-
基本求解
-
1.1.公式求解
-
- 梯度优化
- 智能优化算法
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【优化】一篇入门之-牛顿法-原理
牛顿法可以说是二次优化算法中的祖师爷了,它的思想源自于牛顿求零点,然后应用到求极值时,就变为牛顿法了,牛顿法的特点是具有二次收敛速度,优化速度较快,但缺点是要求Hession矩阵。
今天我们就一起来看看牛顿法究竟是怎么一回事,顺便玩一玩它。
一、牛顿法-思想与算法流程
虽然牛顿法起源于牛顿求零点,但是这里我们这里就不扯那么远的历史,直接单刀直入来看牛顿法就好了。
1.1. 牛顿法-思想
开门见山,牛顿法的思路如下:
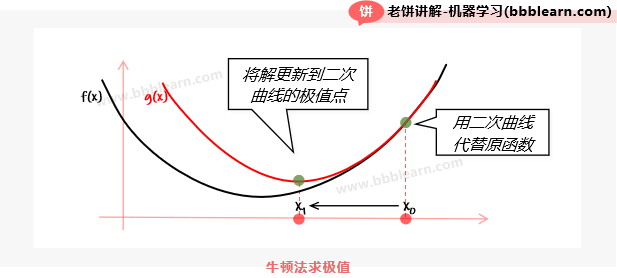
如图所示,设当前的迭代点为,那么牛顿法就在x处用一个二次曲线,来近似目标函数,既然近似了,那么就可以用的最小值,来估计的最小值,所以,就把迭代到的极小值处。如此类推,在新的处,再如法炮制,不断地迭代就行了。
好了,思想是这么一个思想,那么我们具体的来推导一下牛顿法。
1.2. 牛顿法-迭代公式
首先,设当前点为,那么根据泰勒展开,就可以知道,点处的二次近似曲面为:
然后上面的二次曲面求解极值点,也就是令其导数为0再求解,如下:
从而求得二次曲面的极值点,也就是牛顿法的迭代量:
多元函数中的一阶导称为梯度Gradient,二阶导称为Hession矩阵,所以一般将上式记为:
所以,牛顿法就是,先初始一个解x,然后每次都按上面的h来更新x就可以了。
1.3. 牛顿法-算法流程
通过上面的讲解,很容易就知道,牛顿法的算法流程如下:
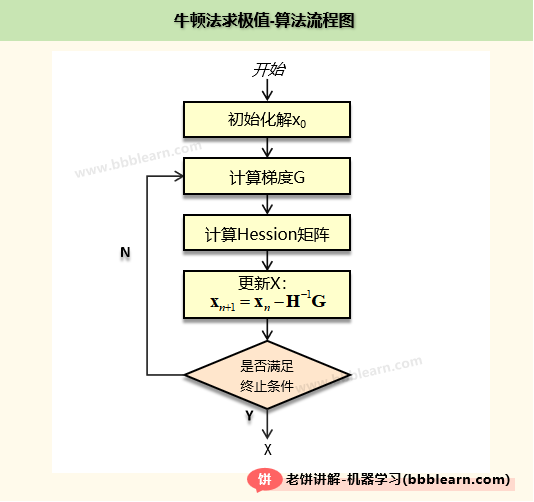
1. 设置一个初始解
2. 按以下公式迭代,直到满足终止条件
其中:
G为梯度(Gradient)(目标函数F的一阶偏导)
H为Hession矩阵(目标函数F的二阶偏导矩阵)
二、牛顿法-代码实例
好了,下面我们拉个简单的例子,来展示一下牛顿法的实现。
不妨用牛顿法来求二元函数的最小值。
由于牛顿法需要使用目标函数的梯度和Hession矩阵,现计算如下:
一阶导: ,
二阶导:
也就有:
根据G,H的公式,使用迭代公式 不断迭代就可以了,具体代码如下:
"""
本代码用于展示牛顿法求y= (x1-2)^2+(x2-3)^2的最小解
本代码来自《老饼讲解-机器学习》 www.bbblearn.com
"""
import numpy as np
x = np.array([0,0]) # 初始化x
for i in range(100): # 最大迭代100次
G = np.array([2*x[0]-4, 2*x[1]-6]) # 计算梯度G
H = np.array([[2,0],[0,2]]) # 计算Hession矩阵
x = x -np.linalg.inv(H)@G # 使用牛顿法迭代公式进行迭代
if((min(abs(G))< 0.001) ):break # 如果梯度过小,则退出迭代
print("\n第"+str(i+1)+"轮迭代:x=:["+str(x[0])+","+str(x[1])+"],y="+str((x[0]-2)**2+(x[1]-3)**2))代码运行结果如下:
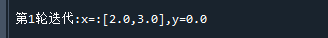
可以看到,一步就迭代到了,这是因为目标函数本身就是二次函数的原因。牛顿法的好处就在于,它是二次收敛的,它最大的缺点是需要计算Hession矩阵及其逆。
总结
这节我们学习了如何用牛顿法来优化目标函数,它是一种二次优化算法,它的思想就是用二次曲面来近似函数,然后每次迭代到二次曲面的极值点处。从它的原理我们就知道,它不一定每次都能一定下降,但是它具有二次收敛速度,所以就算不是每次下降也没关系,天下武功,唯快不破,一般来说它要比梯度下降法要快很多。它真正的缺点是很难落地,因为它要求目标函数的Hession矩阵,而往往推导目标函数的梯度都非常艰难了,就更别说Hession矩阵。
 评论
评论
