-
机器学习-进阶-学前解说
-
1.1.学前解说
-
-
各种模型
-
2.1.线性模型
-
2.2.逻辑回归
-
2.3.决策树
-
2.4.集成算法
-
2.5.其它模型
-
- 聚类与降维
- 训练算法
-
建模技巧
-
5.1.预防过拟合
-
5.2.建模技巧
-
-
机器学习进阶-总结
-
6.1.总结
-
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【总结】线性模型学习-内容总结
前面我们学习了线性回归、Lasso回归和岭回归三个线性模型,它们都是较知名的线性模型,我们这节简单地来总结一下,并辨析一下它们的区别,加深理解。
一、线性模型-总结
最常见的线性模型就这三兄弟:线性回归、Lasso回归和岭回归。好了,线性回归模型肯定是老大哥了,但如果线性回归求解后,权重w很大,那可能是不符合现实关系的,就需要使用正则项来惩罚系数了,如果加入L1正则项,就变Lasso回归了,而如果加入L2正则项,就是岭回归模型了:
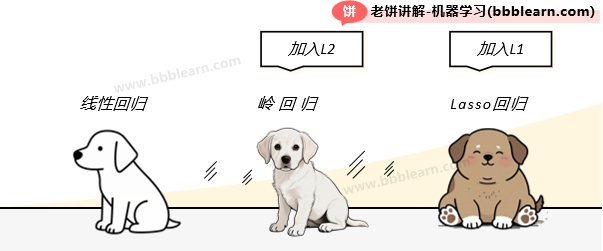
如图,先有老大,线性回归,然后老二(岭回归)加入了L2正则项,但是呢,它的系数很难为0,也就是它无法识别线性相关的变量,所以就又跑出了老三(Lasso)回归,通过加入L1正则项来惩罚系数的同时,又可以容易令系数为0。
1.2. 三个线性模型的用途
虽然最原始的初衷就是在线性回归模型中加入L1和L2正则项,但是呢,经过我们的学习,我们也会发现,老二和老三又发展出了自己的用途。

构建线性模型是三者的共同用途,但岭回归,它的岭迹图可以用来分析变量,而Lasso容易产生稀疏解,则用来筛选变量,这就是它们的副产品了,
1.3. 关于岭回归、Lasso回归的阈值
我们都知道,岭回归、Lasso回归都是对线性回归的系数进行正则惩罚,而阈值b呢,是不需要惩罚的,所以纯粹的岭回归、Lasso回归模型是没有阈值的,因为加入了阈值就会把阈值一起惩罚了。因此,在实际中,一般是先把数据中心化后,再进行建模,在求得模型系数后,再进一步推导出原始数据中的阈值b是多少。我们使用sklearn时,就不需要这么麻烦了,sklearn会帮我们把这些给干了,我们只需要明白这道理就行了。
1.4. 三个模型的求解
最后,我们来比较一下三个模型的求解方法。
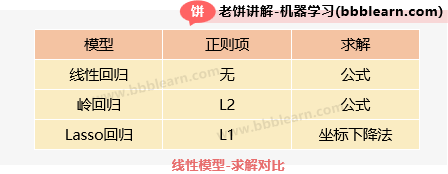
如图所示,线性回归没有加入正则项,也就是它只有误差项,并且它是可以用公式求得精确解的。
其次,岭回归加入了L2正则项,它也是靠公式来求得精确解的,但是由于它加入了正则项,所以误差项并不能取得真正的最小值,也就是牺牲了误差精度来换来泛化能力。
最后,Lasso回归加加入了L1正则项,它靠坐标下降法来进行优化,所以它并不能完全求得精确解,同样地,由于它加也入了正则项,所以也牺牲了精度来换来泛化能力。
总的来说,能用线性回归,就用线性回归,如果要惩罚系数,就用岭回归,这时自然会牺牲一点误差精度 了,但如果希望进一步稀疏化,那就只能用Lasso回归了,这时不仅牺牲了误差精度,还牺牲了求解精度。
结束语
好了,碎碎念了这么多,其实总的来说,就能用线性回归就用线性回归建模,因为Lasso和岭回归会牺牲一点点误差精度,而Lasso和岭回归呢,则可以利用它们来筛选和分析变量,虽然我没用过,但别人就是这么说的,我这里也只是分享给大家,无他,每个领域都有自己喜欢的一套模型和分析方法,我也没深究是哪个领域流传出来的分析方法,但根据我的经验,肯定是有些领域喜欢用这一套,才会被熟为人知。
 评论
评论
