-
机器学习-模型
-
1.1.线性模型
-
1.2.分类模型
-
1.3.集成模型
-
1.4.降维算法
-
1.5.聚类算法
-
- 神经网络-模型
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【模型】一篇入门之-Logistic逻辑回归
玩过机器学习的都应该知道逻辑回归模型(Logistic Regression),它不是最基础的模型,但却是最最最常用的一个模型,它一般用于做二分类,给出样本属于正样本的概率。今天我们就来说说逻辑回归的模型原理,包括逻辑回归的模型表达式、损失函数、训练原理、以及具体的代码实现例子。
一、逻辑回归模型
我们先看看逻辑回归用来做什么,长什么样,再来说它怎么训练、怎么实现,ok,开始!
1.1. 逻辑回归-用来干什么
首先,逻辑回归模型是用来干什么的呢?它是用来做二分类的,也就是判断样本属于类别0还是属于类别1的概率,如下,输入一个x,然后逻辑回归模型就给出它属于类别1的概率:

所以呢,逻辑回归就是一个分类模型,更准确来说,是一个二分类模型,它输出样本属于类别1的概率。
1.2. 逻辑回归-模型表达式
好了,我们来看看逻辑回归模型的表达式,如下:
一般来说,我们更喜欢把它写成如下形式:
其中 :
1.3. sigmoid函数
眼尖的同学会发现,逻辑回归模型,其实就是一个线性模型XW,再套上一个sigmoid函数,没错,就是这么简单,所以,我们不得不来说说,这个sigmoid函数到底是什么,先来看看它的图像:
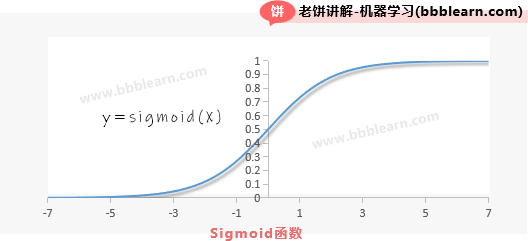
可以看到,sigmoid函数就是一个S型曲线,它的取值范围在(0,1)之间,当x=0时,它取值为0.5。
1.4. 如何理解逻辑回归模型
从逻辑回归模型的表达式可以看出,逻辑回归模型实际上是把WX作为样本属于类别1的判别值,也就是WX越大,样本属于类别1的概率就越大,然后呢,再套用一个sigmoid函数,来把判别值转换为概率:
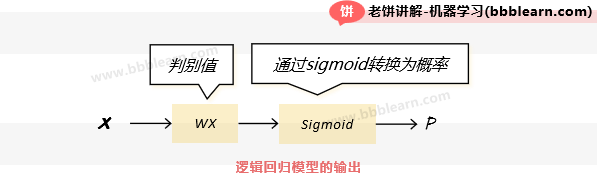
事实上,这个理解并不是逻辑回归最原理的意义,但是从模型表达式上,我们可以这样子浅湿地来理解,比较容易理解一些,入门就简单一点来就好了,不整那么多晦涩的东西。
二、逻辑回归模型的训练
2.1. 逻辑回归-损失函数
逻辑回归模型用交叉熵来作为模型的损失函数,如下:
其中,是样本个数,:第个样本的标签,要么是0,要么是1,是第个样本的预测概率
这个交叉熵损失函数是怎么来的呢,它可以根据最大似然推导出来,也可以直接由交叉熵的定义来得到,虽然损失函数是最小化,但它背后的意义呢,就是让模型对样本预测正确的概率最大化。
2.2. 逻辑回归-训练算法
逻辑回归的训练,也就是求解一个W,来令损失函数最小化,一般可以使用梯度下降法、牛顿法等等优化算法对逻辑回归进行训练。比较简单、经典的求解方法就是使用梯度下降算法了,梯度下降算法先初始化一个解,再不断往目标函数的负梯度方向调整解,如下:
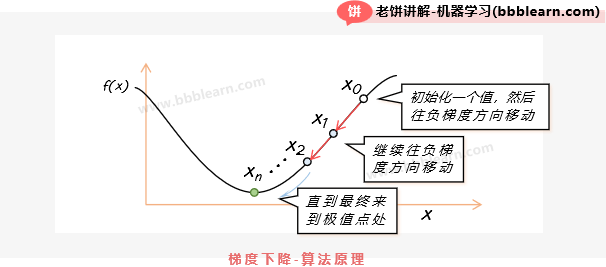
可以看到,梯度下降算法其实是非常简单的,只要计算出损失函数的梯度,然后再让W不断往负梯度方向调整就可以了,所以,一般在要训练前,先算出逻辑回归损失函数的梯度。
2.3. 逻辑回归-梯度公式
逻辑回归损失函数L(W)的梯度公式如下:
其中
:样本的输入特征数据,矩阵
n为特征个数,m为样本数,即一行为一个特征
: 样本的标签y,行向量
:模型预测值,即,的行向量
:模型的权重,的行向量
如果要自己实现逻辑回归的训练,那就必须要这个梯度公式了,但一般来说都直接调包来训练模型了,所以就用不着,先摆在这里,哪天想自己实现时就来拿。
2.4. 逻辑回归-训练流程
好了,最后我们来看下梯度下降算法训练逻辑回归的流程,虽然现在调包训练模型一般不用自己实现,但看看也方便了解一下原理。梯度下降训练逻辑回归模型的算法流程如下:
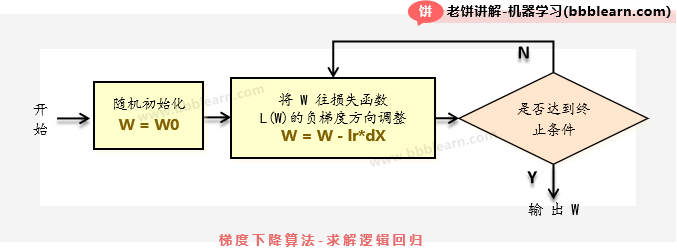
其实很简单,就是先初始化W,然后:
1. 按照梯度公式算出梯度
2. 将W往负梯度方向调整
不断循环(1)和(2),直到达到终止条件(例如达到最大迭代次数)
软件包中不一定使用梯度下降算法,例如matlab工具箱里使用的就是牛顿法,虽然牛顿法训练会更快,但原理也相对更为复杂,这里就不展开说了,浅尝即止。
三、逻辑回归-代码例子
好了,最后我们拉点数据出来玩一玩逻辑回归模型,我们就以sklearn自带的乳腺癌数据(breast-cancer)为例吧。乳腺癌(breast-cancer)共569条数据,如下:
特征:平均平滑度、平均紧凑度、平均凹面、平均凹点,类别:0-恶性、1-良性
原数据中有30个特征,这里作为学习,我们这里只选4个,然后用这4个特征来预测是恶性还是良性。好了,接下来我们在sklearn中使用LogisticRegression就可以实现一个逻辑回归了,具体代码实现如下:
'''
本代码展示在python中如何用sklearn来训练一个逻辑回归模型
本代码来自《老饼讲解-机器学习》www.bbblearn.com
'''
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
#----数据加载---------
data = load_breast_cancer()
X = data.data[:,4:8] # 这里只选择第5-8个变量
y = data.target # breast_cancer的y
#----数据归一化-------
xmin = X.min(axis=0) # 输入变量的最小值
xmax = X.max(axis=0) # 输入变量的最大值
X_norm=(X-xmin)/(xmax-xmin) # 对输入变量进行归一化
#-----训练模型--------
clf = LogisticRegression(random_state=0) # 初始化逻辑回归模型
clf.fit(X_norm,y) # 用数据训练逻辑回归模型
#------模型预测-------
pred_y = clf.predict(X_norm) # 预测类别
pred_prob_y = clf.predict_proba(X_norm)[:,1] # 预测属于1类的概率
# -----计算模型指标---
fpr, tpr, thresholds = metrics.roc_curve(y,pred_prob_y) # 计算fpr与tpr
auc = metrics.auc(fpr, tpr) # 计算auc
acc = (pred_y== y).sum()/len(y) # 计算准确率
# -----打印结果-------
print( "模型系数:",clf.coef_[0]) # 打印逻辑回归模型系数
print( "模型阈值:",clf.intercept_) # 打印逻辑回归模型阈值
print( "模型AUC:",auc) # 打印模型AUC
print( "模型准确率:",acc) # 打印模型的准确率可以看到,在代码中我们在训练前对数据进行了归一化处理,这是为了方便模型的训练。
代码运行结果如下:

逻辑回归模型一般用KS或AUC来评估模型的效果,这里可以看到,模型的AUC为0.955,对样本类别预测的准确率为89.8%,说明模型是有效的。如果将模型系数与阈值代入逻辑回归模型表达式,我们就可以得到模型的表达式为:
值得注意的是,由于我们训练时做了归一化处理,所以最后模型的表达式也是针对归一化后的数据的哦。
总结
总的来说,逻辑回归模型其实就是一个线性模型再套一层sigmoid函数,它是二分类模型之中最常用的模型之一,它输出的是样本属于类别1的概率,并使用了交叉熵作为损失函数,在训练时可以用梯度下降或牛顿法进行训练,评估时则用KS或AUC指标。
 评论
评论
