-
基本求解
-
1.1.公式求解
-
- 梯度优化
- 智能优化算法
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【优化】一篇入门之-梯度下降算法
梯度下降算法(Gradient descent)是机器学习中最基本的优化算法,它基于目标函数的负梯度方向来迭代x,使得目标函数f(x)逐步下降。下面我们就来详细说说梯度下降算法的原理、算法流程,以及展示一个具体的梯度下降算法代码实现例子,最后再来谈下梯度下降法的优缺点。
一、梯度下降算法
往往我们希望优化目标函数,也就是找到一个来令尽量的小,如果f(x)连续可导,那这时候就可以使用梯度下降算法了,梯度下降算法基于目标函数的梯度,来不断迭代x,令f(x)逐步下降,它非常的简单,一说就懂,那就让我们直接来看看它是怎么干的吧。
1.1. 什么是梯度下降算法
有的同学可能忘记梯度是什么了,其实梯度就是导数,在一元函数中称为导数,在多元函数就称为梯度。而梯度下降算法呢,就是基于梯度来优化目标函数,它的做法如下:
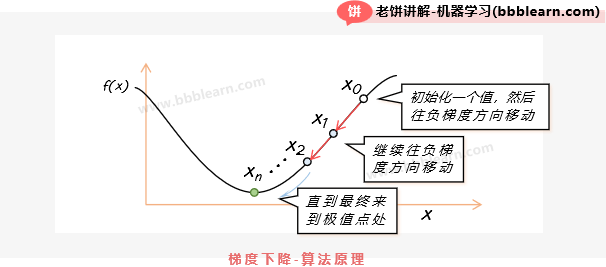
如图所示,梯度下降算法先取一个初始值,然后进行迭代,每次都往梯度的反方向调整它,直到梯度很小时就退出训练,因为梯度很小时,就代表已经很平缓了,也就意味着可能达到局部最低点了。
1.3. 梯度下降-算法流程
好了,我们正式的来看一下梯度下降算法的算法流程,直接上图:
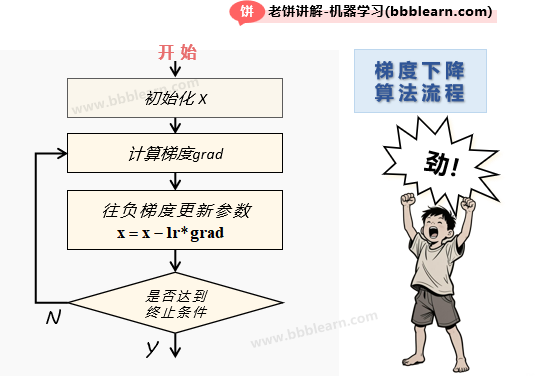
梯度下降法算的流程其实只有简单的几步:
1. 先初始化参数
2. 计算梯度
3. 往负梯度调整参数
其中,lr是学习率,代表调整的步长
4. 检查是否达到终止条件,否则重复2、3
终止的条件一般设为"达到最大训练次数"和"梯度过小"。
有同学可能会问lr是什么,lr是学习率(learning rate),它用于控制调整的步长,一般设为0.1或0.01。
二、梯度下降法-进一步理解
梯度下降算法是简单的,但我们不妨加深一点对它的理解。
2.1. 为什么要往负梯度方向调整?
为什么梯度下降算法每次都要往负梯度方向调整呢?
在一元函数中,负梯度就是导数的反方向,在多元函数中,负梯度就是各个变量偏导数的反方向:
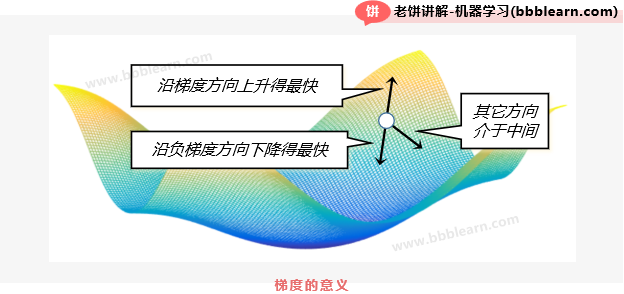
如图,可以看到,梯度是函数瞬时上升最快的方向,而负梯度呢,就是函数瞬时下降最快的方向了,所以往负梯度方向调整,只要步长足够小,就能保证目标函数一定能下降,而且是下降最快的方向,也正因为这样,梯度下降算法往往也称为最速下降算法。
2.2. 关于初始化
事实上,梯度下降法对初始值是非常敏感的,我们先来上个图:
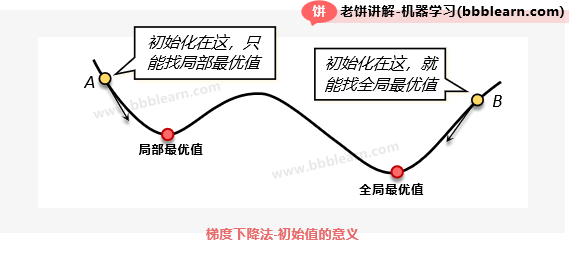
如图所示,如果初始化在点A,那么最终能找到的就是局部最优值,而初始化在点B,最终就会找到全局最优值。总的来说,梯度下降法只能找到离初始值最近的局部极小值,如果初始化不好,找到的结果也不好。所以在用梯度下降法时,往往会采用随机初始化,然后多试几次,看看哪次的结果最好。
三、梯度下降法-实现代码
说了这么多,是时候来实操一下了,假设我们的目标函数为:
下面我们就用梯度下降算法,来求一下它的最小值。
由于梯度下降法需要使用目标函数的梯度,所以要先算出目标函数的梯度,如下:
,
接下来只需按梯度下降算法的流程,让解不断地往负梯度方向迭代就可以了。
梯度下降法具体实现代码如下:
"""
本代码用于展示梯度下降法求y= (x1-2)^2+(x2-3)^2的最小解
本代码来自《老饼讲解-机器学习》 www.bbblearn.com
"""
import numpy as np
x = np.array([0,0]) # 初始化x
lr = 0.1 # 设置学习率
for i in range(100): # 最大迭代100次
dx = np.array([2*x[0]-4, 2*x[1]-6]) # 计算x的梯度
x = x - lr*dx # 往负梯度方向更新x
if((min(abs(dx))< 0.001) ):break # 如果梯度过小,则退出迭代
y = (x[0]-2)**2+(x[1]-3)**2 # 目标函数值
print("第%d轮迭代:x=:[%f,%f],y=%f"%(i+1,x[0],x[1],y)) # 打印当前结果代码运行结果如下:
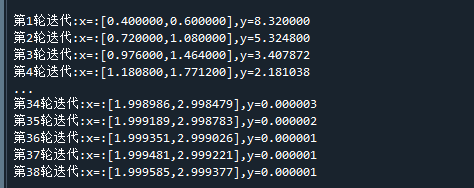
可以看到,经过38轮迭代,求得的 x1,x2= 【1.999,2.999】与真实极值【2,3】已经非常接近了
三、梯度下降法-优缺点
好了,最后的最后,我们再来说一下梯度下降法的优缺点。
3.1. 梯度下降法的优点
先说梯度下降法的优点,梯度下降法的优点很多,不妨说两个:
1. 算法简单,实现容易,计算量低。
2. 它的每一步迭代,只要学习率足够小,必然能下降。
总的来说,梯度下降算法简单又有效,随着学习,会发现这种简单又有效是多么的重要,在理论研究上,对它进行修改方便极了,在实际使用中,只需要求出梯度,然后几句代码就能搞定,不知多爽。
3.2. 梯度下降法的缺点
好了,下面我们来说说梯度下降法的缺点,这也就是为什么继它之后,又提出许许多多的优化算法。
1. 没有跳出局部最优的能力
我们都知道,梯度下降法它只能找到由初始值决定的局部最小值,而它没有没有任何跳出局部最优值的机制。

如上图所示,目标函数中随便的一个小坑 ,都能够把梯度下降法坑住,这就非常亏,如果目标函数中有很多小坑,那梯度下降法就基本没法搞了。
2. 极值点附近收敛速度缓慢
梯度下降法就是朝着负梯度方向调整,它调整的步长为lr*grad。初看这没什么毛病,但是实践就会发现,这家伙在极值点附近调整特别慢。

为什么呢?因为在极值点附近梯度grad会很小(梯度就代表着坡度,所以极值点附近的grad很小),那就非常矛盾了,它越靠近极值点,梯度就越小,它调整得就越慢,就好像有一个很大的阻力一样,不管它怎么迭代,基本都很难迭代到局部最小值,所以一般梯度已经极小时,我们就终止训练啦~
总结
这节我们学习了梯度下降法,它其实就是一种简单有效的优化算法,它只需要先初始化一个值,然后不断往负梯度方向迭代就可以了,就是这么的简单。
 评论
评论
