目录
- bbbrisk-简介与数据
-
bbbrisk-自动分箱函数
-
2.1.单变量-分箱
-
2.2.批变量-分箱
-
2.3.单变量-自动分箱-连续变量
-
2.4.单变量-自动分箱-枚举变量
-
- bbbrisk-编码函数
- bbbrisk-建模与报告
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【说明】函数说明-model._LogitModel类
作者 : 老饼
发表日期 : 2026-03-21 01:26:44
更新日期 : 2026-05-13 00:56:32
老饼讲解-简单易懂,干货满满,爽过嗦螺!
类对象说明:model._LogitModel - 逻辑回归模型类
model._LogitModel是逻辑回归模型类,由于_LogitModel属于内置类,它由model.scoreCard函数返回,因此,我们只介绍类的属性与方法,而不介绍它的构建方法。
一、类的属性
_LogitModel类拥有如下的属性:
var : 入模变量名称。
w : 模型权重。
b : 模型阈值。
w_norm : 模型归一化训练时的权重。
b_norm : 模型归一化训练时的阈值。
param_dict : 模型参数,字典格式,包含了w和b。
train_auc : 训练样本的AUC。
train_ks : 训练样本的KS。
test_auc : 测试样本的AUC。
test_ks : 测试样本的KS。
- 函数说明
由于逻辑回归模型在训练时,会先对数据进行归一化再训练,因此训练完后模型的权重、阈值为w_norm和b_norm,但是,我们应用时需要的是面向原始数据(未归一化的数据)的权重阈值,因此将模型参数进行反归一化,得到w和b。
二、类的方法
_LogitModel类只有一个方法:predict。
predict:预测函数,predict方法用于预测样本的概率和决策值(即wx+b)。
完整调用格式如下:
p,decision = logit_model.predict(x) # 这里的logit_model指的是一个_LogitModel类- predict-入参说明:
x:样本的变量数据。
数据类型:pandas.DataFrame
- predict-出参说明:
p:样本属于1类(即坏客户)的概率。
数据类型:pandas.core.series
decision:样本的决策值(即wx+b)。
数据类型:pandas.core.series
三、使用示例
model._LogitModel类使用示例如下:
import bbbrisk as br
data = br.datasets.load_bloan() # 加载数据
x,y = data.iloc[:,:-1],data['is_bad'] # 样本变量与标签
bin_sets = br.bins.batch.autoBins(x, y,enum_var=['city','marital']) # 自动分箱
logit_model,card = br.model.scoreCard(x,y,bin_sets,train_param={'random_state':0}) # 构建评分卡,并设随机种子为0
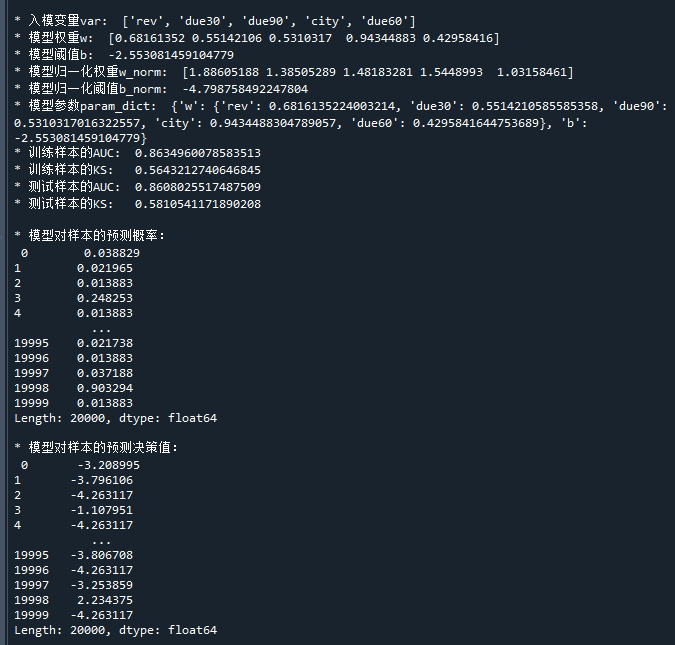
# 打印模型的属性
print('* 入模变量var: ' ,logit_model.var ) # 入模变量
print('* 模型权重w: ' ,logit_model.w ) # 模型权重
print('* 模型阈值b: ' ,logit_model.b ) # 模型阈值
print('* 模型归一化权重w_norm: ' ,logit_model.w_norm ) # 模型归一化训练时的权重
print('* 模型归一化阈值b_norm: ' ,logit_model.b_norm ) # 模型归一化训练时的阈值
print('* 模型参数param_dict: ' ,logit_model.param_dict ) # 模型参数,字典格式
print('* 训练样本的AUC: ' ,logit_model.train_auc ) # 训练样本的AUC
print('* 训练样本的KS: ' ,logit_model.train_ks ) # 训练样本的KS
print('* 测试样本的AUC: ' ,logit_model.test_auc ) # 测试样本的AUC
print('* 测试样本的KS: ' ,logit_model.test_ks ) # 测试样本的KS
# 用模型进行预测
p,decision = logit_model.predict(x[logit_model.var]) # 用模型进行预测
print('\n* 模型对样本的预测概率:\n' ,p) # 模型对样本的预测概率
print('\n* 模型对样本的预测决策值:\n',decision) # 模型对样本的预测决策值运行结果如下:
好了,以上就是model._LogitModel类的使用方法了~
 评论
评论
添加评论
- 教程
- bbbrisk
