-
机器学习-进阶-学前解说
-
1.1.学前解说
-
-
各种模型
-
2.1.线性模型
-
2.2.逻辑回归
-
2.3.决策树
-
2.4.集成算法
-
2.5.其它模型
-
- 聚类与降维
- 训练算法
-
建模技巧
-
5.1.预防过拟合
-
5.2.建模技巧
-
-
机器学习进阶-总结
-
6.1.总结
-
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【模型】套索回归模型-原理解说
上节我们学习了岭回归,这节再来看看Lasso回归,它也是一种线性模型,我们都知道,岭回归就是在线性回归的基础上加入L2,而Lasso回归呢,则是加入了L1惩罚项,为啥不用L2而改用L1呢,且听我们细细道来。
一、Lasso回归模型
我们先来看看Lasso回归模型的表达式和损失函数,再来讲解一下它的意义,就明白它是什么了。
1.1. Lasso回归模型是什么
Lasso回归模型其实就是一个线性模型,如下:
它的模型其实和线性回归没什么区别,真正的区别在于损失函数,Lasso回归的损失函数如下:
其中,:样本个数
:系数个数
:y的预测值
:y的真实值
:惩罚系数,用于调节系数W的惩罚力度
好家伙,它其实就是在损失函数中,加入了正则项,由于绝对值是"一范数",所以也称为一范正则项。

那这个正则项有什么用呢,它其实就是用来防止系数过大,因为系数越大,就会令整体损失值越大,因此,在损失函数中加入它,就可以使得最终求解出来的结果更偏向于更小的系数。
注意,Lasso回归与岭回归一样,本身是不带阈值的,因为要对各个w进行惩罚,为了避免惩罚阈值b,所以没有阈值,但实际应用时会先将数据中心化,再反求出阈值b,这在岭回归时已经说过,就不再啰嗦了。
1.2. Lasso回归的特点-稀疏化
我们都知道岭回归就是在线性回归中加入L2惩罚项,用来惩罚过大的系数,但是后来大家发现,加入L2惩罚项,会导致模型最终得到的系数很难为0,即使变量之间是线性相关,那也不行,也不会为0,这就尴尬了。
所以就有了Lasso回归,Lasso回归抛弃掉岭回归中的L2正则项,而改用L1正则项,从而使得模型中的部分系数容易0,如下:
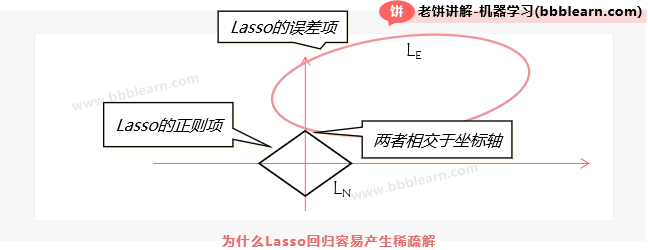
由于Lasso回归加入了一范正则项,它的就相当于在"系数绝对值之和"与"均方差"之间进行权衡,如图所示,如果一范正则项在几何上就是菱形,均方差相当于椭圆,两者的交点,一般就在菱角上,所以某些系数就会为0。这里不是很严谨,大概就是这么一个意思。
由于Lasso回归很容易让系数为0,所以用Lasso回归训练完后,如果有些变量的系数为0,说明它对预测并没有起来作用,那么就可以剔除掉这些变量。
二、Lasso回归的模型求解
我们知道,线性回归模型是使用最小二乘法来求解就可以了,但是,Lasso回归在损失函数中加入一范正则项后,就不能再用最小二乘法啦,一般改用坐标下降法来进行求解。
坐标下降法是个什么东西呢?其实就是每次都把单个参数(也就是模型中的单个w或b)迭代到最佳位置,各个参数轮流迭代到最佳位置,就称为一轮迭代,然后经过多轮迭代,直到参数的变化很小或达到最大迭代次数则终止训练。
Lasso回归的具体训练流程如下:
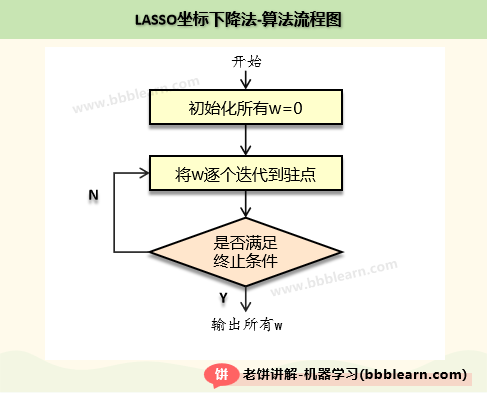
如图所示,
1. 先把解全初始化为 0。
2. 然后循环迭代,每次将一个参数调整为最优(也就是驻点)
3. 直到满足终止训练条件,退出迭代
终止条件为:(1)达到最大迭代次数,(2)w的变化率极微小
好了,我们知道,它每次都把参数调整到最优,那么这个最优点就是驻点,也就是偏导为0的地方,这只需要求一下偏导,然后再计算出驻点就可以了,这里我们就不展开推导了,公式看多了头又晕。
三、Lasso回归-应用例子
好了,说了这么多,我们就正式来使用一下Lasso回归吧!
"""
本代码展示如何用sklearn实现Lasso回归
本代码来自《老饼讲解-机器学习》 www.bbblearn.com
"""
from sklearn.linear_model import Lasso
import numpy as np
x1 = np.arange(0,100) # 生成x1
x2 = x1*4+3 # 生成x2,这里的x2与x1是线性相关的
x = np.concatenate((x1.reshape(-1, 1),x2.reshape(-1, 1)),axis=1) # 将x1,x2合并作为x
y = x.dot([2,3]) # 生成y
alpha = 0.3 # 设置正则项系数alpha
md = Lasso(alpha=0.3,fit_intercept=True,max_iter=1000) # 初始化Lasso回归模型
md.fit(x,y) # 用数据训练模型
sim_y= md.predict(x) # 预测
print('\n======Lasso训练结果=========') # 打印结果
print('权重 :'+ str(md.coef_)) # 打印权重
print('阈值 :'+ str(md.intercept_)) # 打印阈值
print( '均方误差 :'+ str(((y-sim_y)**2).sum())) # 打印均方误差
print('迭代次数:'+ str(md.n_iter_)) # 打印迭代次数可以看到,在代码中我们设置了fit_intercept=True,这样模型训练出来的Lasso回归模型就是带阈值的,如果设为false,就没有阈值。代码运行结果如下:
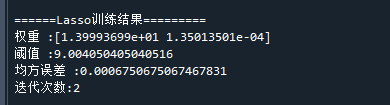
代入模型表达式,可得到模型为:
可以看到,第二个变量的系数已接近于0,说明第二个变量在模型中是可去除的。这就是Lasso回归的好处,在线性相关时,其中一个变量的系数会趋于0。
总结
总的来说,Lasso回归模型就是在线性回归的基础上,加入一范正则项,来避免系数过大,而且在变量多重共线性时,它容易产生稀疏化的解,所以可以利用它来筛选变量,总结如下:
1. Lasso就是在线性回归的基础上,加入一范正则项。
2. Lasso使用坐标下降法来训练模型。
3. Lasso可以通过alpha系数来避免系数过大。
4. Lasso容易产生稀疏解,可以用来筛选变量。
好了,关于Lasso回归的核心内容就是这么多了,学习时注意把它和线性回归、岭回归来进行对比,就会深刻多了,三个模型虽然很像,但是却各有各的用处。
 评论
评论
