-
机器学习-模型
-
1.1.线性模型
-
1.2.分类模型
-
1.3.集成模型
-
1.4.降维算法
-
1.5.聚类算法
-
- 神经网络-模型
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【模型】一篇入门之-DBSCAN聚类算法
DBSCAN(Density-Based Scan)聚类是一种基于密度扫描的聚类方法,它的核心思路就是通过样本点找样本点,最后把能找到的样本点串连在一起变成一类,它的特点就是不受样本分布形状的限制,且具有较强的抗噪性,好了,下面就来正式说说DBSCAN聚类的原理和算法流程,然后展示一个具体的代码实现例子。
一、DBSCAN聚类-初识
玩聚类的朋友或多或少都会想过,能不能从样本点出发,让样本点一个找一个,最后把找到的样本都归为一类,事实上,DBSCAN聚类就是这么干的。
好了,我们先看一下DBSCAN的聚类效果,然后再讲它的原理和算法流程。
1.1. DBSCAN-聚类效果
DBSCAN聚类的出发点就是"朋友找朋友",所以它不像kmeans这些算法,只能对球状数据进行分类,DBSCAN聚类完全不受样本分布的影响,不管是什么分布,它最后都能区分出来,我们先来看一下DBSCAN的聚类效果:
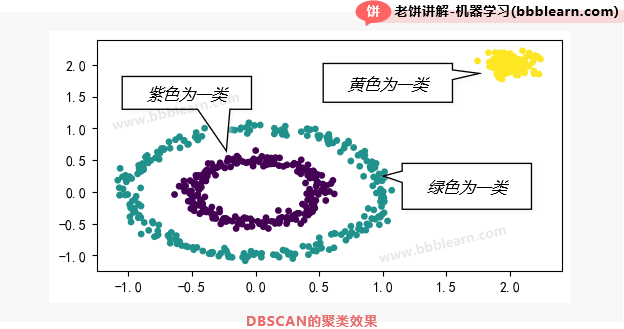
如图所示,由于DBSCAN是"朋友找朋友",所以它最后会把内圈、外圈样本各分为一类。事实上,它不仅不受样本的形状约束,它还具有极强的抗噪性,理由很简单,即使有一些孤立点,也会因为"没有朋友",所以被孤立出来,而不影响其它样本的聚类。
1.2. DBSCAN聚类-核心原理
好了,上面我们说DBSCAN就是"朋友找朋友",那到底是怎么一回事呢,我们先来上一个图:
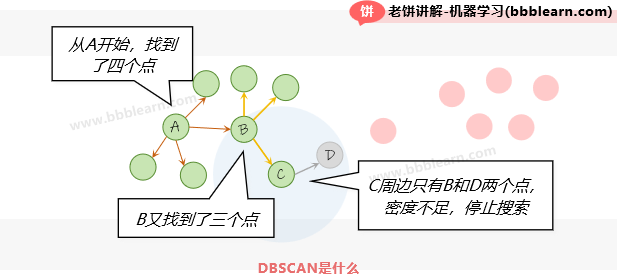
如图所示,DBSCAN从样本A出发,近邻找近邻,直到找到C时,C密度不足,就停止搜索,特别说明的是,D这时候也是被找到了的,也归属于这一类别,只是不会让D继续去找近邻而已。
到了这里,我们就明白DBSCAN(Density-Based Scan,基于密度扫描)名字的由来了,它这里的"基于密度"其实包含了两个机制,一个是"朋友找朋友"的本质就是基于密度,另一个是当密度不足时终止扫描。
二、DBSCAN-聚类算法流程
好了,DBSCAN的聚类思想其实是很简单的,但真正去实现这一思想,就会发现非常多的细节,所以理解DBSCAN的思想不难,但理解整个DBSCAN算法就会略为繁琐,但不用担心,我们一步一步来搞定它们就行了。
2.1. DBSCAN的术语与定义
为了方便理解DBSCAN算法的细节,先来描述一些DBSCAN的定义和术语。
一、DBSCAN的参数
DBSCAN有两个参数:半径 和 最小样本数。
二、样本点的类型
DBSCAN的样本点类型包括核心样本点、边界样本点和噪声样本点三种,先来上个图:
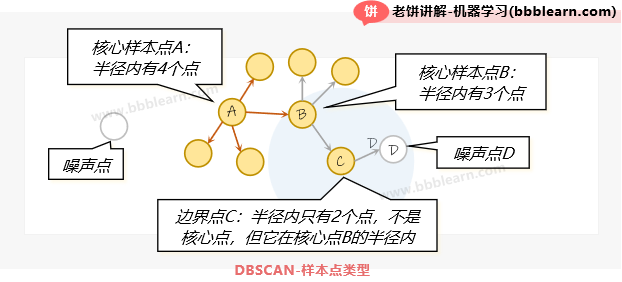
核心样本点:如果样本的半径内的样本个数最小样本数,则称为核心点。
核心样本点代表密度足够,核心样本点允许扩散,继续搜索它的近邻点。
边界样本点:不是核心样本点,但在其它核心样本点的半径内
边界样本点可以被核心样本点搜索到,但不会进一步搜索它的近邻点。
噪声样本点:既不是核心样本点,又不在其它核心样本点的半径内
噪声点不会被核心样本点搜索到,是较为孤立的点。
三、样本点的关系
好了,下面继续说下样本点与样本点之间的关系。
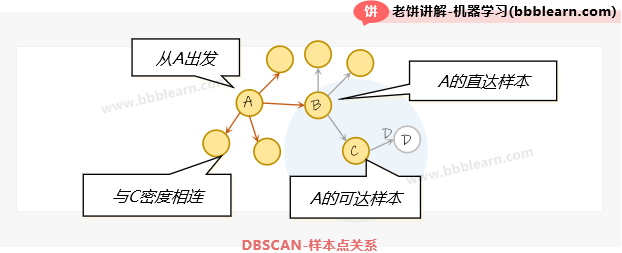
密度直达 :是核心点,在的范围内,则称到是密度直达的
密度直达代表可以通过p直接找到q
密度可达 :如果到可通过一连串的密度直达连接,则称到是密度可达的
密度可达代表可以通过可以找到
密度相连 :如果到都是密度可达的,则称密度相连
密度相连代表p,q能同时被某个点o找到
2.2. DBSCAN聚类流程
好了,有了上面的术语,就可以一起来说说DBSCAN具体是如何聚类的了。
总的来说,DBSCAN聚类从一个样本点p出发(p必须是核心点,边界、噪声点根本出发不了),通过密度直达不断传播,直到边界点样本点为止,本次找到的所有样本归为一个类别。
可知,在DBSCAN算法中,所有与p密度可达的样本都会被找到,样本之间的允许的最大跨度是"密度相连"。
DBSCAN的详细算法流程如下:
一、初始化所有样本均未被访问过
二、对所有样本点进行历遍:
1. 如果样本已被访问过:
继续下一个样本。
2. 如果不是核心样本点:
将样本标为噪声,并标记样本已被访问,继续下一个样本。
3. 如果是核心样本点:
创建一个类别
标记该样本已被访问
将样本的密度直达样本放到搜索队列
历遍搜索队列样本 :
样本还没有类别,则标上当前类别
如果样本被访问过,继续下一个样本
标记样本被访问
如果是核心点,将样本的密度直达样本放到搜索队列,并去重
(备注:后期会有许多样本已被访问,因此在放上队列前可先作筛选)
三、输出最终每个样本的分类
好了,以上就是DBSCAN的算法流程了,事实上比较难直接理解,需要紧扣DBSCAN的思想,慢慢琢磨才能明白它的意思,这里就不详细讲解了。
三、DBSCAN聚类-代码实现
说了那么多DBSCAN的原理,这里我们就拉点数据出来玩一下DBSCAN,事实上我们使用时,只需要调用sklearn的cluster.DBSCAN函数就可以了,下面是一个代码例子:
'''
本代码展示如何用sklearn实现DBSCAN聚类
本代码来自《老饼讲解-机器学习》 www.bbblearn.com
'''
import numpy as np
import matplotlib.pyplot as plt
from sklearn import cluster
from sklearn import datasets
# 成生数据
X1, y1 = datasets.make_circles(n_samples=500, factor=.5,noise=.05) # 生成同心圆数据
X2, y2 = datasets.make_blobs(n_samples=100,n_features=2 # 生成正态分布数据
,centers=[[2,2]],cluster_std=[[.1]],random_state=0)
X = np.concatenate((X1, X2)) # 将X1,X2一起作为X
# 对样本进行聚类
clf = cluster.DBSCAN(eps = 0.2,min_samples=12) # 初始化DBSCAN聚类模型
y_pred = clf.fit_predict(X) # 对样本进行聚类
plt.scatter(X[:, 0], X[:, 1], c=y_pred, s=20) # 绘画结果
plt.show() # 展示画布运行结果如下:
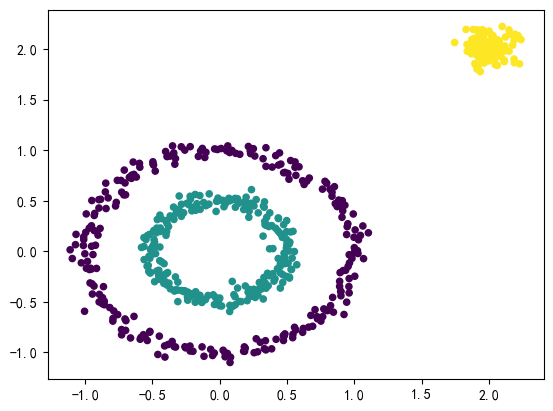
可以看到,样本已经很好地进行聚类,这体现了DBSCAN并不受形状的影响,需要注意的是,DBSCAN是很受min_samples 和eps 两个参数的影响的,使用时需要多次尝试和调整。
总结
DBSCAN聚类算法就是一种基于密度扫描的算法,如果通俗地说,那它就是通过"朋友找朋友"这样的机制,来把邻近的样本点都聚为一类。它的特点是不受样本分布形状影响,而且抗噪能力强。
 评论
评论
