model.w_norm是以归一化woe为输入时的模型系数。
4. 查看模型的效果
model.train_auc、train_ks、test_auc、test_ks里就存放了模型的训练、测试AUC、KS。
5. 获得样本的评分
如果想获得所有样本的评分,那么只需要将x放到评分卡中预测评分就行了。但需要注意的是,建模时过滤掉了一些变量,所以也要将x的变量进行过滤,整体代码就为:
score = card.predict(x[card.var])6. 获得评分卡报告(分数分布与阈值表)
接下来,确定了建模效果后,就是打印相关的报告内容了,主要就两样东西:分数分布图与阈值表。
上面已经计算出所有样本的分数,将它放到report.draw_score_disb和report.get_threshold_tb里就可以得到分数分布图了和阈值表了,如下:
report.draw_score_disb(score,y,bin_step=10,figsize=(12, 4))
tb = report.get_threshold_tb(score,y,bin_step=10)3.2. 获得变量的分箱效果
将数据x,y按整体变量的分箱逻辑bin_sets进行统计就可以了,代码如下:
bin_stats = br.bins.batch.bin_stats(x,y,bin_sets) # 统计各个变量的分箱情况
for var in bin_stats: # 逐个变量打印分箱结果
print('\n变量'+var+'的分箱结果:\n',bin_stats[var]) # 打印当前变量的分箱统计结果实际使用时一般不用for来打印,而是将bin_stats的内容复制到Excel进行美化和整理,得到最终的报告结果。
3.3. 获得分组或woe数据
一般在bbbrisk中构建评分卡并不需要使用这功能,但如果有同学纯粹只想用bbbrisk来分箱、并得到分箱后的分组数据,那就可以如下处理:
import bbbrisk as br
# 加载数据
data = br.datasets.load_bloan() # 加载数据
x,y = data.iloc[:,:-1],data['is_bad'] # 变量与标签数据
bin_sets = br.bins.batch.autoBins(x, y,enum_var=['city','marital']) # 自动分箱
x_grp,_ = br.encode.grp.to_grp(x,bin_sets) # 将数据转换为分组数据
woe_dict = br.encode.woe.get_woe_dict(x_grp,y) # 获得分组数据的woe映射表
woe_data = br.encode.woe.to_woe(x_grp,woe_dict) # 按woe映射表将分组数据转换为woe数据上面代码中的x_grp就是x的分组数据了,而woe_data就是转换为woe后的数据了,大家运行一下就明白什么意思了,毕竟这功能较少用,需要的按照上面的代码看一下相关的API就明白了。
结束语
总的来说,先通过手动分析或自动分箱来获得所有变量的分箱,然后就可以构建评分卡了,再打印评分卡的相关的报告就可以了。此外,还可以通过分箱逻辑来得到变量的分箱效果、变量的分组(或woe)数据。
 评论
评论
- 教程
- bbbrisk
