-
机器学习-模型
-
1.1.线性模型
-
1.2.分类模型
-
1.3.集成模型
-
1.4.降维算法
-
1.5.聚类算法
-
- 神经网络-模型
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【模型】一篇入门之-提升树AdaBoost
AdaBoost是一种用于解决二分类问题的boosting集成方法,由于AdaBoost提出得较早,已经熟为人知,但现在已经相对较少使用了,虽然如此,它的许多概念还是被流传了下来,作为学习,了解一下AdaBoost模型还是很有必要的,今天我们就来简单的讲讲AdaBoost的模型原理,以及它的代码实现例子。
一、AdaBoost模型
1.1. 初步认识-AdaBoost是什么
AdaBoost是由 Yoav Freund 和 Robert E. Schapire 于 1995年提出的一种集成模型,它呢主要是用来解决二分类问题,只不过它是一种算法框架,它以其它二分类模型(也称为决策器)作为基模型,然后使用boosting的方法来训练多个基模型,再用多个基模型共同去进行预测:
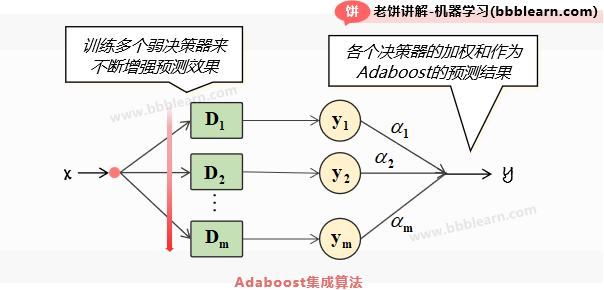
如图所示,AdaBoost就是训练多个决策器进行共同预测,它是一种boosting模型,也就是它以逐个训练的方式,来逐步提升模型的精度,最后再合并多个模型进行预测,Adaboost模型可以表示为:
其中,
: 第个决策器,输出必须是{-1,1}
: 决策器的权重系数,为正数
最喜欢看公式了,从公式可以非常具体的看到,Adaboost模型就是一堆决策器的决策结果,进行加权求和。
1.2. 说说AdaBoost的决策器
眼尖的同学会发现,AdaBoost的决策器一定是二分类模型,因为它是为集成二分类模型而诞生的,并且,它约定二分类模型的输出必须是{-1,1},但这只是理论上的约定,也就是为了方便推导相关公式而约定的前提条件,在实际应用上就不一定要求是{-1,1},因为输出标签之间是可以任意转换的,只要套上一层转换就可以了。
更进一步地,AdaBoost往往会用决策树模型来当决策器,这时候就称为提升树模型了,所以提升树模型就是AdaBoost模型的一种具体实现。
二、AdaBoost-模型训练
上面我们说了,AdaBoost就是逐个训练决策器,逐步提升精度,下面我们来看看AdaBoost的损失函数。
2.1. AdaBoost-损失函数
从整体上来说,AdaBoost模型的损失函数为:
其中, :样本个数
:模型对第i个样本的预测值
即
这个损失函数称为指数损失函数,它是AdaBoost特殊构造出来的损失函数,从这里我们就明白为什么AdaBoost一定要求决策器输出的是{-1,1}了,因为当真实值与预测值不一致时,它们符号相异,,相异越大,就越大,整体损失就越大,所以指数损失函数可以很好地引导模型的预测结果与真实标签靠近。
2.2. Adaboost的训练模式
我们知道,Adaboost中,既要训练每个决策器,也要训练每个决策器的权重,所以它是以如下的方式来进行训练:
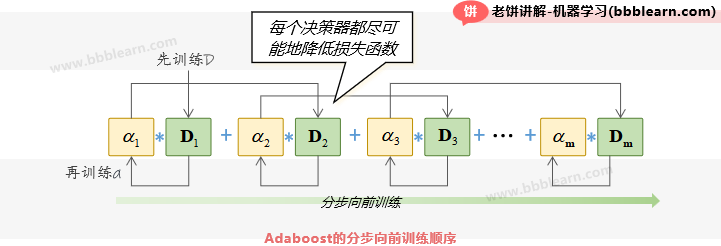
这就称为前向分步训练算法,也就是逐个向前训练决策器,训练完决策器后就训练权重,直到满足终止条件,例如决策器个数过多、新增决策器已无提升效果等等。
2.3. AdaBoost的训练流程
先来直接晒个图,AdaBoost的训练算法流程如下:
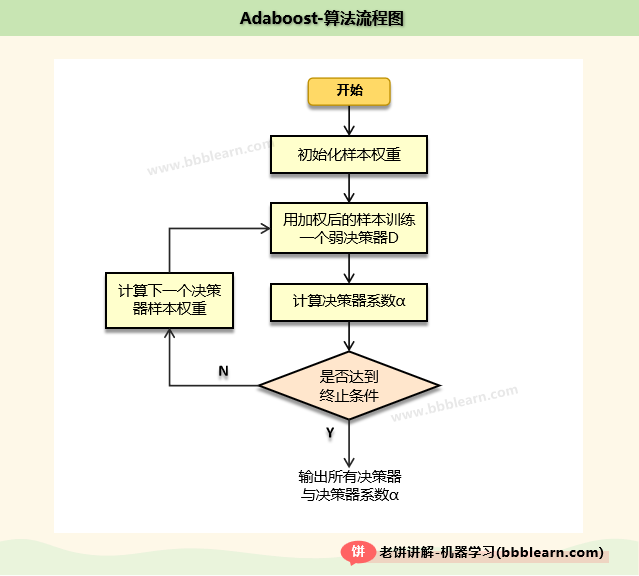
决策器 和系数 的训练方法如下:
一、决策器的训练
每个决策器以不同的样本权重来训练
第1个决策器的样本权重为:
,N为样本个数
第k个决策器的样本权重为:
二、决策器系数的训练
第k个决策器系数的计算公式如下:
其中,
直观地理解,Adaboost就是通过修改样本权重使每次的决策器偏向上一个决策器的错误样本,在训练第k个决策器时,把第k-1个决策器预测错误的样本权重调大,预测正确的样本权重调小。
为什么Adaboost采用这样的训练方法呢?以及它的权重修正公式、求解公式又是怎么来的呢,其实这与它的损失函数是紧密联系的,但推导过程较长,这里省略,大家大概知道怎么一回事就好了,严谨推导见机器学习的详细课程。
三、AdaBoost-代码实现
AdaBoost的原理大概就是这么回事了,下面我们借助sklearn来实现一下AdaBoost。
"""
本代码展示sklearn包实现Adaboost提升树算法
本代码来自《老饼讲解-机器学习》www.bbblearn.com
"""
import matplotlib.pyplot as plt
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_gaussian_quantiles
np.random.seed(888) # 为方便复现,设定随机种子
# ----- 数据生成 --------
# 生成2维正态分布,数据按分位数分为两类,500个样本,2个样本特征,协方差系数为2
X, y = make_gaussian_quantiles(n_classes=2,cov=2.0,n_samples=500,n_features=2) # 生成训练样本数据
# --- 模型训练与预测 ----
tree = DecisionTreeClassifier(max_depth=2,min_samples_split=20,min_samples_leaf=5) # 初始化决策树作为决策器
clf = AdaBoostClassifier(tree,n_estimators=50,learning_rate=0.8) # 初始化AdaBoost
clf.fit(X, y) # 模型训练
pred = clf.predict(X) # 模型预测的类别
proba = clf.predict_proba(X) # 模型预测的概率
# ----- 打印结果---------
fig, axes = plt.subplots(2, 1,figsize=(10, 6)) # 初始化画布
plt.subplots_adjust(wspace=0.2, hspace=0.3) # 调整画布子图间隔
axes[0].scatter(X[:, 0], X[:, 1], c=y) # 画出样本与真实类别
axes[0].set_title('sample-true-class') # 设置第一个子图的标题
axes[1].scatter(X[:, 0], X[:, 1], c=pred) # 画出样本与预测类别
axes[1].set_title('sample-predict-class') # 设置第二个子图的标题
plt.show() # 显示画布
print("\n----前10个样本预测结果-----:\n",proba[1:10,1]) # 打印前10个样本的预测值
print("\n---各个决策器的权重系数----:\n",clf.estimator_weights_) # 打印决策器权重代码运行结果如下:
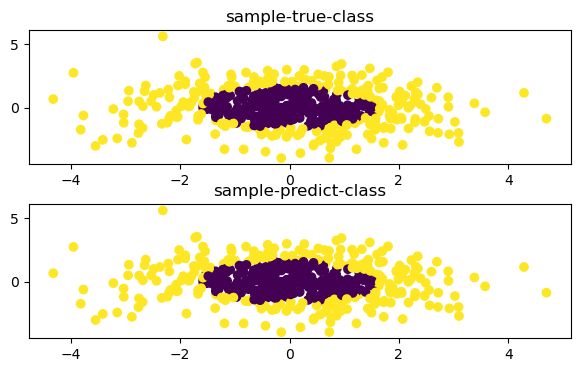
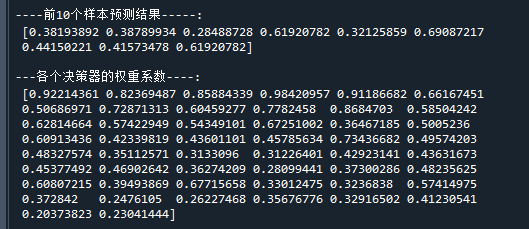
从图中可以看到,模型的预测类别与真实类别几乎是一致的。
总结
与随机森林这些算法一样,AdaBoost随着Xgboost的出现,渐渐退出了舞台,但由于历史原因,在机器学习中各类模型,AdaBoost还是一个知名度较高的模型,这里只是大概地介绍它是什么、怎么用,而在一些原理细节上能省就省,毕竟,要把它说清楚,一张文章是搞不定的。
 评论
评论
