-
一、BP神经网络-简单上手
-
1.1.学前解说
-
1.2.BP的模型结构
-
-
二、BP神经网络-模型训练
-
2.1.认识BP的训练
-
2.2.梯度下降法-原理
-
2.3.梯度下降法-训练BP
-
2.4.过拟合与早停法
-
2.5.matlab工具箱-训练BP
-
-
三、胡乱玩一玩BP
-
3.1.BP神经网络-用于数值
-
3.2.BP神经网络-用于分类
-
3.3.BP神经网络-用于特征
-
-
BP入门-结束语
-
4.1.结束语
-
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【代码】梯度下降法-训练BP模型
我们已经学习了梯度下降算法了,那么这节我们就用它来训练一个BP神经网络,当然,事实上我们使用时是不需要真的自己去用梯度下降算法来训练BP神经网络的,因为工具箱已经提供了这样的功能给我们了,在这里只是为了学习理论更加踏实一点,所以就简单的展示一下,自己训练BP神经网络是怎么搞的。
一、梯度下降算法-训练BP神经网络
前面我们已经了解了梯度下降算法了,要用它来训练BP神经网络,那么也很简单,只需要初始化了BP的模型参数W、b,然后再按误差函数E的负梯度方向不断更新W、b就可以了,具体流程如下:
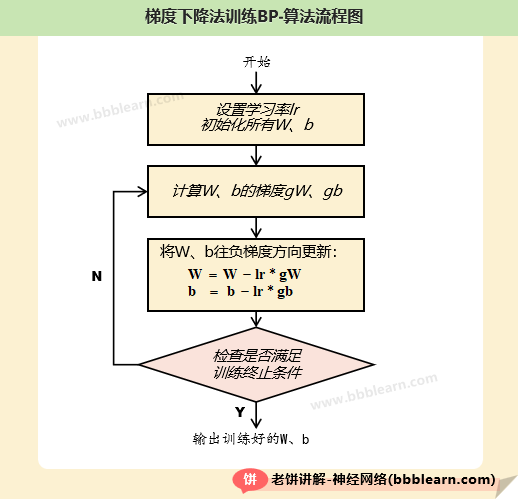
1. 先初始化W,b
2. 按照梯度公式算出梯度
3. 将W和b往负梯度方向调整
4. 不断循环(1)(2)(3),直到达到终止条件
终止条件为:达到最大迭代次数,或梯度足够小。
可以看到,流程其实非常简单,真正难点在于梯度计算,下面就来特别地说下BP的梯度是怎么算出来的。
二、BP神经网络-梯度的计算
好了,我们都知道,梯度下降算法训练BP神经网络,那么就必须求出参数在误差函数中的梯度。
2.1. BP神经网络-梯度计算-BP算法
事实上,对于多层BP神经网络,可以想象,它的模型表达式是层层嵌套的,层数多了,模型的表达式连写都写不出来,更别说求梯度了。所以一般它使用BP(反向传播)方法来计算梯度,这是什么意思呢,先来个图:
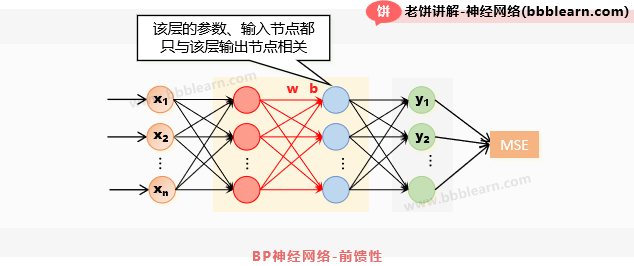
如图,对于任一层(不妨记为第k层)的权重、阈值,事实上只会直接影响该层的输出,最终误差E对于第k层参数的函数,可以把它看成是如下的复合函数:
因此,只需要用链式法则求梯度就可以了:
其中,是比较好求的,如此一来,只要知道节点的梯度,就很容易知道该层的参数梯度了。
- BP的梯度计算方法-反向传播
一般来说,BP的梯度计算,只要从最后一个节点开始逐层反馈式就可以了:
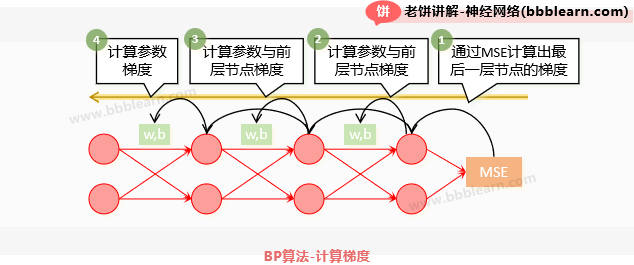
【1】根据误差函数,求最后一层节点梯度
【2】利用最后一层节点梯度,求出该层的参数梯度,与倒算第二层的节点梯度
【3】利用倒算第二层的节点梯度,求出该层的参数梯度,与合算第三层的节点梯度
....
如此类推,就能计算出所有层的梯度了。
话虽如此,实际推导起来,还是极为头晕和复杂的,这里我们就不具体推导了,如果大家感兴趣,可以在《BP神经网络-自实现代码》中找到详细的推导,但需要非常大的耐心、容易劝退,不建议新手阅读。
- 老饼有话说
事实上,BP神经网络其实原本就叫"多层感知机神经网络(MultiLayer Perceptron,MLP)",只不过它使用BP算法来计算梯度,这是它刚提出时的一个亮点,所以也就称为BP神经网络了。
相信到这里大家都清楚了,BP神经网络BP算法,因为BP算法只是一种梯度计算方法,而且它适用于所有前馈模型。在深度学习中,基本都是前馈模型,基本都用BP算法来计算梯度,所以在深度学习中只有"多层感知机(MLP)模型"而没有"BP神经网络"一说。
2.2. 三层BP神经网络-梯度计算-直接计算
好了,如果只是玩三层BP,反而不需要这么麻烦,因为它的模型就只是而已,我们直接强行求它的梯度就可以了,这里我们可以直接给出它每层的参数梯度公式,如下:
一、输出层梯度公式
输出层权重梯度:
输出层阈值梯度:
二、隐层梯度公式
隐层权重梯度:
隐层阈值梯度:
三、符号说明
:样本个数、输出个数
:第m个样本第i个输入
:第m个样本第k个输出的误差,即
:第m个样本第i个隐节点的激活值
从公式可以看到只要先计算出误差E和隐层激活值H,然后代入公式就可以计算出各层参数的梯度了。
三、梯度下降法求解三层BP神经网络-代码实现
好了,有了梯度公式,我们就可以用梯度下降法来求解BP神经网络了。
3.1. 三层BP-自实现代码
这里我们用BP来拟合以下的数据:
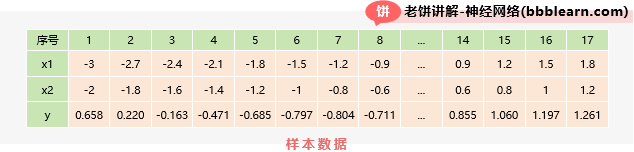
其中, x1和x2都是等间隔采样得到的数据,而y是由生成的数据。
下面我们用梯度下降法训练一个BP神经网络,来拟合上述和的关系,具体代码实现如下:
% 本代码展示梯度下降法求解BP神经网络(笔者测试代码的版本:matlab2018a)
% 本代码来自《老饼讲解-BP神经网络》 www.bbblearn.com
close all;clear all;
setdemorandstream(88); % 设置随机种子
%-----------数据----------------------
X = [-3:0.3:2; -2:0.2:1.2]; % 生成x1和x2
y = sin(X(1,:))+0.2*X(2,:).^2; % 生成y=sin(x1)+0.2*x2^2
%--------参数设置与常量计算------------
hide_num = 3; % 隐节点个数
lr = 0.05; % 学习率
[in_num,sample_num] = size(X); % 输入个数与样本个数
[out_num,~] = size(y); % 输出个数
%--------初始化w,b和预测结果-----------
w2 = rand(out_num,hide_num); % 输出层的权重
b2 = rand(out_num,1); % 输出层阈值
w1 = rand(hide_num,in_num); % 隐层权重
b1 = rand(hide_num,1); % 隐层阈值
py = w2*tansig(w1*X+repmat(b1,1,size(X,2)))+repmat(b2,1,size(X,2)); % 预测结果
mse_record = [sum(sum((py - y ).^2))/numel(y)]; % 预测误差记录
% ---------用梯度下降训练---------------
for i = 1:5000
%计算梯度
h = tansig(w1*X+repmat(b1,1,sample_num)); % 隐节点激活值
gN2 = 2*(py - y )/(sample_num*out_num); % 输出层(第二层)节点梯度
gw2 = gN2*h'; % 输出层(第二层)权重梯度
gb2 = sum(gN2,2); % 输出层(第二层)阈值梯度
gN1 = (w2'*gN2).*(1-h.^2); % 隐层(第一层)节点梯度
gw1 = gN1*X'; % 隐层(第一层)权重梯度
gb1 = sum(gN1,2); % 隐层(第一层)阈值梯度
%往负梯度更新w,b
w2 = w2 - lr*gw2; % 更新隐层-输出层权重
b2 = b2 - lr*gb2; % 更新输出层阈值
w1 = w1 - lr*gw1; % 更新输入层-隐层权重
b1 = b1 - lr*gb1; % 更新隐层阈值
% 计算网络预测结果与记录误差
py = w2*tansig(w1*X+repmat(b1,1,size(X,2)))+repmat(b2,1,size(X,2)); % 计算输出
mse_record =[mse_record, sum(sum((py - y ).^2))/numel(y)]; % 记录误差
end
% --------绘制训练结果与打印模型参数--------
f = figure; % 初始化画布
subplot(1,2,1) % 第一个子图
plot(mse_record) % 绘画误差曲线
subplot(1,2,2) % 第二个子图
plot(1:sample_num,y); % 绘画真实值
hold on % hold on
plot(1:sample_num,py,'-r'); % 绘画预测值
set(f,'units','normalized','position',[0.1 0.1 0.8 0.5]); % 设置图像位置
%--模型参数--
w2 % 隐层到输出层的权重
b2 % 输出层阈值
w1 % 输入层到隐层权重
b1 % 隐层阈值代码运行结果如下:
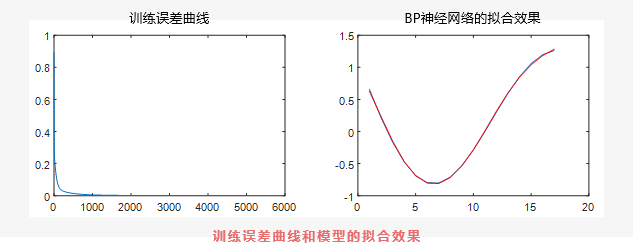
从误差曲线可以看到,模型在训练数据上基本已经拟合训练样本了,说明模型训练是成功的。
下面是模型的权重和阈值:

将模型参数代回三层BP神经网络的模型表达式,即可得到模型为:
3.2. BP神经网络-预测结果和真实结果
不妨将 作为测试数据,此时真实输出为:
将它代入上述训练的BP神经网络,预测结果如下:
模型的预测值0.6610与真实值0.5294 误差0.1316,这个误差不算太大,但也不算小,整体来说,训练的BP神经网络模型已具有一定的效果,说明算法是可行的。
为什么训练结果这么好,而预测误差还这么大?读者们能想明白吗?这问题能改善吗?要怎么改才行?刚开始我也有点蒙,但后来思考了一下就明白问题在哪了,这需要一些后面的知识,我们后面再讲解。
- 提示
值得注意的是,这里的实现是比较粗糙的,只是帮助大家理解BP的训练原理,实际使用时,如果使用梯度下降法,一般变量>8个时,效果就开始迅速下降了,如果要自己实现一个BP投到实际应用,最好是按matlab工具箱的做法,用lm算法+Nguyen-Widrow初始化来实现BP神经网络,这个我们会在《BP神经网络-自实现代码》中详细讲解,但一般来说,如果不是非要自实现不可,我们就直接使用matlab工具箱就好了,没必要去研究这些底层原理。
结束语
好了,这一节我们又亲自用梯度下降法来训练了一个三层BP神经网络,通过这一节就很具体的了解BP神经网络是怎么训练出来的了,同时,我们也知道了BP的梯度是怎么计算出来的,通用形式一般是用BP算法后馈式来计算梯度,而如果只是针对三层BP,则可以实际点,直接强行计算出梯度公式就可以了,没必要那么麻烦。
 评论
评论
