-
基本求解
-
1.1.公式求解
-
- 梯度优化
- 智能优化算法
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【优化】一篇入门之-SGD随机下降
SGD算法全称为Stochastic Gradient Descent(随机梯度下降),它是梯度下降法的一种改进,它与梯度下降法的区别只在于,它每次只随机选择一个样本来进行梯度下降,虽然简单,但效果却比梯度下降要更好,下面我们就来具体的了解了解一下SGD算法、以及批量SGD算法吧。
一、SGD算法
在机器学习中,一般模型的损失函数都是单个样本损失总和,如果使用梯度下降算法,那么每次是先计算出整体样本的梯度,然后再按负梯度方向调整:

而SGD算法和批量SGD算法就是这种场景下,对梯度下降算法的一种改进。
1.1. 纯粹的SGD算法
我们先来说下最纯粹的SGD算法,它其实是非常简单的,它就是在梯度下降法中,每次只随机选择一个样本来计算梯度,然后按负梯度下降,接着又随机选一个样本计算梯度,然后按负梯度下降....如此如此,也就是每次计算完一个样本的梯度就马上去调整参数了,如下:

为啥这样做?因为这样比全量计算再调整梯度的效果更加好。
详细原理我也没去详细考究、不想搞得这么累。但是,简单理解一下也能知道它效果好呀!你想想,整体100个样本,我抽一个样本计算梯度、并以它作为对整体梯度的评估,这估计效果肯定倍,因为从1到100逐个增加样本去估算这100个样本的梯度,从边际效应来说,第1个的效益肯定是最大的,然后效果逐步减少,所以1个样本的估算效果肯定>整体的1/100。好了,我调整一次的效益大于你整体的1/100,那么我调整100次肯定就大于整体调整了,而两者的代价同样是计算100个样本的梯度。好了,详细原理是真的不想去考究了,就大概这样理解吧~
1.2. 批量SGD法
如果大家经常调包,也会发现像sklearn、pytorch包中都会实现SGD算法,但实际这些SGD算法中,往往实现的并不是严格的SGD算法,而是批量SGD算法。那什么是批量SGD算法呢?其实它也很简单,在SGD算法中每次只抽一个样本,而批量SGD法就是抽一批样本。
由于训练样本往往都上万,所以一般都是成批成批的抽,例如100个、100个的抽,而不是一个一个的抽,毕竟,如果样本量很大,用一个样本的梯度去估算整体梯度,偏差可能会较大,而且每计算一个样本的梯度就调整一次参数,计算机也很累,所以每次就抽多些,而不是抽一个,这就变成批量SGD算法了。

在代码实现的角度来看,也可以当成是把样本分成多批,然后逐批用梯度下降法去训练。
也不扯那么多了,其实就是很简单的一个东西,如果还不明白,看一下下面的代码就知道了。
二、SGD算法-代码实现
我们下面用SGD算法来训练一个逻辑回归模型。
逻辑回归模型的损失函数 :
其中,
现在要优化参数W使得上述的损失函数最小化,这里需要先计算出参数的梯度,如下:
好了,只需要逐个样本计算梯度,然后按负梯度方法进行下降就可以了,代码如下:
"""
本代码展示SGD求解逻辑回归的python代码实现
本代码来自《老饼讲解-机器学习》www.bbblearn.com
"""
from sklearn.datasets import load_breast_cancer
import numpy as np
import random
np.random.seed(888) # 设定随机种子,方便复现结果
#----数据加载------
data = load_breast_cancer() # 加载breast_cancer数据
X = data.data[:,4:8] # 作为示例,只使用4个变量来建模
y = data.target # 类别标签
xt = np.insert(X, X.shape[1], 1, axis=1) # 给X增加一列,作为阈值
#---SGD求解w---------------
sn = X.shape[0]
w = np.random.rand(xt.shape[1]) # 初始化权重
for i in range(1000): # 逐步训练权重
idx = list(range(sn)) # 样本索引
random.shuffle(idx) # 对索引随机打乱
for j in idx: # 逐个样本训练模型
xx = xt[j,:] # 当前x
yy = y[j] # 当前y
p = 1/(1+np.exp(-xx@w)) # 计算p
g = (xx.T*(p-yy)) # 计算梯度
w = w - 0.01*g # 往负梯度方向更新w
p = 1/(1+np.exp(-xt@w)) # 计算p
loss = -(y@np.log(p.T)+(1-y)@np.log(1-p.T))/sn # 计算损失值
print('第 %d 次迭代,损失值loss:%.5f'%(i,loss)) # 打印当前损失值
p = 1/(1+np.exp(-xt@w)) # 最终的预测结果
print("模型参数w:"+str(w)) # 打印参数代码运行结果如下:
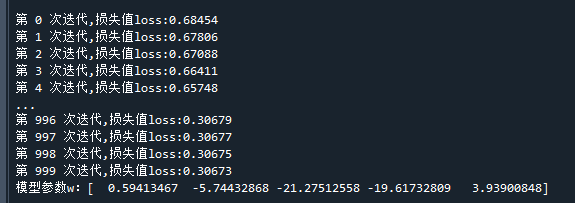
可以看到,损失值是一直下降的,说明SGD算法是有效的。
总结
总的来说,SGD算法就是每次只随机抽一个样本来进行梯度下降,而批量SGD就是每次随机抽一批样本来进行梯度下降。事实上,SGD算法并不局限于梯度下降法,它更多时候是一种思想指导,也就是其它的算法,也可以结合SGD算法,进行分批训练,这样就可以给优化算法提升优化速度。
 评论
评论
