目录
-
一、CNN模型-学前解说
-
1.1.学前解说
-
-
二、经典CNN模型
-
2.1.LeNet
-
2.2.AlexNet
-
2.3.VGGNet
-
2.4.GoogLeNet
-
2.5.Inception-v2
-
2.6.Inception-v3
-
2.7.ResNet
-
2.8.U-Net
-
 老饼讲解:一步一步上手深度学习
老饼讲解:一步一步上手深度学习
【代码】一起来看看LeNet的代码实现
作者 : 老饼
发表日期 : 2025-10-15 07:23:09
更新日期 : 2026-05-21 18:02:38
老饼讲解-简单易懂,干货满满,爽过嗦螺!
好了,下面让我们实现一个LeNet-5吧~
一、LeNet-5代码实现
1.1. LeNet-5-严谨代码实现
在我刚开始学习、还没完全弄懂LeNet-5的结构的时候,我想借着代码来理解LeNet-5,但找了许久,都没有找到LeNet-5的真实实现,因为那些代码与我在原文已经看到的结构不一样。
最后花了3、4天才把原文中的结构整理出来,我才明白,为啥这东西没有真实实现。原因有三点,一方面是它实现有点繁琐,另一方面它的F7层是根据具体问题具体设计的,不能直接实现。更更更重要的是,LeNet-5实在太过时啦,花这么多力气去实现它,实在没什么价值。当然,我也不介意去实现,毕竟我是弄教程的嘛,但仔细一想,大家读这种模型的代码也亏得很,又复杂又没营养。so,别说实现它了,连读它的代码都不值得读!所以我也不实现啦。
1.2. LeNet-5-简化代码实现
现在所说的、所实现的LeNet-5,一般指的都是沿用它整体结构的现代结构,也就是下图这样的结构:

好了,我们就按这样简单的实现一下吧,具体代码如下:
# 本代码用于实现一个LENET卷积神经网络
# 本代码来自《老饼讲解-深度学习》www.bbblearn.com
import torch
from torch import nn
from torch.utils.data import DataLoader
import torchvision
import numpy as np
#--------------------模型结构----------------------
# 卷积神经网络的结构
class ConvNet(nn.Module):
def __init__(self,in_channel,num_classes):
super(ConvNet, self).__init__()
self.nn_stack=nn.Sequential(
#--------------C1层-------------------
nn.Conv2d(in_channel,6, kernel_size=5,stride=1,padding=2),
nn.AvgPool2d(kernel_size=2,stride=2),
nn.Sigmoid(),
# 输出14*14
#--------------C2层-------------------
nn.Conv2d(6,16, kernel_size=5,stride=1,padding=0),
nn.AvgPool2d(kernel_size=2,stride=2),
# 输出7*7
#--------------C3层-------------------
nn.Conv2d(16,120,kernel_size=5,stride=1,padding=0),
# 输出120*1*1
#--------------全连接层F4----------
nn.Flatten(), # 对C3的结果进行展平
nn.Linear(120, 84),
nn.Tanh(),
#--------------全连接层F5----------
nn.Linear(84, num_classes)
)
def forward(self, x):
p = self.nn_stack(x)
return p
#-----------------------模型训练-----------------
# 训练函数
def train(dataloader,model,optimizer,epochs,goal):
print("\n--开始训练--:") # 打印准确率
for epoch in range(epochs): # 逐步训练
for batch, (x, y) in enumerate(dataloader): # 逐批训练
# -----训练模型-----
optimizer.zero_grad() # 将优化器里的参数梯度清空
py = model(x) # 计算模型的预测值
loss = lossFun(py, y) # 计算损失函数值
loss.backward() # 更新参数的梯度
optimizer.step() # 更新参数
acc_rate = calAcc(model,dataloader) # 计算数据集的准确率
print(f"第{epoch}步,准确率:",acc_rate) # 打印准确率
if(acc_rate>=goal): # 检查退出条件
break
# 计算数据集的准确率
def calAcc(model,dataLoader):
py = np.empty(0) # 初始化预测结果
y = np.empty(0) # 初始化真实结果
for batch, (imgs, labels) in enumerate(dataLoader): # 逐批预测
cur_py = model(imgs) # 计算网络的输出
cur_py = torch.argmax(cur_py,axis=1) # 将最大者作为预测结果
py = np.hstack((py,cur_py.detach().cpu().numpy())) # 记录本批预测的y
y = np.hstack((y,labels)) # 记录本批真实的y
acc_rate = sum(y==py)/len(y) # 计算测试样本的准确率
return acc_rate
#--------------主流程脚本----------------------
#-------------------加载数据------------------------
train_data = torchvision.datasets.MNIST(
root = 'D:\\pytorch\\data' # 路径有,就从路径中加载,否则联网获取
,download = True # 是否下载,选为True,就下载到root下面
,train = True # 获取训练数据
,transform = torchvision.transforms.ToTensor() # 转换为tensor数据
,target_transform= None)
test_data = torchvision.datasets.MNIST(
root = 'D:\\pytorch\\data' # 路径有,就从路径中加载,否则联网获取
,download = True # 是否下载,选为True,就下载到root下面
,train = False # 获取测试数据
,transform = torchvision.transforms.ToTensor() # 转换为tensor数据
,target_transform= None)
#-------------------模型训练--------------------------------
trainLoader = DataLoader(train_data, batch_size=100, shuffle=True) # 将训练数据装载到DataLoader
testLoader = DataLoader(test_data , batch_size=100) # 将测试数据装载到DataLoader
model = ConvNet(in_channel =1,num_classes=10) # 初始化模型
lossFun = torch.nn.CrossEntropyLoss() # 定义损失函数为交叉熵损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=0.05,momentum =0.9) # 初始化优化器
train(trainLoader,model,optimizer,1000,0.99) # 训练模型
# -----------模型效果评估---------------------------
print("\n--训练结果--:") # 打印训练结果
train_acc_rate = calAcc(model,trainLoader) # 计算训练数据集的准确率
print("训练数据的准确率:",train_acc_rate) # 打印准确率
test_acc_rate = calAcc(model,testLoader) # 计算测试数据集的准确率
print("测试数据的准确率:",test_acc_rate) # 打印准确率运行结果如下:
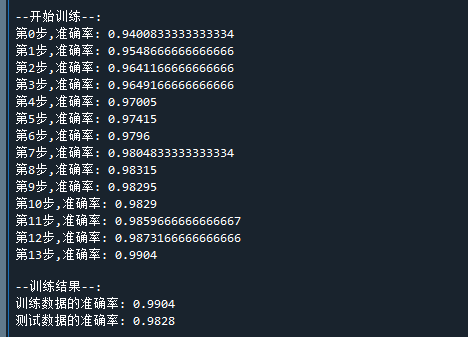
可以看到,LeNet在手写数字识别上是完全没问题的~
这里代码我们就不解说了,相信对现在的大家,模型结构部分的代码完全没问题,而训练代码也是我们之前所用的,所以完全不用解说。
总结
LeNet原始结构都已经成为史料啦~大概了解、大概实现一下就好啦,而且,现在大家说"用LeNet来解决这问题吧",也不是指原文中的结构,而是这种简化结构。
上一篇:
【模型】一起来看看LeNet的模型结构
下一篇:
【拓展】一起来聊聊LeNet的小故事吧
 评论
评论
添加评论
