-
机器学习-模型
-
1.1.线性模型
-
1.2.分类模型
-
1.3.集成模型
-
1.4.降维算法
-
1.5.聚类算法
-
- 神经网络-模型
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【模型】一篇入门-BP后向传播神经网络
BP神经网络(Back Propagation Neural Network)是一种最经典的神经网络,它可以用来拟合任意X、y的关系,它原本称为MLP多层线性感知机,但由于它在训练时使用BP算法来计算梯度,所以就称为BP神经网络了,今天就来看看BP神经网络的原理,包括模型结构、损失函数、训练方法,以及具体的代码实现例子。
一、BP神经网络-模型结构
我们一步一步来,一点一点的到后面就会明白它是怎么回事了,好了,先来看看BP神经网络的结构。
1.1. BP神经网络-整体结构
BP神经网络呢,是一种多层前馈的模型,为了不抽象,我们先来看一个具体的BP神经网络模型,如下就是一个四层的BP神经网络拓扑结构:
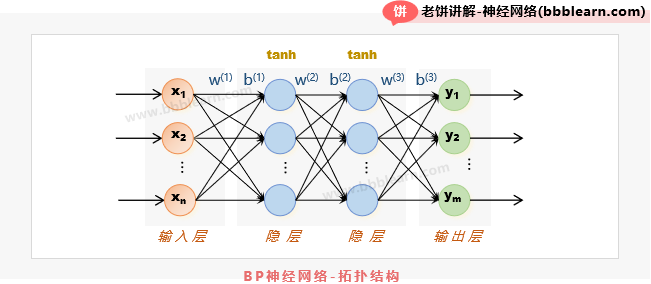
我们可以看到,它由输入层、隐层和输出层组成,而隐层呢,可以有多个隐层,如上图,有两个隐层,所以就组成了一个四层的BP神经网络。而每一层都是前馈计算,也就是前一层的输出,就是下一层的输入。由于输入层实际就只是X,所以如果抛开它不谈,那么模型其实只有3个计算层。在这里我们有个初步印象就好了,下面再一步一步弄懂它。
1.2.BP神经网络-单层结构-详述
其实从上面的结构图大家会发现,它每一层的结构都是类似的,所以只要弄懂一层的结构,也就基本知道整体结构了,好了,那单层的详细结构是怎么样的呢?如下:
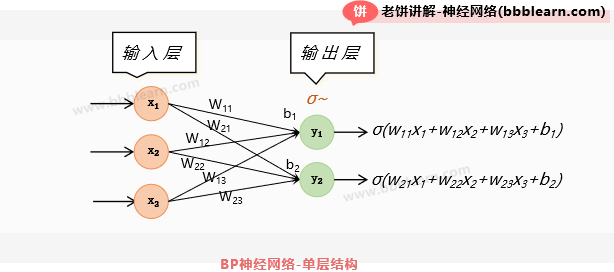
如图所示,每层都接收前层的输出作为输入,每个输入节点都与输出节点两两连接,一般把第j个输出与第i个输入的连接权重记为,而每个输出节点都有自己的阈值和激活函数,对于第j个输出节点,它的输出值为:
看到公式不要晕,我们解释一下就好了,它其实就是各个输入的加权和,再加上阈值,就是神经元的值了,然后再通过激活函数,就是神经元的输出值了。大家可以想象一下,就是神经元j以不同的权重接收到了各个输入,然后再加上神经元自身的阈值,这时候就是神经元的值了,但它传出去时还需要经过一层转换,所以总的来说输出节点j的输出值就如上式了,这就是BP神经网络的仿生原理。

好了,上面是单个神经元的输出,而整体则一般写为矩阵形式,也就是:
有的同学会问,这具体都是些什么,这其实是模型需要训练的参数,通过训练它们使得模型输出我们所期望的输出值,而激活函数则根据不同的层可以取为不同的函数,一般隐层的激活函数为tanh函数,输出层则是恒等函数:
1.3. BP神经网络-具体计算例子
好了,我们拉点数据出来,具体的计算一遍模型,就非常清楚它的结构和运算过程了,但是为了简便,所以我们这里以三层的BP神经网络(也就是只有一个隐层)为例子,如下:
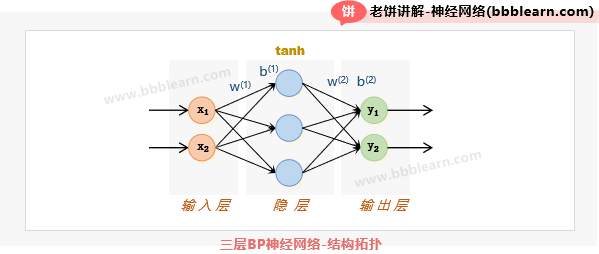
如图所示,有2个输入、3个隐节点、2个输出,其中,隐层的激活函数为tanh函数,输出层为恒等函数。
我们不妨设输入、隐层权重、隐层阈值、输出层权重、阈值如下:
下面我们就来计算一下模型最终的输出吧!
不妨先计算隐层的输出值,如下:
进一步地,将隐层作为输入,得到输出层的值为:
注意的是,输出层的激活函数是恒等函数,所以在计算时不需要考虑它。
好了,简简单单,朴素无华,这就是三层BP神经网络的模型结构和运算了,对于多层也是类似的,就只是这样一层一层的计算下去就行了。总的来说,BP神经网络的计算,就是一层一层的前馈,所以说BP神经网络是一种前馈模型,往往也把它的计算过程称为"前馈过程"。
二、BP神经网络-模型训练
相信通过上面的解说,大家都知道BP神经网络模型是怎么一回事了,也可以看到,模型里有很多权重、阈值参数,采用不同的权重、阈值,模型的输出就会不一样,而我们希望的是,模型的输出与我们的期望一致,所以我们就要训练模型的W、B了。以一个简单的例子,如下:
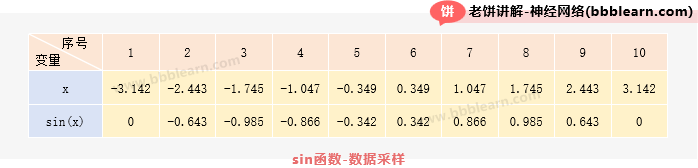
这是一个从sin函数中采集到的数据,我们希望模型学习到这个规则,使得在模型中输入x时,它输出的y与真实值sin(x)越相似越好,所以我们用以上的数据去训练模型,令模型在训练数据集上的MSE误差尽量的小:
BP神经网络的误差函数如下:
其中,:为训练样本个数
:为输出个数
:第i个样本第j个输出的预测值
:第i个样本第j个输出的真实值
直观来说,E就是所有样本、所有输出的平方误差的平均值
所以模型的训练,也就是求一个W、B令上述函数最小化了,一般会采用一些函数优化算法来达到这一目的。
2.2. 梯度下算法
函数优化的算法很多,较为简单的就是梯度下降算法。梯度下降算法的原理如下:
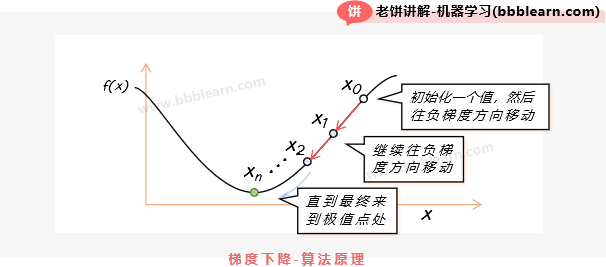
如图,它就是先初始化一个解,然后再令参数往目标函数负梯度方向不断调整,直到一定的迭代次数,或者梯度过小(梯度过小就意味着可能接近极值点了)。
2.3. BP神经网络训练流程
好了,将梯度下降法应用到BP神经网络,那么它的训练流程如下:
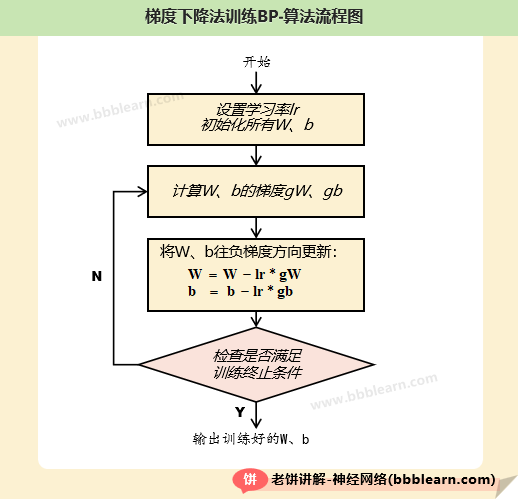
一、初始化
初始化各层的W、B
二、训练
逐步让W、B按的负梯度方法调整
1. 计算W、B在误差函数E的梯度gW,gB
2. 将W与B按负梯度方向调整
其中,lr是预设的学习率
3. 检查是否满足终止条件
满足终止条件,则退出训练
终止条件以下:
(1) 梯度是否过小
(2) 是否达到最大迭代次数
三、输出
输出训练好的W、B
可以看到,训练中就需要求误差函数E的梯度了,看起来就只是一个简单的求导,但是模型复杂了求导过程也就困难了,而比较幸运的是,有人提出了BP算法来计算梯度,为梯度计算提供了可行性,我们知道,模型的输出是从第一层开始逐层前馈的,而计算梯度恰好相反,是从最后一层开始逐层后馈,所以计算梯度的过程,也就称为"后馈过程"了。
三、BP神经网络-代码实现
好了,从上面我们就大概知道BP神经网络是怎么一回事了,下面我们拉点数据出来玩一玩。
3.1. BP神经网络例子-数据说明
我们不妨使用matlab自带的化学反应acetylene数据来玩玩BP神经网络,acetylene数据如下:
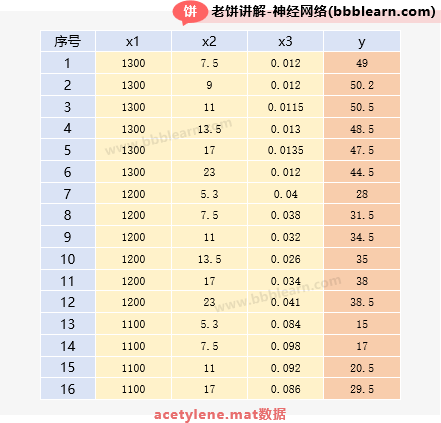
x1:反应器温度,x2:H2与正庚烷的比率(摩尔比),x3:接触时间(秒),y:正庚烷制乙炔的转化率(%)。
如表格所示,共16条数据,包含三个变量和一个,事实上我们也不用太纠结这些x和y到底是什么意思啦,反正知道就是要用三个来预测就好了。好了,下面我们就可以构建一个BP神经网络来实现化学反应转化率的预测了。
3.2. BP神经网络例子-代码实现
虽然我们也可以自己从0开始撸一个BP神经网络,但会比较麻烦,因为涉及到梯度的计算,所以一般都是使用matlab的神经网络工具箱来实现,不仅简单,而且在一些算法细节上的处理也比较到位,利用工具箱实现的效果比自己粗糙的自实现更为好一些。
在matlab中用newff函数就可以构建一个BP神经网络了,然后用train函数来训练模型,最后预测时使用sim函数就可以了,具体代码示例如下:
load acetylene.mat % 加载acetylene数据
setdemorandstream(88888); % 指定随机种子,这样每次训练出来的网络都一样
% 数据加载
X = [x1,x2,x3]'; % 将x1,x2,x3作为输入数据
Y = y'; % 将y作为输出数据
% 模型训练
net = newff(X,Y,4,{'tansig','purelin'},'trainlm'); % 初始化BP神经网络
net.trainparam.goal = 0.0001; % 训练目标:均方误差低于0.0001
net.trainparam.show = 400; % 每训练400次展示一次结果
net.trainparam.epochs = 15000; % 最大训练次数:15000.
[net,tr] = train(net,X,Y); % 调用matlab自带的train函数训练网络
% 模型预测
py = sim(net,X); % 调用matlab的sim函数得到网络的预测值
figure; % 新建画图窗口窗口
t = 1:length(py); % 数据的序号
plot(t,Y,'*',t,py,'o') % 画图,对比原来的y和网络预测的y
legend('真实值','预测值') % 展示图例代码运行结果如下:
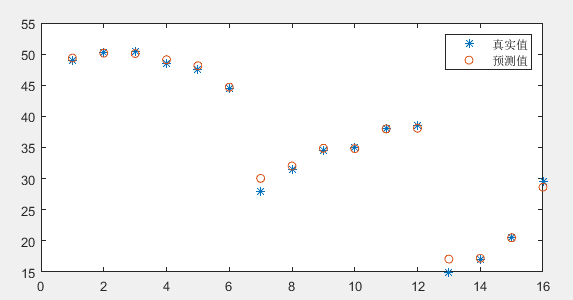
可以看到,我们的BP神经网络的预测值与样本数据的真实值基本是一致的,说明我们的模型训练成功了。
四、代码逐行解说
下面我们一起来逐行解说一下代码。
4.1. 代码解说-数据导入
首先看下1-5行代码:
第1行就是加载matlab的acetylene数据,它包含了和的数据。经过这一句代码,我们会看到我们的工作区中会增加了如下的数据:
第2行setdemorandstream(88888)则是设置随机种子,因为BP神经网络训练时,使用了随机数,如果不固定随机种子,每次训练出来的结果是不一样的,这里我是为了让大家能复现这个结果,所以随便设置了个随机种子88888。
第4行就是把合并在一起,作为我们训练数据的X。这里值得注意的是,matlab的BP神经网络要求X每一行代表一个变量,而原始数据中的都是列向量,所以我这里合并了之后,还要进行转置,所以这里最终X是的数据哦。
同样地,第5行把y作为我们建模使用的Y,而原始数据里的y是列向量,所以需要转置后再作为我们的Y。
总的来说,记住记住,matlab的BP神经网络,是每行代表一个变量哦~!
4.2. 代码解说-模型训练
好了,接下来我们看看模型训练的代码。

第8行是初始化一个BP神经网络,newff函数就是matlab里构建BP神经网络的函数了,其实新版本里已经不用这个函数了,但考虑到大部分的教材都仍然是newff函数,如果用新函数大家不容易找资料,所以这里我们仍然使用newff函数就好了。好了,newff函数第1、2个参数,就是我们的训练数据的X和Y了。然后第3个参数4代表的是隐节点个数,第4个参数{'tansig','purelin'}则代表第一个隐层用tanh函数,第二个隐层(其实就是输出层)用purelin函数,也就是恒等函数y=x,最后呢,我们选择了用trainlm算法进行训练,它所使用的就是LM列文伯格-马跨特算法进行训练,如果不设训练算法,那么默认也是用trainlm算法。
第9-11行是设置一些训练参数。goal=0.0001代表误差达到0.0001时就会停止训练,show=400代表每训练400步就会展示一次结果,而epochs=15000就是最多训练15000步。其实还有其它一些参数的设置,这里我们就这样简单设置一下就好了,随着我们的深入学习,我们再逐步讲解。
第12行就是正式训练模型了。好了,train函数共有三个关键入参,其中net就是我们上面初始化好的BP神经网络,而X,Y就是我们用来训练模型(也就是调整模型的参数)所使用的数据。然后经过train后,模型就开始训练了,训练完后就会返回net和tr这两个关键出参,其中net就是训练好的BP神经网络,tr是训练中的一些记录,就是train record的意思,tr具体的使用我们暂时先不管,以后用到再说。
好了,我们来总结一下,整体来说,第8行的newff是初始化模型,而第9-11行是训练前先设置好训练参数,真正用X、Y来训练模型是第12行的train函数。
4.3. 代码解说-模型预测
上面我们已经训练好模型了,下面我们来看看如何用训练好的模型进行预测。
第15行是使用训练好的模型net来对X进行预测,其中sim函数就是simmulate(模拟)的意思,sim(net,X)就会返回net对X的预测结果,曾经有几个同学问我,这个X是什么,这个X就是你想预测什么X就传入什么X,这里我们传入了所有X样本,最终就会得到所有X的预测结果。如果你想知道x1=1000,x2=2,x3=5时,y的预测结果,那么就需要传入x=[1000,2,5]'。
16-19行就是画图了,就是画出真实Y与预测Y的散点图,没什么好说的。
好了,代码基本就是这个意思了,事实上,对于模型的预测,我们也可以把net中的权重、阈值提取出来,再代入模型表达式来进行预测,毕竟BP神经网络就是一个函数嘛,但建模时我们一般直接使用sim函数来预测就可以了。
总结
总的来说,BP神经网络就是一种逐层前馈的模型,而它计算梯度时使用BP算法,所以称为BP神经网络。BP神经网络可以用来拟合各种x与y的关系,可以将它理解了一个任我们揉捏的模型,而要捏成什么样,就看我们的参数W、B了,一般会用优化算法来训练W、B,使得它与我们期待的输出一致。其实只要X,Y的关系比较明确,那么基本都是可以用BP神经网络来进行建模的,这就是BP神经网络了!
 评论
评论
