目录
- bbbrisk-简介与数据
-
bbbrisk-自动分箱函数
-
2.1.单变量-分箱
-
2.2.批变量-分箱
-
2.3.单变量-自动分箱-连续变量
-
2.4.单变量-自动分箱-枚举变量
-
- bbbrisk-编码函数
- bbbrisk-建模与报告
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【说明】函数说明-bins.merge.ksEnum
作者 : 老饼
发表日期 : 2026-03-21 01:22:12
更新日期 : 2026-05-13 00:50:57
老饼讲解-简单易懂,干货满满,爽过嗦螺!
API说明:bins.merge.ks- KS分箱(枚举变量)
一、函数说明
bins.merge.ksEnum用于将枚举变量进行ks分箱,返回分箱的结果
ks分箱就是先将整体作为一个分箱,然后用KS作为切割依据,不断将分箱一分为二,直到分为目标箱数
原始的ks分箱只用于连续变量,而对于枚举变量,我们先将枚举值转换为badRate,从而适用于ks分箱
bins.merge.ksEnum的完整调用格式如下:
bin_set = bins.merge.ksEnum(x,y,bin_num=5,min_sample=None)- 入参说明
x:需要进行分箱的变量
数据类型:单列pandas.core.series或numpy.array
y:好坏标签,0为好,1为坏
数据类型:单列pandas.core.series或numpy.array
bin_num:目标分箱个数
数据类型:正整数
min_sample:最小样本个数
数据类型:正整数或None
min_sample=None时,它取值为样本数/5/3,这样一般会分为5个箱左右。
备注:KS分箱有终止条件(例如样本数过少),所以最终分箱数量不一定等于目标箱数。
- 出参说明
bin_set:等距分箱的结果。
二、函数示例
ksEnum使用示例如下:
import bbbrisk as br
# 加载数据
data = br.datasets.load_bloan() # 加载数据
x,y = data['city'],data['is_bad'] # 变量与标签
# KS分箱
bin_set = br.bins.merge.ksEnum(x,y,bin_num=5,min_sample=None) # 将变量进行KS分箱
bin_stat = br.bins.Bins(bin_set).binStat(x,y) # 统计分箱结果
# 显示结果
br.display.pd.set(width=300,max_colwidth=30,max_rows=30) # 美化pandas的显示方式
print('\n分箱结果:\nbin_set = ',bin_set) # 显示分箱结果
print('\n样本在分箱的分布:\n',bin_stat) # 显示样本分布运行结果如下:
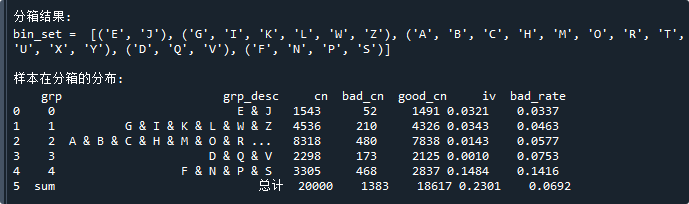
好了,以上就是bins.merge.ksEnum函数的使用方法了~
 评论
评论
添加评论
- 教程
- bbbrisk
