-
机器学习-进阶-学前解说
-
1.1.学前解说
-
-
各种模型
-
2.1.线性模型
-
2.2.逻辑回归
-
2.3.决策树
-
2.4.集成算法
-
2.5.其它模型
-
- 聚类与降维
- 训练算法
-
建模技巧
-
5.1.预防过拟合
-
5.2.建模技巧
-
-
机器学习进阶-总结
-
6.1.总结
-
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【前言】机器学习进阶-学前解说
恭喜大家!终于来到机器学习的进阶阶段了!
在进阶课程里,主要就是多学一些模型、算法,并把建模知识拓展得更全面一些。在这里,我们的目标仍然是锚定一般机器学习业内人士,他们懂什么、懂到什么程度,那我们就学什么、学到什么程度。
一、机器学习-进阶-学前解说
1.1. 课程里讲了哪些内容
如大家在目录中所见到的,我们这里讲的内容主要有:
线性模型:线性回归、岭回归、Lasso回归。
分类模型:逻辑回归、决策树、感知机、SVM、集成算法(随机森林、Adaboost、GBDT、Xgboost)。
聚类算法:层次聚类、K-means、DBSCAN。
降维算法:PCA主成份分析、线性判别LDA、因子分析FA。
训练算法:梯度下降、动量下降法、牛顿法、随机梯度下降法。
大家一定要记住,能懂的就懂、不懂的就粗略理解就可以了,因为事实上这里我们只是为了拓展我们的视野,因此并没有什么内容是非要理解不可的,总之,就是能学多少学多少,学到就是赚,没学到也不亏。
1.2. 内容的主次之分
好了,虽然我们这里展示了这么多内容,但有些内容并不是那么的重要,这里我们简单介绍一下。
- 模型-导读

线性回归、岭回归、Lasso回归三个模型,大家知道就可以了,实际使用不是那么频繁,了解它是怎么一回事就可以了,同时从这三个模型中也会较形象地理解L1、L2正则项是什么。
其次,逻辑回归、决策树两个模型最重要,但在入门篇我们已经讲过了,这里进一步加深理解就可以了。
感知机 :已经淘汰了,这里当成历史来了解一下就好了。
SVM :机器学习中最美的模型,曾经很火,但现在很少使用,它理论很复杂,大家了解一下就可以了。
集成算法:集成算法从提出以来就一直具有较好的效果,随机森林、Adaboost、GBDT、Xgboost就是一路发展过来的四个标志性集成模型,按顺序学习比较容易理解。现在Xgboost在机器学习中属于一哥地位,但我还没整理它,以后再补上。由于Adaboost和GBDT的理论较复杂、而且被Xgboost平替了,所以这里只是简单介绍,如果一定要追寻严谨的理论,可以在《sklearn算法原理》中学习。
- 聚类与降维算法-导读
聚类算法除了在一些特殊领域使用,平时相对使用会较少、或较浅,作为进阶,这里我们就介绍最经典的三个聚类算法:层次聚类、K-means和DBSCAN,普通使用也就够了,如果遇到要深入使用聚类算法的,那再自行研究。

降维算法我们也介绍三个:PCA(主成分分析)、LDA(线性判别分析)、FA(因子分析),最常用的是PCA,但在入门时已经介绍过了,这里再把LDA和FA学习一下就好了,能够大概理解就可以了,真的需要使用,再深入研究。
- 训练算法-导读
训练算法非常的多,而梯度下降算法是最基本的训练算法,搞机器学习一般理解它也就够了,因为搞机器学习一般都是调包训练,不需过多的理解。但作为其它分枝的基础,我们就需要了解更多的训练算法,而动量下降法+随机下降往往就是其它分枝中最Base的方法了。
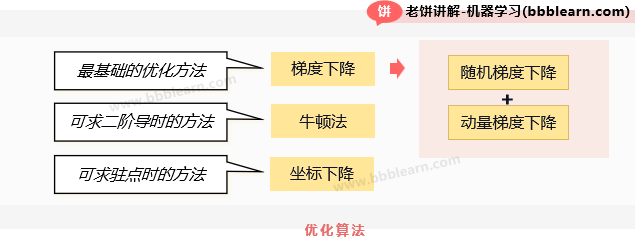
此外,牛顿法和坐标下降法则较为特殊,在可以求二阶导( Hession矩阵)时,可以使用牛顿法,而在可以求参数的驻点时,则可以使用坐标下降法,相对梯度下降法,它们有一定的局限性,但效果通常会更好一些。
结束语
闲话少说,直接开始学习就是最好不过的选择了,在学习时记住记住,能理解的就理解,不能理解的就留个印象就可以了,机器学习的内容非常的多、非常的广泛,没有哪个模型是非了解不可的,在往后的接触中逐步前进就可以了。
 评论
评论
