-
机器学习-进阶-学前解说
-
1.1.学前解说
-
-
各种模型
-
2.1.线性模型
-
2.2.逻辑回归
-
2.3.决策树
-
2.4.集成算法
-
2.5.其它模型
-
- 聚类与降维
- 训练算法
-
建模技巧
-
5.1.预防过拟合
-
5.2.建模技巧
-
-
机器学习进阶-总结
-
6.1.总结
-
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【原理】逻辑回归模型-意义解说
我们都知道,逻辑回归最初使用时,仅仅是将它作为"线性回归"在解决逻辑判断问题上的一种扩展,但随着逻辑回归越来越成熟,各路大神就提出了不同的理解角度,这里我们介绍一种从信息量差的角度理解逻辑回归模型的方法。
一、从信息差的角度-理解逻辑回归
下面我们一步一步,从信息量开始,推导出逻辑回归模型。
Step-1. 当前掌握的正负信息量
我们都知道,一个事情的信息量与它发生的概率的关系为:
但是,这个信息量是知道真相时所获得的信息量,意味着它其实是"离真相所缺失的信息量"
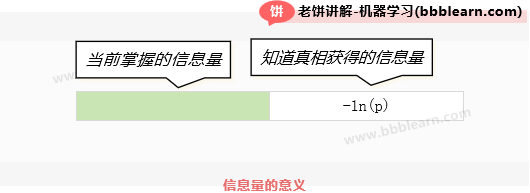
为方便理解,我们不妨将当前掌握的信息量记为:
,其中充当整体信息量。
那么,对于二分类问题,记样本属于正样本的概率为p,则当前掌握的负、正信息量分别为:
这样其实不是十分严谨,但为了方便理解,就这样来好了。
Step-2. 偏向的正样本的信息量
进一步地,可知当前偏向正样本的信息量差为:
如果时,就代表当前的信息更偏向于“正样本",反之,则偏向于负样本。
不妨把它进一步展开,则有:
Step-3. 逻辑回归模型
好了,现在可以开始推导逻辑回归模型了。
假设,我们现在什么证据也没有,那我们只能凭经验概率来确定,不妨将先验概率记为(它可以根据历史样本中"正样本的占比"来估算),那么则有:
事实上呢,我们已经观察到样本的一些特征X了,这些特征X就可以作为证据,去修正我们的先验概率,不妨假设证据所提供的信息量差为,其中称为的证据权重,则有:
但是,我们并非只有一个证据,我们又收集到了证据,那么进一步修正上式,则有:
有类似地,对于n个特征,这些特征作为证据,一个一个的去修正,则有:
由于是已知、固定的,所以也是一个已知常数,不妨记它为b,则有
好了,在知道右边的信息量差,自然就能知道左边的p了,将它化简,如下:
恭喜,这就得到我们的逻辑回归模型了!
有的同学可能会问,为什么每个证据的信息量差可以直接相加,这其实是假设了每个证据之间是独立的,由于独立事件的信息量可以相加,所以信息量差也就直接相加了。
Step-4:损失函数
好了,进一步的,很自然地,我们希望基于模型的预测概率下,在知道真相时,所获得的信息量的期望最小,也就是交叉熵了,因此损失函数为:
上式其实很好理解,就是两类样本带来的信息量之和,再求均值,也就是单个样本所获得的信息量期望了。如果巧妙地把两个连加号合并,则得到如下的表述:
逻辑回归损失函数的表述很多形式,这里就不展开了,但它总的意义,就是最小化交叉熵,也就是希望我们在知道真相时获得的信息量尽量的小。土味的理解,就是希望在模型的预测下,最小化我们对真相的惊讶程度。
总结
总的来说,逻辑回归模型就相当于一个一个的去收集证据,来纠正我们对样本真实标签的认识。
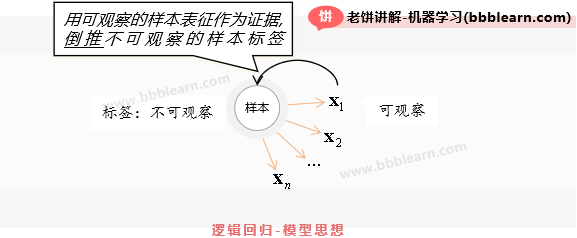
随着一个一个证据对信息的补充,就一点一点的减少我们在知道真相时所获得的信息量,而逻辑回归的损失函数,与模型的出发是一致的,就是希望在知道真相时所获得的信息量最小化。
 评论
评论
