- 一、评分卡实践-bbbrisk-介绍
-
二、评分卡实践-bbbrisk-建模
-
2.1.评分卡-建模-示例
-
2.2.bbbrisk-建模-答疑
-
- 三、评分卡实践-bbbrisk-分箱
-
结束语
-
4.1.结束语
-
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【实例】评分卡-建模代码(自动)
有时我们需要快速构建一个评分卡,这时候就可以采用自动分箱了,也就是通过算法来对变量自动分箱,这样就不需要人工参与,只需把原始数据直接丢到代码中就可以自动分箱、自动构建出整个评分卡了。本文讲解在bbbrisk中如何自动分箱并构建评分卡的方法,这是一种快捷构建评分卡的方法。
一、评分卡-建模代码-自动分箱
在本文中,我们仍然以bbbrisk的bloan小贷数据为例,来讲解如何全自动地构建评分卡。
bloan数据共2万条,包含10个变量,示例如下:
1.1. 评分卡-实现代码-自动分箱
在bbbrisk中,可以使用bins.autoBin函数来对多个变量进行自动分箱,因此我们只需要先自动分箱、再使用model.scoreCard函数来构建评分卡就可以了,具体代码如下:
# 本代码展示在bbbrisk如何以自动分箱方式自动构建评分卡
# 本代码来自《老饼讲解-评分卡》www.bbblearn.com
import bbbrisk as br
# 加载数据
data = br.datasets.load_bloan() # 加载数据
x = data.iloc[:,:-1] # 变量数据
y = data['is_bad'] # 标签数据
# 自动分箱
bin_sets = br.bins.batch.autoBins(x, y,enum_var=['city','marital']) # 自动分箱
bin_stats = br.bins.batch.bin_stats(x,y,bin_sets) # 统计各个变量的分箱情况
# 构建评分卡
model,card = br.model.scoreCard(x,y,bin_sets,train_param={'random_state':0}) # 构建评分卡
score = card.predict(x[card.var]) # 用评分卡进行评分
card.featureScore # 评分卡-特征得分表
card.baseScore # 评分卡-基础分
# 打印结果
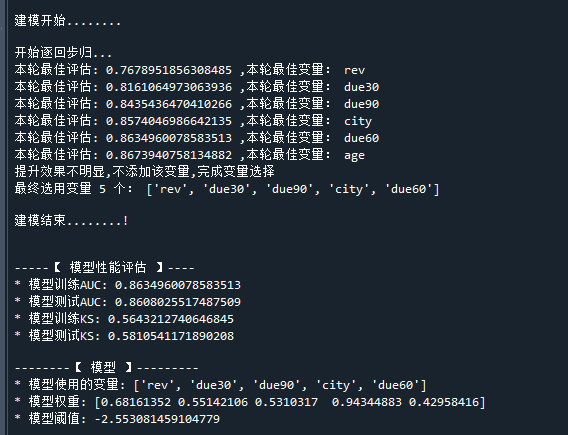
print('\n-----【 模型性能评估 】----')
print('* 模型训练AUC:',model.train_auc) # 打印模型训练数据集的AUC
print('* 模型测试AUC:',model.test_auc) # 打印模型测试数据集的AUC
print('* 模型训练KS:',model.train_ks) # 打印模型训练数据集的KS
print('* 模型测试KS:',model.test_ks) # 打印模型测试数据集的KS
print('\n--------【 模型 】---------')
print('* 模型使用的变量:',model.var) # 模型最终使用的变量
print('* 模型权重:',model.w) # 模型的变量权重
print('* 模型阈值:',model.b) # 模型的阈值
# 计算阈值表与分数分布图
thd_tb = br.report.get_threshold_tb(score,y,bin_step=10) # 阈值表
br.report.draw_score_disb(score,y,bin_step=10,figsize=(14, 4)) # 分数分布代码运行结果如下:
构建完后的card.featureScore和card.baseScore合并起来就是评分卡表,thd_tb就是阈值表,具体参考上张文章《评分卡-建模代码(手动)》就可以了,这里我们不再重复讲述。
二、autoBin自动分箱-进阶使用
在上面的代码中,我们就已经自动构建出评分卡了,下面我们进一步讲解bins.autoBin函数的一些日常使用。
我们先直接上代码,如下:
# 本代码展示如何用bbbrisk对变量进行自动分箱
# 本代码来自《老饼讲解-评分卡》www.bbblearn.com
import bbbrisk as br
# 加载数据
data = br.datasets.load_bloan() # 加载数据
x = data.iloc[:,:-1] # 变量数据
y = data['is_bad'] # 标签数据
# 自动分箱
bin_sets = br.bins.batch.autoBins(x, y,enum_var=['city','marital']) # 自动分箱,需要指出哪些是枚举变量
bin_stats = br.bins.batch.bin_stats(x,y,bin_sets) # 统计各个变量的分箱情况
br.display.pd.set(width=300,max_colwidth=30,max_rows=30) # 美化pandas的显示方式
for var in bin_stats: # 逐个变量打印分箱结果
print('\n变量'+var+'的分箱结果:\n',bin_stats[var]) # 打印当前变量的分箱统计结果
# 选择iv足够大的变量
select_bin_set = {} # 初始化选择的变量的分箱
for var,stat in bin_stats.items(): # 逐个变量循环
if (stat['iv'].iloc[-1]>0.1): # 当前变量的iv值是否满足要求
select_bin_set[var] = bin_sets[var] # 如果满足,则添加到选择池
print('\n iv > 0.1 的变量与分箱结果:\n',select_bin_set) # 最终选择的变量的分箱好了,下面我们一起来逐行看下代码(前10行的代码是加载数据,我们直接忽略,直接从11行开始看)。
- 变量自动分箱
第11行是对变量进行自动分箱: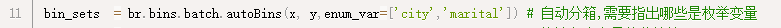
这里调用bins.autoBin函数,就能直接对x,y进行分箱了,由于变量中有一些是枚举变量,而枚举变量和连续变量采用的自动分箱策略是不同的,所以如果有枚举变量,就需要在enum_var参数中明确指出哪些是枚举变量。
上面的代码得到的bin_sets就是自动分箱后的结果,它是一个dict对象,如下:
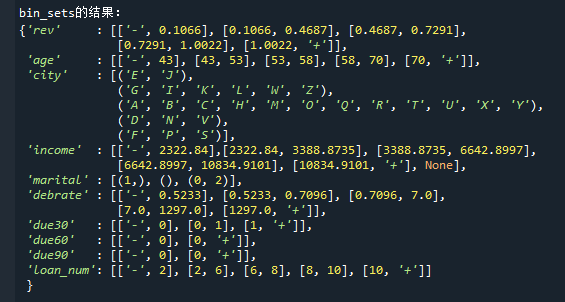
这一句代码,就已经得到各个变量的自动分箱结果了,直接把bin_sets作为分箱配置来构建评分卡就可以了。
- 分箱的统计信息
第12-15行演示了如何打印分箱统计信息。
虽然上面的bin_sets已经得到了分箱结果,但写报告时,我们往往需要每个变量具体的分箱统计信息,所以12-15行演示了如何打印分箱统计信息。
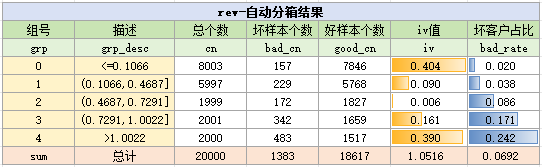
可以看到,真正统计分箱信息的只有第12行,而第13-15行仅仅是逐个变量打印统计信息而已。在第12行中的bins.bin_stat函数所返回的bin_stats中,就已经存放了样本x,y在各个分箱的分布、iv值与badrate。
例如rev变量的统计信息打印结果如下:
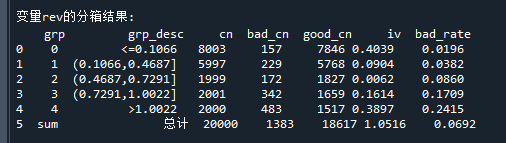
整理到Excel中就是如下效果了:
- 根据iv筛选变量
下面再来看17-22行代码,它所干的事情是通过iv来筛选变量。
自动分箱是为了快捷地、自动地完成分箱,所以一般会简单地借助iv值来判断变量的有效性,由于在iv<0.02时,变量普遍被认为无效,在这里我们不妨把条件加严,筛选出iv>0.1的变量。
最终选择出的变量以及分箱如下:
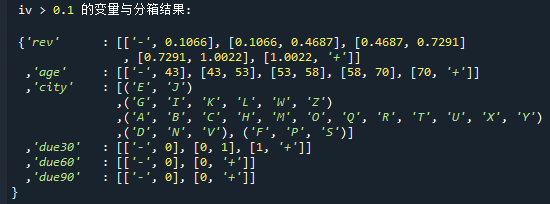
如果要使用iv筛选后变量构建评分卡,只需要在构建评分卡时,将bin_sets改为select_bin_set就可以了。
结束语
好了,以上就是如何自动构建评分卡的方法了,一般来说,自动分箱合理性、稳健性会比手动分箱差一些,但它的好处是快速、自动、不需要人参与,有一些需要自动上线的项目、或者为了快速构建评分卡、或者对评分卡的可靠性要求不那么严时,就可以直接使用这种方法来进行构建。
 评论
评论
- 教程
- bbbrisk
