-
机器学习-模型
-
1.1.线性模型
-
1.2.分类模型
-
1.3.集成模型
-
1.4.降维算法
-
1.5.聚类算法
-
- 神经网络-模型
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【模型】一篇入门之-朴素贝叶斯-模型
朴素贝叶斯模型(Naive Bayes model)是最经典的机器学习的模型之一了,一般机器学习都把它当作入门模型之一,即使一般人没真正坚持把机器学习的内容学下去,也会在入门教程中接触它,那今天我们就来看看朴素贝叶斯是个什么样的模型吧,包括模型的推导原理、模型表达式、以及具体的使用例子。
一、朴素贝叶斯模型
我们不妨先来简单地了解一下朴素贝叶斯模型,然后再去了解它的原理,以及具体例子,一步步的上手它。
1.1. 初识-朴素贝叶斯模型
好了,先来简单了解下朴素贝叶斯模型。
朴素贝叶斯模型,是一个用来判别样本类别的模型,它的模型原理如下:
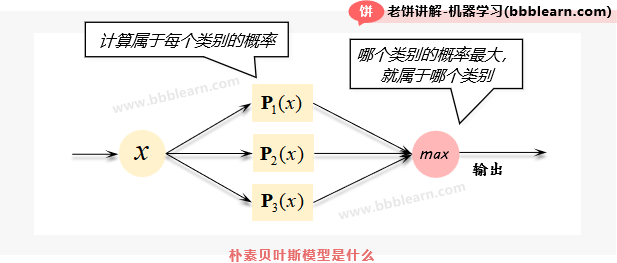
如图所示,它先计算出样本属于各个类别的概率,然后哪个类别的概率越大呢,那就判别样本属于哪个类别。好了,现在问题来了,对于类别i,它的概率应该是多少?这就不得不提贝叶斯原理了。
1.2. 贝叶斯原理
贝叶斯原理是什么呢?贝叶斯原理是指,在已知发生B条件下,发生A的概率为:
大家不用害怕这条公式,解说一下就非常容易理解了。
我们不妨将右边的分母移到左边,则贝叶斯原理理变为:
也就是: 发生B,且发生A = 发生A,且发生B,这就非常容易理解了。
1.3. 朴素贝叶斯模型
上面说到,我们希望知道样本属于类别k的概率,现在有了贝叶斯原理,我们就可以开始干活了。
已知样本表现为X特征,想知道它属于类别 k 的概率,套用贝叶斯原理可得到:

但是呢,上式中P(X)比较难知道,所以进一步地,假设各特征之间相互独立,那么特征的概率可以拆成累积形式,从而得到:

好了,上面每一个量都是容易计算得到的,这样我们就得知道样本X属于类别k的概率了。
这就是朴素贝叶斯模型了,它的"朴素",指的就是"各特征间互相独立"这一条件。
1.4. 朴素贝叶斯-判别公式
虽然我们可以通过上式,来具体得到样本X属于各类别的概率,但是,最终比较的是各个类别概率的大小,而每个类别的概率公式的分母是一样的。所以其实可以忽略掉分母,也就是只需取上述概率公式中的分子部分作为判别公式,来进行结果比较就可以了,这样就得到了朴素贝叶斯的判别公式如下:

在实际中,我们一般都是使用朴素贝叶斯的判别公式,而不是概率公式,毕竟可以省事不少。而且,朴素贝叶斯的"特征互相独立"条件在实际中很难达到,这会导致直接使用概率公式计算出来的概率之和不为1,而实际中更常用的做法是,使用判别公式来得到判别值,再把判别值进行归一化,从而得到概率。
二、朴素贝叶斯模型-例子讲解
上面说了一大堆的原理,其实抽象得很,下面我们拉一点数据出来,具体看看怎么用朴素贝叶斯模型来判别样本的类别,这样就具体形象多了。
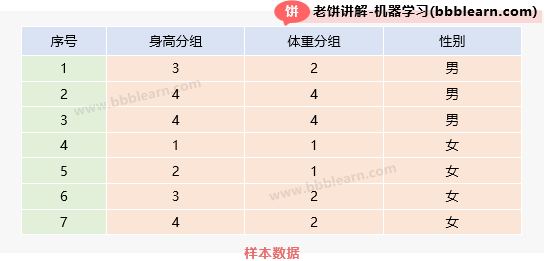
2.1. 朴素贝叶斯-样本数据
现有身高、体重与性别的历史数据如下
2.2. 朴素贝叶斯-模型构建
如前面所说,我们就用朴素贝叶斯的判别公式来判别类别,而不是概率公式。
好了,在朴素贝叶斯的判别函数中,要用到与,所以我们要根据历史样本先统计出与,统计出这两个东西,其实也就构建好了朴素贝叶斯模型,就等着新样本来预测就可以了。好了,下面来统计一下与分别是多少。
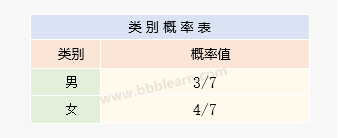
一、计算各个类别的概率
各个类别在总样本的占比就是,统计样本数据可得:
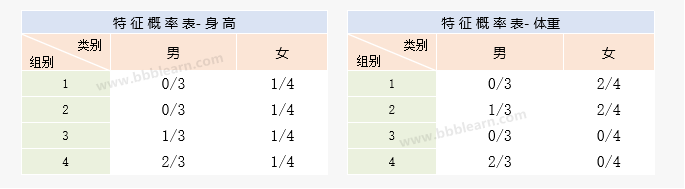
二、计算知道类别时不同特征表现的概率
使用各个类别在X的不同取值时的占比来估算就可以了,统计样本数据可得:
2.3. 朴素贝叶斯-模型预测
下面就可以使用上面构建好的朴素贝叶斯模型来对新样本进行预测了,这里再次贴出判别公式:
不妨设现在新样本的身高分组为3,体重分组为2,那么样本的性别概率是多少呢?
通过查表,就可以算得,样本属于男、女的判别值为:
由可知,该样本性别为女的可能性更大。
如果需要概率,还可以进一步将判别值进行归一化,可得:
也就得到,样本属于男、女的概率分别为0.4、0.6。
三、朴素贝叶斯模型-代码实现
好了,上面是手算的例子,下面我们讲讲在python中怎么用sklearn来实现一个朴素贝叶斯模型。
下面我们以iris数据为例,然后调用sklearn的GaussianNB函数来实现朴素贝叶斯分类,代码如下:
'''
本代码展示如何用sklearn实现朴素贝叶斯模型
本代码来自《老饼讲解-机器学习》 www.bbblearn.com
'''
from sklearn import naive_bayes
from sklearn.datasets import load_iris
iris = load_iris() # 加载数据
X = iris.data # 用于建模的X
y = iris.target # 用于建模的y
clf = naive_bayes.GaussianNB() # 初始化贝叶斯模型
clf = clf.fit(X,y) # 用数据训练树模型构建
y_pred = clf.predict(X) # 对样本进行预测
print("\n样本的真实类别:",y) # 打印样本的真实类别
print("样本的预测类别:",y_pred) # 打印样本的预测类别
print("模型准确率:",(y_pred==y).mean()) # 打印准确率代码运行结果如下:
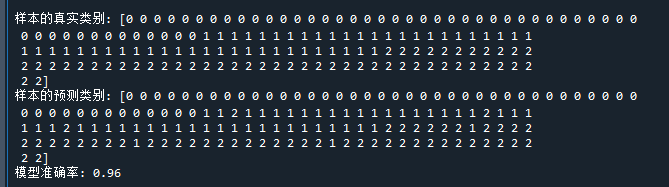
好了,可以看到,朴素贝叶斯模型对样本的分类基本都是准确的,准确率96%。
总结
朴素贝叶斯模型就是利用贝叶斯原理,来估算出样本属于各个类别的概率。而为了更易于估算,所以加入了"特征相互独立"这一朴素条件。在构建模型时,只需要根据历史数据,统计出"各个类别的先验概率"和“知道类别时不同特征表现的概率”就可以了,使用时根据公式进行查表计算,就能得到样本属于各个类别的概率了。
 评论
评论
