-
机器学习-模型
-
1.1.线性模型
-
1.2.分类模型
-
1.3.集成模型
-
1.4.降维算法
-
1.5.聚类算法
-
- 神经网络-模型
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【降维】一篇入门之-PCA-主成分分析
PCA主成分分析(Principal Components Analysis)主要用来去除变量之间的线性冗余信息,使得它们变为独立变量,在机器学习中几乎无处不在,因为什么项目、什么数据都可以用它来搞一搞,那么我们今天就来看看PCA主成分分析是什么吧,并说说PCA在实际应用中的操作过程与例子。
一、PCA主成分分析
要一步到位的说清楚PCA有些难,我们就一步一步来理解就好了,到后面自然就会对它一清二楚了。
1.1. PCA的背景-变量相关
在我们的数据中,往往数据都会存在或多或少的相关性,而有时会特别严重,如下:
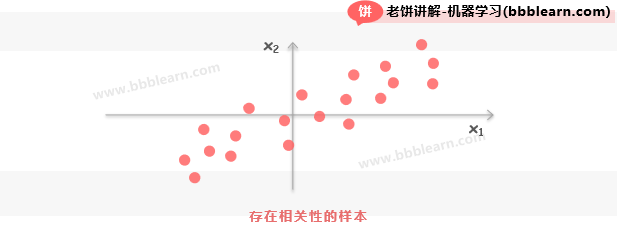
可以看到,和之间,明显就是相关的,如果直接拿去建模,或者使用,那变量之间的信息就会重叠,干扰我们对数据的分析和建模。那怎么办呢?这时候就是PCA出场的时候了。
1.2. PCA-初步理解
PCA干了什么呢?PCA找了新的坐标轴来表示数据,使得变量之间相互独立,如下:
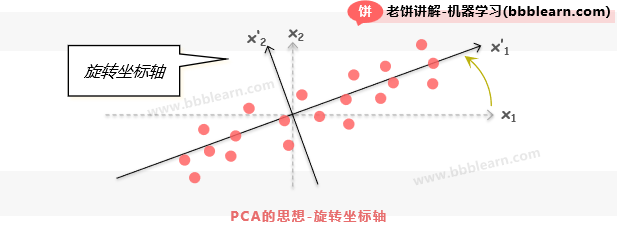
如图所示,如果按原有坐标,那和是具有强烈的相关性的,但是如果旋转坐标轴后,以作为坐标轴,那么样本就相互独立了。事实上,还可以换一个视角来看,就是对样本进行旋转,使样本旋转后维维相互独立,如下:
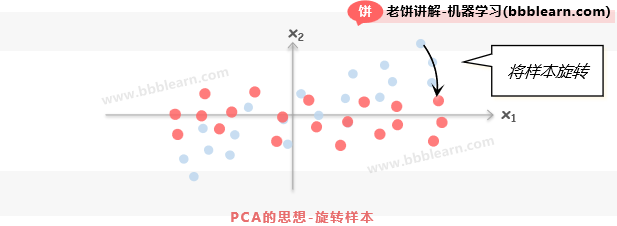
不管是旋转坐标轴,还是旋转样本,都是一样的道理,而且在数学上最终推导得到的模型表示都是一样的,但旋转样本的推导更加简单一些,所以我们这里就不妨用旋转样本来理解好了。
1.3. PCA-数学表述
好了,我们用数学来表述一下PCA,首先PCA是保角保长地旋转样本,而保角保长旋转变换,在代数中就是一个标准正交矩阵A,所以呢,PCA的数学表述如下:
其中,是标准正交矩阵,则是的均值中心,是旋转后的坐标
这公式应该很形象,就是先对进行中心化,再进行保角保长的旋转。
其实不进行中心化处理也是可以的,但一般都会加入中心化处理。
好了,别忘了,我们要求旋转后,维维之间相互独立,用数学来表述,也就是Y的协方差矩阵为对角矩阵:
其中,代表对角矩阵
这个公式应该也很形式,就是要求Y的协方差是一个对角矩阵,这样使得Y的不同维之间协方差两两为0。
好了,我们来整理一下,也就是要求一个标准正交矩阵A,它必须满足,而在求出A后,就可以用A来旋转了,最终就能得到样本旋转后的新坐标,它维维之间相互独立。
好了,这就是PCA了吗?可以这么说,但其实这才是PCA的开始呢!让我们继续一步一步了解PCA吧!
二、PCA的主成分与贡献
接下来就要说一些名词了,主成分、主成分系数、主成分贡献,先来搞懂这三个东西分别是什么。
2.1. 主成分与主成分系数
ok,上面说到,PCA就是对样本进行旋转,使得旋转后维维互不相关,忽略掉中心化,它的表示为:
更详细的形式则是:
那么, 旋转后得到的,两两之间协方差为0,但各自仍然会有各自的方差。一般来说,PCA在求解时,会调整系数的排列,使得的方差最大、的方差次大,...,如此类推,也就是按方差从大到小排列,为什么要按方差排列呢?不要急,下面再来说。
好了,就分别称为第一主成分、第二主成分、...、第n主成分,也就是方差最大的就是第一主成分,其次是第二主成分,这样子。

对应地,第一主成分的系数就称为第一主成分系数,第二主成分的系数就称为第二主成分系数,如此类推。
主成分与主成分系数这些都是名词约定,没有那么多为什么,就只是这样约定来称呼而已。
2.2. 主成分贡献
好了,知道了主成分,就可以来说主成分贡献了,这是个好东西!要了解什么是主成分贡献,就要先了解主成分的方差的意义,如下:
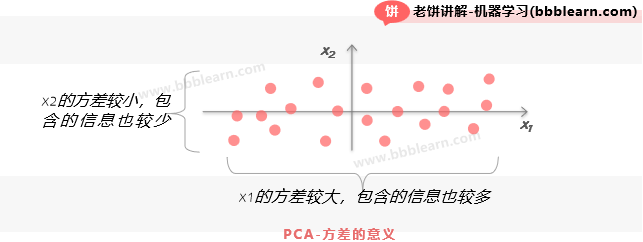
如图所示,样本旋转后,维维互不相关,那么,方差越大的维,就代表该维所包含的信息越多。
刚开始学时,我很纠结,为什么主成分的方差越大,它所包含的信息就越多,后来极端点去想就理解它了,假设样本在某维上方差为0,也就是所有样本在该维上都是一样的,那这个变量(也就是这一维)就没什么意义了。所以,方差越大,代表该维包含的信息越多。
好了,知道主成分的方差可以用来衡量它包含样本信息的"量",那么将所有主成分的方差进行归一化,就是主成分的贡献了,假设某个主成分的贡献为65%,就代表着它包含了样本65%的信息。
三、如何使用PCA
好了,上面铺垫了那么多,其实都还没说实际中怎么使用PCA,通过这一小节,我们具体知道PCA怎么用了。
在实际使用中,PCA一般有两个用途,一个是用来分析变量,另一个是对变量降维。
3.1. PCA-分析变量
一般来说,我们有一堆建模变量,这时候往往就要看下变量去掉信息冗余后到底是个什么情况了。
首先,我们要先对变量进行PCA转换,然后计算出主成分贡献,以及累计贡献,也就是计算出下表:
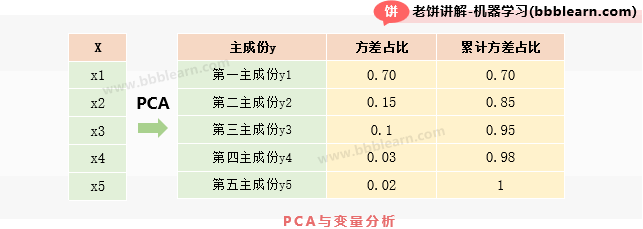
如图所示,先获得主成分的方差,然后方差占比就是主成分贡献,再计算累计贡献就可以了。
从上表可以看到,X中70%的信息由表示,而剩下信息基本由表示,因此,X虽然有5个变量,但实际信息只有3个变量,说明 X中存在较多的信息冗余。
3.2. PCA-降维
主成分降维也是建模中常用的方法,还是上面的例子,如下:
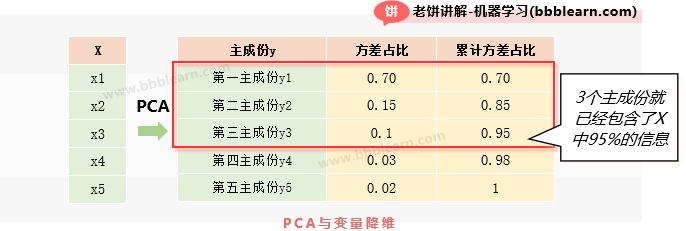
从表中可以看到,只需要取前3个主成分时,主成分总贡献就已经达到了95%,因此,可以忽略掉其它次要的主成分,只取前3个主成分来代表原来的样本数据就可以了,变量过多易引起模型过拟合,通过PCA降维后再进行建模,模型效果往往会得到改善。
四、PCA主成分-代码实例
好了,这回我们是真的拉一点数据出来玩玩PCA了,并且看看代码具体是如何实现的。
哈哈哈,为简单起见,我们仍然是把iris数据拉出来当学习对象,我们知道,iris共有4个变量,如下:
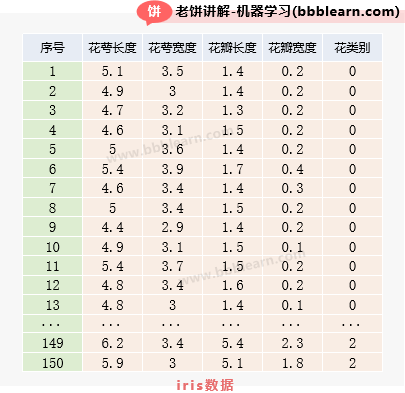
下面我们来对iris数据进行PCA分析,看看它的变量之间信息冗余严不严重,闲话少说,直接上代码:
"""
本代码用于展示如何对iris数据进行主成份分析
本代码来自《老饼讲解-机器学》www.bbblearn.com
"""
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
import numpy as np
# 加载数据
iris = load_iris() # 加载iris数据
X = iris.data # 样本X
x_mean = X.mean(axis=0) # 样本的中心
# 用PCA对X进行主成份分析
clf = PCA() # 初始化PCA对象
clf.fit(X) # 对X进行主成份分析
# 打印结果
var = clf.explained_variance_ # 方差
Pr = clf.explained_variance_ratio_ # 方差占比
print('主成份系数矩阵A:\n A=',clf.components_) # 打印主成份系数
print('主成份方差 var:',var) # 打印主成份方差var
print('主成份贡献 Pr:',Pr) # 主成份贡献占比(方差占比)Pr
print('主成份累计贡献 PrCum:',np.cumsum(Pr)) # 打印主成分累计占比
# 获取主成份数据
y = clf.transform(X) # 通过调用transform方法获取主成份数据
y2 = (X-x_mean)@clf.components_.T # 通过调用公式计算主成份数据代码运行结果如下:
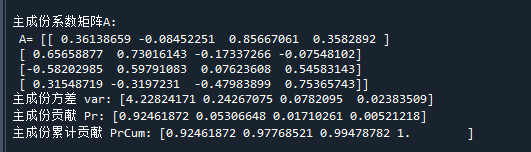
可以看到,经过PCA转换后,第一主成分贡献达到92.4%,第二主成分贡献占比为5.3%,这说明iris数据的4个变量存在严重信息冗余,它们的信息大部分可由第1、2主成分表示。如果需要对其进行降维,可以只取前两个主成分y1,y2,它们的累计贡献已达到97.7% 。
总结
主成分分析,就是将变量进行线性转换,使得转换后得到的主成分之间两两独立,可以说主成分分析就是去除原始变量之间的信息冗余,使得信息更加纯粹。它主要有两个作用,一个是用来分析原始数据中的信息构成,另一个是用来对变量进行降维。使用时先将X转换为主成分,然后统计出每个主成分的累计贡献,再进行分析或降维就可以了。
 评论
评论
