- 信息与统计
- 评估指标
- 矩阵与分解
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【介绍】一篇入门之-交叉熵是什么
机器学习中经常不可避免地要用到交叉熵(Cross Entropy,CE),特别是交叉熵损失函数,基本是机器学习中分类模型的标配损失函数,那么,交叉熵是个什么东西呢?它与信息熵又有什么区别呢?别急,下面就让我们一点一点的来说清楚它,然后再找个例子计算一下就清晰了。
一、交叉熵
我们先来看看交叉熵的定义和计算公式,先弄清楚它是怎么计算的,然后再来慢慢讲它的意义。
1.1.交叉熵的定义
交叉熵是指:有种取值,我们认为第 种取值的概率为,事实上第种取值的概率为,则交叉熵的定义为:在知道X的真实取值时,我们所获得的信息量期望。
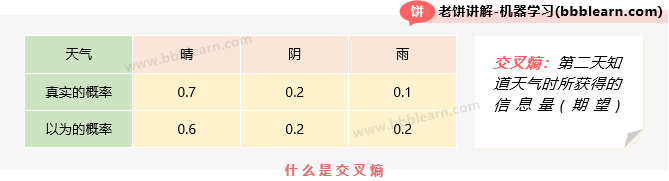
如图所示,天气有三种取值可能:晴、阴、雨,我们认为的概率和实际概率分别如图所示,然后在当知道实际天气情况时,所获得的信息量的期望,就是交叉熵了。
1.2. 交叉熵的计算公式
根据定义,交叉熵就是信息量期望,即可得到交叉熵的计算公式为:
其中,为x取值为时,所获得的信息量
特别地,当h取为香农信息量时,则称为香农交叉熵,香农交叉熵的计算公式:
其中,:我们认为取值为 的概率
:取值为 的真正概率
总的来说,交叉熵就是在不知道真实分布、仅有猜测的概率时,我们知道真相时所获得的信息量期望。
1.3. 交叉熵的计算公式
好了,让我们直接用一个例子来计算一下吧,这样简单、具体又直接!
假设已知一个人的性别为男、女的概率分别为,而我们认为是:
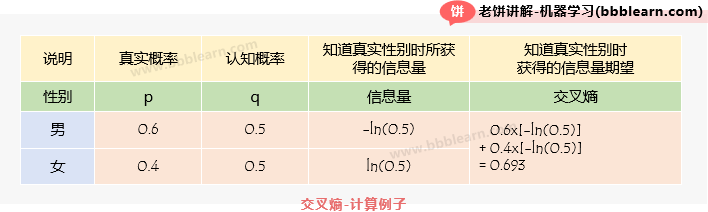
那么对任意一个人,在知道他是男/女的时候,分别获得信息量,因此,在知道性别时获得的信息量期望(即交叉熵)为。
这种在我们认为概率是q,而事实是p时,"知道x真实值"时获得的信息量期望就称为x的交叉熵。
二、如何理解交叉熵
2.1. 交叉熵的意义
交叉熵的意义是,它可用于评估我们认知概率的准确性,在认知概率与真实概率一致,即P(x)=Q(x)时,交叉熵是最小的(可参考KL散度中的证明),而随着我们的认知概率与真实概率出现的偏差越来越大,交叉熵也越来越大,因此,交叉熵往往用于评估我们对事件的认知概率的准确程度,交叉熵越小则说明越准确。
2.2. 交叉熵与信息熵的区别
交叉熵与信息熵在定义上比较相似,刚开始接触时很容易把它们混淆,但事实上,这两个家伙是很不同的两样东西,我们不妨一起来看看不同在哪里。
不妨先回顾一下交叉熵与信息熵的定义:
1. 信息熵 :信息熵指的是在客观概率p下,知道真相时所获得的信息量的期望
2. 交叉熵 :交叉熵指的是在认知概率q下,知道真相时所获得的信息量的期望

交叉熵与信息熵看起来很相似,但它们其实很不同,主要是它们的评估对象不同:
信息熵的评估对象主要是事件本身,它用于评估事件本身的混沌程度,不清晰度。
交叉熵的评估对象则是"我们",它用于评估我们对"事件的概率"认知的准确程度。
通俗来说,信息熵在描述事件,而交叉熵的焦点在于描述我们,信息熵是描述一件事所带来的震惊程度,而交叉熵则描述这个事件会怎么震惊我们,信息熵是注定的、不可变的,而交叉熵则是可变的,它随着我们认知的提高而降低。
总结
总的来说,交叉熵就是在认知概率下,知道事件真相时,所获得的信息量。认知概率与真实概率偏差越大,交叉熵就越大,在认知概率与真实概率一致时,交叉熵取得最小值。
 评论
评论
