-
入门教程-一步一步实现评分卡
-
1.1.评分卡-学前解说
-
1.2.评分卡-实现过程
-
1.3.评分卡-变量分箱
-
-
结束语
-
2.1.结束语
-
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【0】评分卡实例-问题数据概述
学习评分卡最好的方式是先通过一个实例来制作一个评分卡,再进行细节的了解,本文先介绍评分卡实例中的数据,并初步讲解评分卡的构建目标,以及构建的流程,通过本文,可以了解本实例中的数据含义,以及整个评分卡制作过程的大体流程,这样可以有个整体的了解,后面再慢慢讲细节。
一、评分卡实例-数据与问题
好了,下面我们先来看看本文评分卡实例所使用的数据。
1.1. 评分卡-案例数据
在我们的案例中,使用的是bbbrisk包的bloan小贷数据,它共2万条数据,包含10个变量与客户好坏标签。
数据包含的10个变量和标签如下:
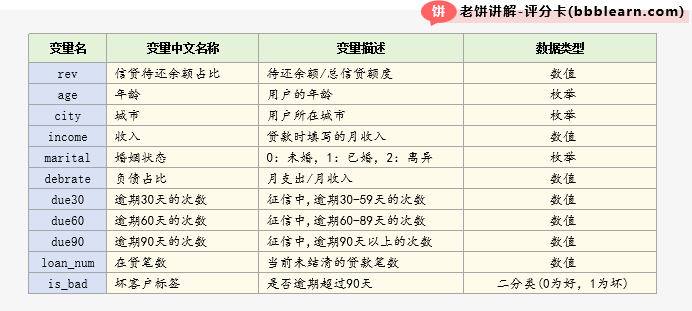
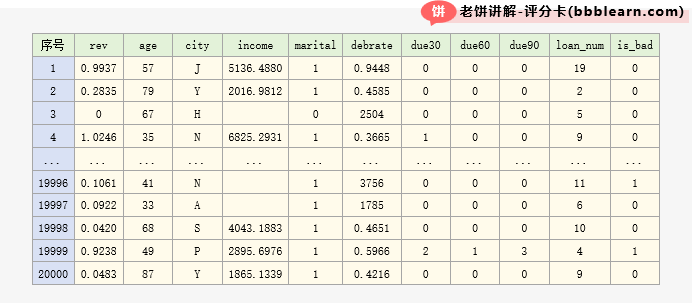
数据共2万条,示例如下:
1.2. 评分卡-建模目标
评分卡模型的目标是,依据客户特征数据(10个变量),判断客户是否坏客户(is_bad)。它会根据客户的特征数据,对客户进行评分,客户质量越好,评分越高。
评分卡最终需要输出两样最基本的东西:
【1】 评分卡表
【2】 评分阈值
评分表用于计算客户的评分,而评分阈值则用来判断客户是否能通过。
例如,评分阈值为650,那么评分为649的用户就会被拒绝。
- 评分表与评分方法
评分表的格式类似如下:
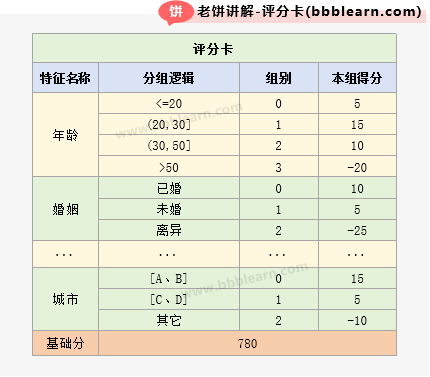
其中,各个字段的意义如下:
1. 特征名称:特征名称(变量名称)是用原始数据生成的建模变量的名称。
2. 组别:组别是变量根据分组逻辑来确定所在的分组。
所有的建模变量在建模前都进行分组,也称为变量离散化。
3. 评分:评分则是变量属于对应组别时的得分
利用评分表进行评分的方法如下:
来了一个新客户,先根据客户的数据,判断客户在各个特征上属于哪一组,然后在评分卡表中找到对应的分数,对所有特征得分求和,并加上基本分,就是客户的总评分。
假设客户在rev、due30、due90、city上的组别为【0、3、1、1】;
那么客户在rev、due30、due90、city上的得分为【28、-30、-20、5】;
则客户的总得分为28-30-20+5+780=763。
二、评分卡-建模思想与步骤
本节讲解评分卡的整体建模思路与建模步骤。
2.1. 评分卡的建模思路
在建模之前,先梳理评分卡建模大概的思路与流程,具体如下:
1. 先在原始数据中,衍生并选择出建模的变量。
2. 然后用建模变量与好坏客户标签建立逻辑回归模型。
这样就能通过建模变量预测样本是坏客户的概率。
3. 最后,把逻辑回归模型的线性部分抽取出来,生成评分卡。
最后的最后,还需要分析当前业务应以哪个分数作为拒绝客户的临界值,以临界值作为评分阈值。
2.2. 评分卡的建模流程
评分卡的整个建模过程共4步,如下:
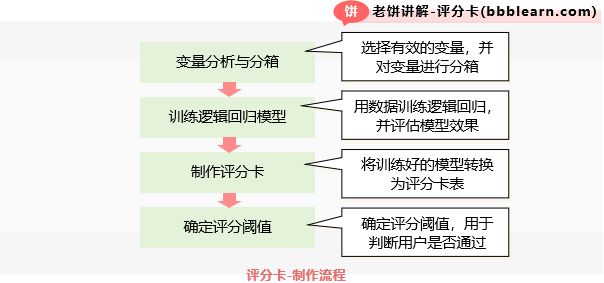
1. 建模数据准备
数据准备主要是建模前对原始数据进行分箱与变量分析,筛选出与客户质量相关的变量,作为入模变量。
2. 建模
(1) 数据预处理:归一化,并预留测试数据。
(2) 用逐步回归选出尽量少的特征(同时保持建模效果)。
(3) 训练逻辑回归模型。
(4) 检验AUC是否达标,并检查系数是否都为正。
3. 制作评分卡
制作评分卡也俗称“模型转评分”。
将3中得到的逻辑回归模型,制作成评分卡表。
4. 确定评分阈值
确定生产上判定为坏客户的分数阈值,当分数低于该阈值时,就拒绝客户。
结束语
好了,这节我们大概地介绍了数据、以及评分卡最终要建成什么样,并大概地介绍了评分卡的制作流程,下篇文章开始,我们以此问题为例,开始着手一步一步讲述如何构建评分卡模型~!
 评论
评论
- 教程
- bbbrisk
