-
一、BP神经网络-简单上手
-
1.1.学前解说
-
1.2.BP的模型结构
-
-
二、BP神经网络-模型训练
-
2.1.认识BP的训练
-
2.2.梯度下降法-原理
-
2.3.梯度下降法-训练BP
-
2.4.过拟合与早停法
-
2.5.matlab工具箱-训练BP
-
-
三、胡乱玩一玩BP
-
3.1.BP神经网络-用于数值
-
3.2.BP神经网络-用于分类
-
3.3.BP神经网络-用于特征
-
-
BP入门-结束语
-
4.1.结束语
-
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【介绍】BP神经网络-说说归一化
之前我们已经说过,BP神经网络使用梯度下降法来进行训练。事实上,在训练时,我们一般会先对数据进行归一化,下面说说归一化是怎么一回事。
一、BP神经网络的数据归一化
1.1. 什么是归一化
BP神经网络归一化一般是指按公式将数据归一化到[-1,1]之间,而反归一化呢,则是把归一化后的数据,重新映射回原始数据,它是归一化的逆操作。如下所示:
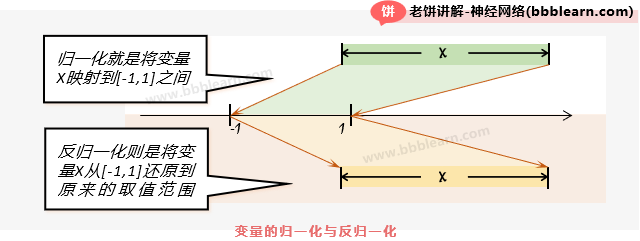
其实是很简单的一回事,就是把数据范围映射到[-1,1]与对应地将它还原到原始范围,我们也就不再多说了,如果不明白,继续看完下面的内容就自然知道了,就一个很简单的东西。
1.2. BP神经网络-归一化
什么时候用归一化,什么时候用反归一化呢?
一般来说,在训练时,我们需要把数据统一处理为归一化后的数据,也就是模型训练时,X,Y的范围都是在[-1,1]之间的。好了,我们来看下归一化的具体公式,如下:
其中,是原始数据,是归一化后的数据
使用上面的公式对数据进行归一化就可以了,需要特别注意的是,X和Y都是需要进行归一化的哦,归一化好之后,再用归一化后的数据来对BP神经网络进行训练。
那么问题就来了,这个模型是面向归一化的数据而训练出来的,所以在应用阶段呢,我们要对X进行预测时,也需要把X按上面的归一化公式来进行归一化,然后再用模型预测,但大家应该知道,这时候预测出来的y其实也是对应归一化数据的,所以,我们需要进一步将y进行反归一化,来还原成原始的y。而反归一化函数其实就是归一化函数的反函数,具体如下:
1.3. BP神经网络-归一化-总结
好了,大家可能有些乱,我们来整理一下,总的来说,就是分为训练阶段和预测阶段。
训练阶段将数据进行归一化后再训练,如下:
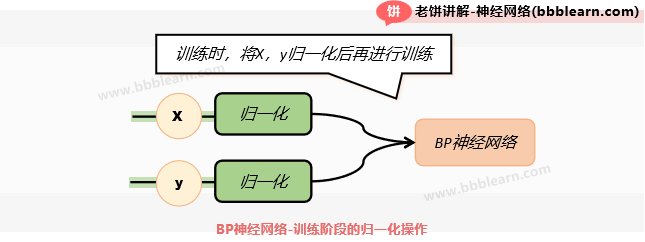
预测时输入进行归一化,然后再将输出反归一化,如下:
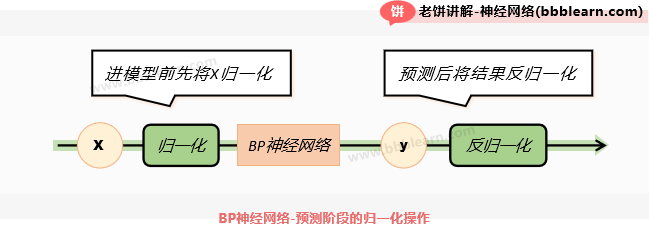
总的来说,就是训练时将数据进行归一化后再训练,预测时将输入进行归一化,然后再将输出反归一化。
二、归一化-具体示例
下面我们拿点具体的数据,来演示一下,大家就非常清晰归一化和反归一化的具体操作是怎么样的了。
2.1. 数据归一化-训练阶段
设我们原始训练数据如下:

由的最大值为8,最小值为-2,可求得归一化后的值如下:
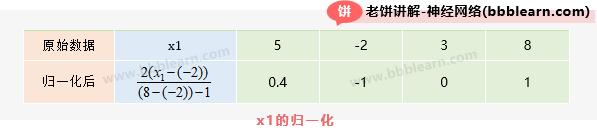
以同样的方法处理和,最终就得到归一化后的整体数据如下:

好了,做好归一化后,就用上面的数据去训练BP神经网络就可以了。
2.2. 数据归一化-预测阶段
在训练好BP神经网络后,那么就可以把模型投入使用中了。而在使用模型进行预测时,则要对输入进行归一化、并对输出反归一化。假设,我们要预测的输入为,则操作如下:
一、在预测前对输入进行归一化
由于的最大值为 8,最小值为 -2,的最大值为 6,最小值为1
那么归一化后的值为:
即预测时输入网络的值为: sim(net,[-0.2,-0.2])
二、将预测值(输出)进行反归一化
假设上面BP神经网络的预测值是0.5,由于这个0.5是归一化后的的预测值,要获得真实预测值,需要将它反归一化。由于在归一化时,的最大值为5,最小值为-5,则反归一后的 为:
也就是最终模型的输出为2.5。
三、其它的标准化方法
下面我们介绍一些其它标准化方法,其它常见的数据标准化方法还有min-max(最小-最大值归一化),z-score(零-均值标准化),但实际中,我们最常用的还是上面介绍的方法,好了,下面简单看下min-max和z-score标准化。
3.1. min-max归一化
min-max归一化公式如下:
稍微想一下就会知道,min-max归一化实际就是将数据规范到【0,1】之间。
3.2. z-score零-均值标准化
z-score标准化公式如下:
从公式就可以知道,z-score标准化就是将数据处理为均值为0,标准差为1,也就是统计意义上的标准化。
min-max就是将数据归一化到【0,1】,而z-score就是统计上的标准化。事实上这两种标准化方法很少用于BP,一般都是归一化到【-1,1】,这种对称性更易使输出集中在0附近,这样神经元更易处于激活区间。
总结
总的来说,BP的归一化就是先将数据每个变量都归一化到[-1,1]再进行训练,然后预测的时候也要用归一化后的X来预测,而模型输出的y则需要进一步反归一化,来得到原始数据的y。这里我们只讲归一化是如何操作的,至于为什么要归一化,主要是为了让模型训练效果更好一些,具体原因以后会讲到。
 评论
评论
