-
一、CNN模型-学前解说
-
1.1.学前解说
-
-
二、经典CNN模型
-
2.1.LeNet
-
2.2.AlexNet
-
2.3.VGGNet
-
2.4.GoogLeNet
-
2.5.Inception-v2
-
2.6.Inception-v3
-
2.7.ResNet
-
2.8.U-Net
-
 老饼讲解:一步一步上手深度学习
老饼讲解:一步一步上手深度学习
【模型】一起来看看AlexNet的结构吧
好了,CNN的开山之作AlexNet来了!
AlexNet是2012年由Alex Krizhevsky和Geoffrey Hinton团队提出的卷积神经网络,在ImageNet竞赛中以15.3%的错误率夺冠,而第二名只有26.2%,远远不如它。AlexNet把图片识别的效果直接推上了一个高峰,正因为它一战成名,才掀起了CNN的浪潮~!它当之无愧,就是CNN的开山之作!
AlexNet原文为《ImageNet Classification with Deep Convolutional Neural Networks》
下面快让我们一起来看看它的结构吧!
一、AlexNet的整体结构
AlexNet年代久远了,同样地,我会把它的结构详详细细地讲清每一个细节,但大家选择性看看就好了,它最大的贡献是掀起了CNN的研究浪潮,鼓舞了计算机视觉的信心,但它的性能对现在来说其实是很一般的,没什么精髓,一句话,不要过于沉迷去玩。
好了,闲话不说,我们先来大概的了解AlexNet的整体结构吧~
1.1.AlexNet原文结构图
首先,我们来看看AlexNet原文提供给我们的模型结构:
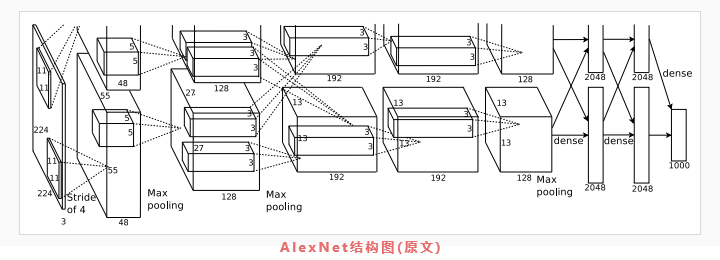
哎呀,不要仔细看了,有些抽象,看完我们下面的讲解,再回头看它吧。
1.2.AlexNet的整体结构
我们先来大概地看下,AlexNet大概是个什么结构,它的整体结构大概如下:
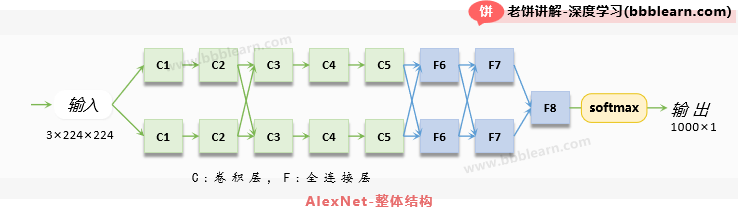
AlexNet的输入是3×224×224的图片,输出是1000×1的概率向量P, 第i个输出代表图片属于类别i的概率。
可以看到,在原文中AlexNet由双核构成,每个核都有8层,前五层是卷积层,后三层是全连接层,双核之间除了个别层会交换数据,大部分时候是独立的,最后,输出层汇聚双核的数据,训练一个全连接层再softmax后作为输出。
好了,整体结构大概地看到这就行了,下面看完每一层的详细结构,就对它了然于心了。
二、AlexNet每层的详细讲解
下面详细讲讲AlexNet每一层具体是怎么样的,由于讲得较细致、较具体,耐不住的可以跳过去,毕竟,AlexNet年代久远了,估计也用不上了,所以不用太较真。
AlexNet的输入和输出如下:
● AlexNet的输入:3×224×224的图片
● AlexNet的输出:1000×1的类别概率向量
好了,下面我们来详细说说AlexNet每一层的详细运算过程。
2.1. AlexNet-C1层
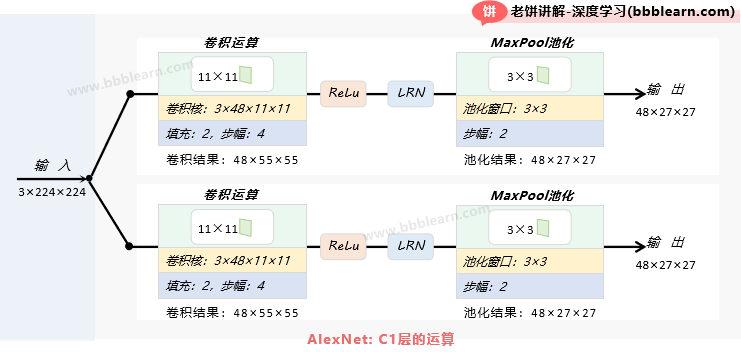
C1层的输入:3×224×224的图像
C1层的运算:
1. 卷积 :使用2组48个3×11×11,步幅为4、填充为2的卷积核进行卷积运算
卷积后2组的输出为:48×[(224+4-11)/4+1]×[(224+4-11)/4+1]=48×55×55
2. ReLu :将卷积结果进行ReLu
3. 归一化:将ReLu后的结果进行局部归一化(LRN)
4. 池化 :使用窗口大小为3×3,步幅为2的MaxPool进行池化
池化后2组的输出为:48×[(55-3)/2+1]×[(55-3)/2+1]=48×27×27
C1层的输出:2组48×27×27的特征图
这里使用到的LRN是AlexNet提出的一种归一化方法,具体计算我们后面再说。
2.2. AlexNet-C2层
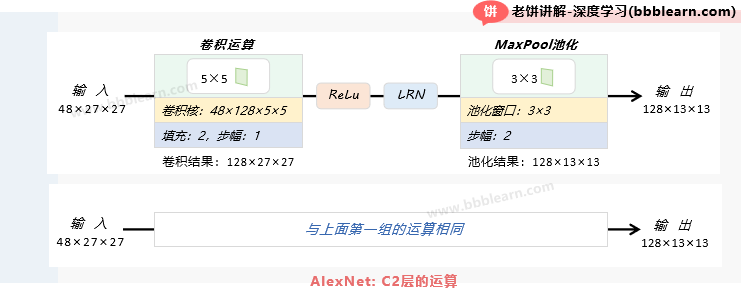
C2层的输入:C2层的输入为C1层的输出,即2组48×27×27的特征图
C2层的运算:
1. 卷积 :对每组各自使用128个48×5×5的卷积核,进行步幅为1、填充为2的卷积
卷积后2组的输出为:128×[(27+4-5)/1+1]×[(27+4-5)/1+1]=128×27×27
2. ReLu :将卷积结果进行ReLu
3. 归一化:将ReLu后的结果进行局部归一化
4. 池化 :使用窗口大小为3×3,步幅为2的MaxPool进行池化
池化后2组的输出为:128×[(27-3)/2+1]×[(27-3)/2+1]=128×13×13
C2层的输出:2组128×13×13的特征图
2.3. AlexNet-C3层
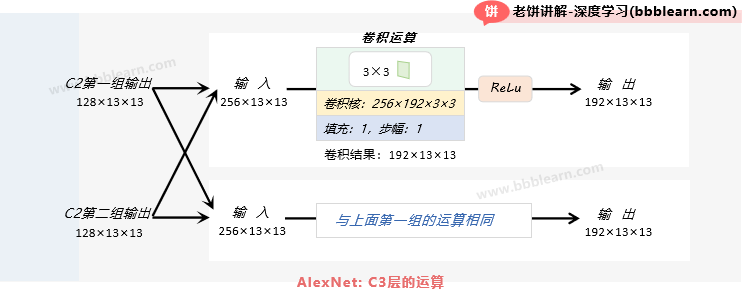
C3层的输入:C3层的每组输入为C2层两组输出的合并结果,即128*2×13×13=256×13×13的特征图
C3层的运算:
1. 卷积:对每组各自使用192个256×3×3的卷积核,进行步幅为1、填充为1的卷积
卷积后2组的输出为:192×[(13+2-3)/1+1]×[(13+2-3)/1+1]=192×13×13
2. ReLu:将卷积结果进行ReLu
C3层的输出:2组192×13×13的特征图
2.4. AlexNet-C4层
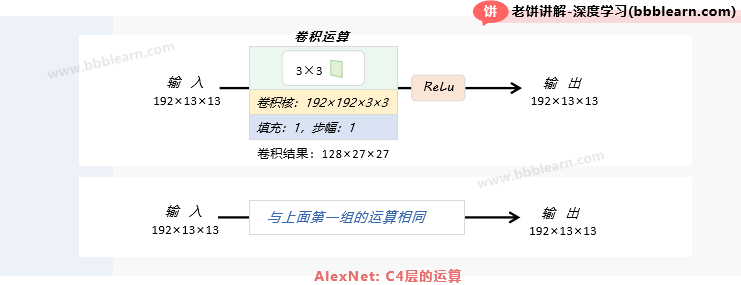
C4层的输入:C4层的输入为C3层的两组输出, 即2组192×13×13的特征图
C4层的运算:
1. 卷积:对每组各自使用192个192×3×3的卷积核,进行步幅为1、填充为1的卷积
卷积后2组的输出为:192×[(13+2-3)/1+1]×[(13+2-3)/1+1]=192×13×13
2. ReLu:将卷积结果进行ReLu
C4层的输出:2组192×13×13的特征图,总输出个数为192×13×13=64896
2.5. AlexNet-C5层

C5层的输入:C5层的输入为C4层的两组输出,即2组192×13×13的特征图
C5层的运算:
1. 卷积:对每组各自使用128个192×3×3的卷积核,进行步幅为1、填充为1的卷积计算
卷积后2组的输出为:128×[(13+2-3)/1+1]×[(13+2-3)/1+1]=128×13×13
2. ReLu:将卷积结果进行ReLu
3. 池化:使用窗口大小为3×3,步幅为2的MaxPool进行池化
池化后2组的输出为:128×[(13-3)/2+1]×[(13-3)/2+1]=128×6×6
C5层的输出:2组128×6×6的特征图,总输出个数为2×128×6×6=9216
2.6. AlexNet-F6层
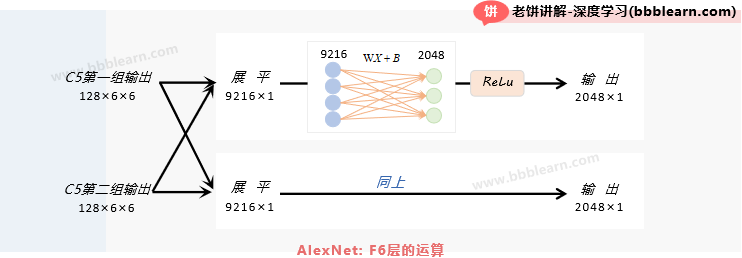
F6层的输入:F6的输入是C5层的两组输出合并再展平的结果,即2*(128*6*6)×1=9216×1的向量
F6层的运算:
1. 线性运算:对每组各自使用输入为9216,输出为2048的线性运算
2. ReLu:将线性结果进行ReLu
F6层的输出:2组2048×1的向量,总输出个数为2*2048*1=4096
2.7. AlexNet-F7层
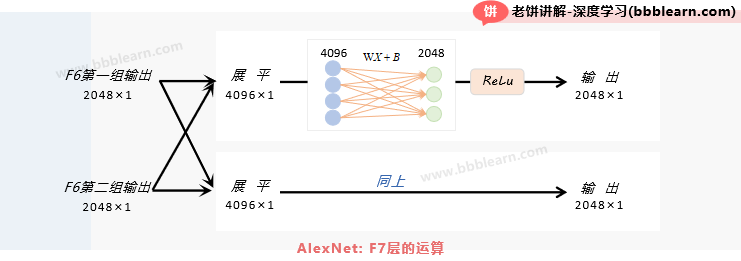
F7层的输入:F7的输入是F6的2组输出合并的结果,即2*2048×1=4096×1的向量
F7层的运算:
1. 线性运算:对每组各自使用输入为4096,输出为2048的线性运算
2. ReLu:将线性结果进行ReLu
F7层的输出:2组2048×1的向量,总输出个数为2*2048*1=4096
2.7. AlexNet-F8层
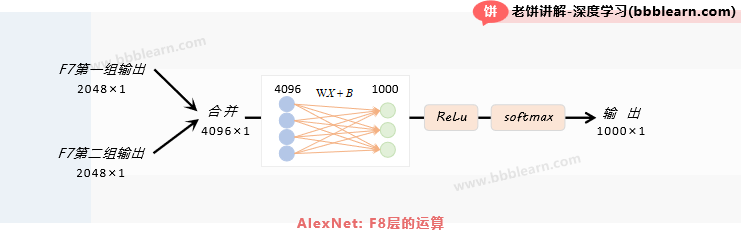
F8层的输入:F8的输入是F7的2组输出合并的结果,即2*2048×1=4096×1的向量
F8层的运算:
1. 线性运算:使用输入为4096,输出为1000(类别个数)的线性运算
2. ReLu:将线性结果进行ReLu
3. softmax:将ReLu结果进行softmax
F8层的输出:1000×1的向量,总输出个数为1000*1=4096
三、AlexNet的配置表
好了,将以上的结构与配置,整理成配置表,我们整体看下AlexNet的整体情况。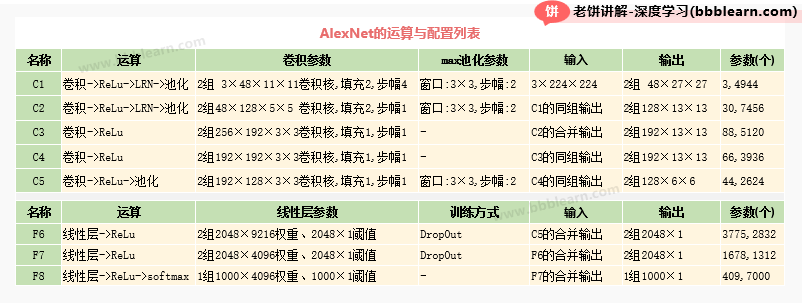
从配置表可以大概看出,AlexNet的参数有大大好几千万,主要集中在全连接层上,它的运算量是非常大的,难怪当时要用双核来跑。
总结
这节我们又详细地考古了AlexNet的模型结构,它算是第一个挖掘出了卷积神经网络的实用能力的模型。它继承了LeNet先卷积+池化进行特征压缩、再用MLP进行拟合的结构。从它身上我们可以看到,ReLu呀、Dropout呀,这些技术也随着它的使用,而被发扬光大。
 评论
评论
