-
机器学习-模型
-
1.1.线性模型
-
1.2.分类模型
-
1.3.集成模型
-
1.4.降维算法
-
1.5.聚类算法
-
- 神经网络-模型
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【模型】一篇入门-SOM-竞争神经网络
SOM全称为自组织竞争神经网络(Self-organizing Feature Map),是Kohonen提出的一种聚类模型,它的特色是先自定义一个拓扑结构(组织)来作为类别中心,然后竞争学习(competitive learning)策略来逐步优化拓扑结构各个节点的位置。好了,下面就让我们来正式的看看SOM神经网络到底是什么,以及它的代码实现。
一、SOM神经网络
SOM神经网络就是用来聚类的一种算法,要说它呢,就需要先了解kohonen规则。
1.1.kohonen聚类规则
kohonen规则是个啥呢?它是指按如下方法进行聚类的一种规则:
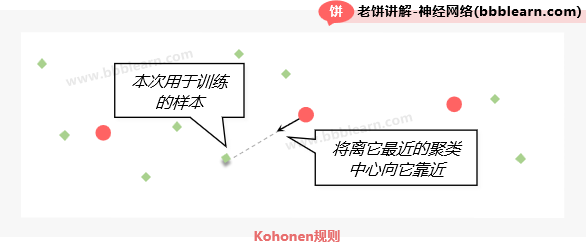
如图所示,先随机初始化k个聚类中心,然后每次选择一个样本,并把离它最近的聚类中心点往它移动,使聚类中心点更靠近它,如此反复迭代m次,这就是kohonen聚类规则了。
kohonen聚类规则每次都将聚类中心靠近样本x,用数学来表述就是:
其中
:离样本最近的聚类中心点
: 学习率
按上面的规则,经过反复更新聚类中心,训练了一定步数之后,得到最终的聚类中心,然后在有新样本时,就判断样本离哪个聚类中心点近,就将样本判为哪个类别。
kohonen聚类就是这么一回事了,它其实是一个很简单的聚类规则,但可以验证,它的确是行之有效的聚类方法,这里我们就不进行验证了,毕竟我们是来学SOM神经网络的,而不是学kohonen的。
1.2. SOM神经网络
好了,那么som神经网络又是什么呢?它其实就是kohonen的改进,那改进了什么呢,简单来说,就是更新离样本最近的聚类中心P时,会把P的邻近聚类中心也一起更新,只不过P的学习率要比邻近聚类点更大一些。
重点来了,刚开始学SOM时,我还以为邻近聚类中心就是目标聚类中心附近的聚类点,其实不是,SOM对这个“邻近聚类中心”其实是有自己的定义的,让我们慢慢道来。
SOM先引入一个拓扑结构,把所有聚类点连结在一起,然后籍此来定义距离。而用来连结SOM聚类中心的拓扑结构可以是一维的,二维的,三维的,或者更高维的,但一般都是用二维的六边形拓扑结构,如下:
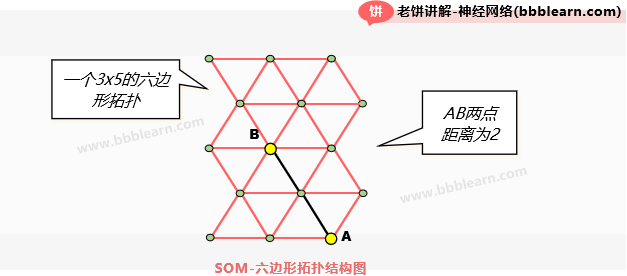
好了,有了这个拓扑结构,就可以定义聚类点与聚类点间的距离了,两点的距离指的是在拓扑结构中,这两点之间的最小边数,例如图中A、B两点的距离就为2。
有了距离,也就可以定义"邻近聚类中心"了,P的邻近聚类中心是指,与P的距离(也就是最小连结边数)小于某个阈值的聚类中心,例如,当距离阈值设置为2时,那么所有到达点P不超过2条边的聚类中心都是P的邻近聚类中心,所以,SOM中的邻近聚类点并不是用两点的实际距离来区分,而是按拓扑结构中的距离来区分。
二、SOM神经网络-模型结构
好了,经过上面的讲解,我们就知道SOM神经网络到底是怎么一回事了,下面我们再来熟悉一下SOM神经网络的拓扑表示,以及它的模型表达式。
2.1. SOM神经网络的拓扑结构与运算
我们知道,SOM神经网络就是一个聚类模型,它由多个聚类中心所构成,它的神经网络拓扑结构如下:
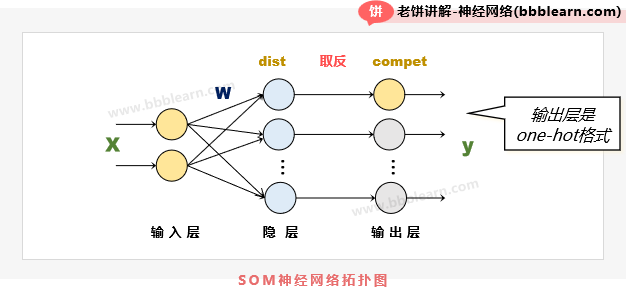
可以看到,它是一个三层的神经网络,其中,每个隐层节点就代表着一个聚类中心,而输入与隐节点的连接权重,就是聚类中心的位置,隐节点的值呢,就代表着输入x与该聚类中心的距离,所以第i个隐节点的值就是:
好了,输入经过隐层的运算后,也就得到了各个隐节点的值,也就是x与各个聚类中心的距离,进一步地,将距离取反,然后再进行竞争,哪个值最大,就认为是哪个类别,如下:
其中,compet是竞争函数,也就是将向量h中,最大的值置为1,其余置为0。
2.2. SOM神经网络-计算例子
好了,我们不妨拿点数据来具体计算一下,跟着下面的例子,就更明白整个SOM神经网络是怎么计算的了。
不妨设SOM神经网络为:2输入、3隐节点。
其中,输入和隐层权重如下:
,
W的每行,就行表着一个隐节点的权重,也就是一个聚类中心的位置。
那么,我们先来计算出隐节点的值:
进一步地,将隐节点的值进行取反并compet,如下:
compet后得到的向量是一种one-hot向量(只有一个元素为1),哪个值为1就代表属于哪个类别,所以从结果就可以看到,x属于第2个类别。
2.3. som拓扑结构-带隐层拓扑结构
往往我们会看到别人的SOM神经网络的拓扑结构如下:
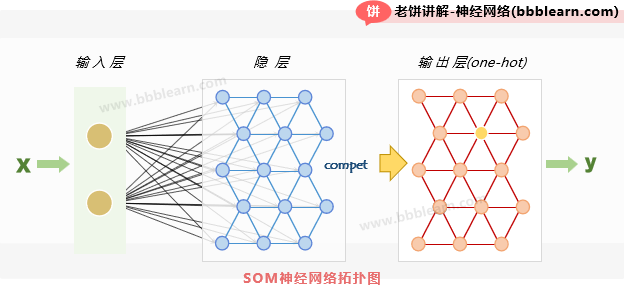
事实上,它是把隐层按隐节点的连接结构画在一起了,但经过上面的讲解,我们都知道隐节点的连接结构其实只是模型训练时,更新"邻近隐节点"时所使用的,训练完后这个隐节点的连接结构其实跟模型一点关系都没有,画这样的图只是显得更高大上,大家不要被迷惑了。
三、SOM神经网络-代码例子
好了,说了这么多,我们来个具体的例子,玩一玩SOM神经网络。
我们不妨先随机初始化一些样本点,然后调用matlab的神经网络工具箱训练一个SOM神经网络,来对这些样本点进行聚类。 具体代码如下:
% 本代码展示用matlab工具箱训练一个SOM神经网络
% 本代码来自《老饼讲解-神经网》 www.bbblearn.com
% 生成用于聚类的数据
rand('seed',70); % 随机种子,设定随机种子是为了每次的结果一样
dataC = [2.5,2.5;7.5,2.5;2.5,7.5;7.5,7.5]'; % 生成四个样本中心
sn = 80; % 样本个数
X = rand(2,sn)+dataC(:,mod(1:sn,4)+1); % 随机生成样本点
% 调用工具箱训练一个SOM网络
net = selforgmap([2 4]); % 建立一个SOM神经网络
net = train(net,X); % 训练网络
W = net.IW{1}; % 网络的权重,也即各个聚类中心的位置
y = net(X); % 用训练好的网络进行预测
classes = vec2ind(y); % 将预测结果由one-hot格式转为类别索引
% 绘图
plot(X(1,:),X(2,:),'*'); % 原始样本
hold on % 先hold on
plot(W(:,1),W(:,2),'or','MarkerFaceColor','g'); % 网络训练好的聚类中心
legend('样本','隐节点', 'Location','best') % 显示图例在代码中,使用selforgmap([3 5])来构建一个SOM神经网络,其中[3 5]指的是使用的二维拓扑隐层,所以共有个隐节点,当然,在我们这个例子了,样本很少,其实用这么多隐节点是过多了的,但作为演示,无伤大雅。
好了,代码运行结果如下:
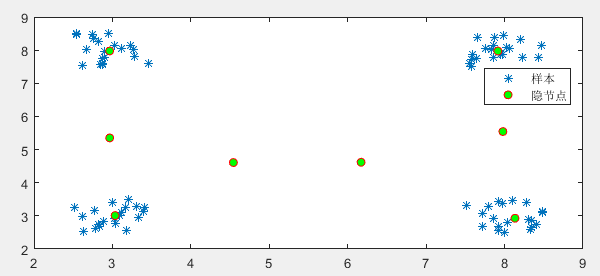
其中,绿色的隐神经元(聚类中心),蓝色的是样本,可以看到,每堆样本中,都有聚类中心覆盖到。
总结
总的来说,SOM就是一种基于kohonen规则的聚类算法,它的特点是将隐节点按一定的拓扑结构来连接,然后在更新的时候,把样本所属聚类中心的邻近节点也一起进行更新。在训练好SOM神经网络后,模型中隐层的权重就是各个类别中心的位置,在模型中输入样本,模型就会输出样本所属的类别。
 评论
评论
