-
一、CNN模型-学前解说
-
1.1.学前解说
-
-
二、经典CNN模型
-
2.1.LeNet
-
2.2.AlexNet
-
2.3.VGGNet
-
2.4.GoogLeNet
-
2.5.Inception-v2
-
2.6.Inception-v3
-
2.7.ResNet
-
2.8.U-Net
-
 老饼讲解:一步一步上手深度学习
老饼讲解:一步一步上手深度学习
【模型】一起来看看LeNet的模型结构
好了,这节我们一起来看看LeNet吧。
LeNet是Yann LeCun于1988年提出的模型,后来1998年又提出了一个更完善的版本LeNet-5,用于手写数字识别,是第一个CNN投于应用的模型,可以算是CNN的起源模型,形成了CNN的结构雏形。
现在一般说的LeNet,其实都是指LeNet-5,下面我们就看看LeNet-5的模型结构吧。
LeNet-5原文地址:《Gradient-based learning applied to document recognition》
一、LeNet-5模型结构
这里先说了哦,LeNet-5年代已经久远,很多东西已经过时了,大家不要太过较真它的细节,虽然我会详细的去说它的每一个细节,但大家可以选择性的去看,别太认真浪费时间。
1.1.LeNet-5模型整体结构
好了,我们先来晒一张LeNet-5原文中的结构图,如下:
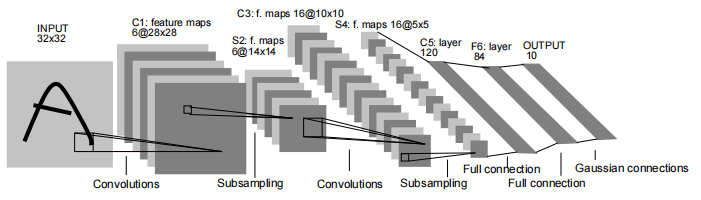
大家不要太紧张,这图我看着也很晕,下面理解了再回头看就明白它是什么了。
我们先来说说它的整体结构,它是如下的结构:
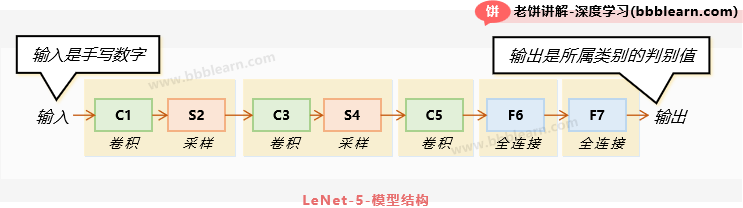
可以看到,它一共七层,也可以认为五大层,因为卷积+采样连在一起可以认为就是一个特征压缩层。这里的采样可以理解为后来的池化层哦,而F6+F7,两个全连接层则可以认为就是一个三层MLP。因此,LeNet总的来说,就是两次特征压缩,再加一个卷积,最后就是MLP了。
二、LeNet模型结构-详细讲解
LeNet-5的输入和输出如下:
● LeNet-5的输入:1×28×28的图片(手写数字)。
● LeNet-5的输出:图片所属类别的判别值向量 。
好了,下面我们来详细说说LeNet-5每一层的详细运算过程。
2.1. LeNet-C1层

C1的输入:C1是卷积层,它的输入是1×28×28的图片
C1的运算:C1利用6个1×5×5的卷积核进行卷积,填充为2,步幅为1
卷积后的输出则为6通道的(28+4-5+1)×(28+4-5+1)=28×28的FeatureMap
C1的输出:6×28×28的特征映射图
2.2. LeNet-S2层
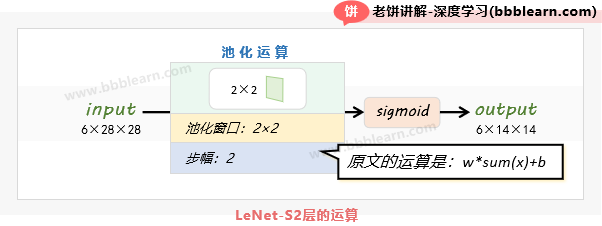
S2的输入:S2是采样层(池化层),它的输入是C1的输出,即6×28×28的特征映射图
S2的运算:S2的运算包括池化与激活两个步骤
1. 池化:采用Size为2×2,步幅为2的池化窗口对输入进行均值池化
原文称为采样层,类似池化,但它的运算是:
也就是将窗口所有值相加,再乘以一个系数,并加上阈值。
原文这样干是希望不同通道用不同系数,使得输出通道有些是高频信息,有些是低频信息。
池化后为6个(28/2)×(28/2)=14×14的特征映射图
2. 激活:将池化后的结果使用sigmoid函数进行激活
S2的输出:6×14×14的特征映射图
2.3. LeNet-C3层

C3的输入:C3是卷积层,它的输入是S2的输出,即6×14×14的特征映射图
C3的运算:C3使用16个a×5×5的卷积核进行卷积,填充为0,步幅为1
16个卷积核的输入通道是不同的,因为每个卷积核都连接不同的输入通道
卷积后的输出则为16个[(14+0-5)/1+1]×[(14+0-5)/1+1]=10×10的特征映射图
C3与S2的连接:C3与S2的连接方式较为特殊,采用非完全连接方式
C3的16个卷积核与S2的连接方式详细如下:
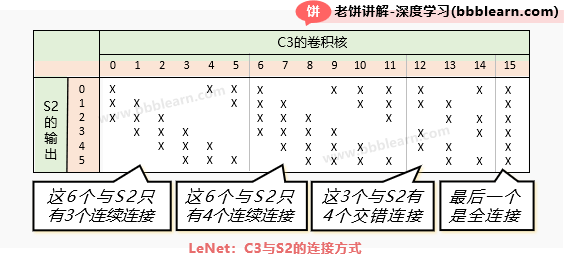
总的来说,共有四种连接类型:
👉1.前6个是连续连接三组
👉2.后6个是连续连接4组
👉3.再之后的3三个是不连续连接的4组
👉4.最后一个是全连接
这样的连接在生物意义上理解为尽量充分地从不同角度、不同粒度地观察S2。
C3的输出:16×10×10的特征映射图
2.4. LeNet-S4层

S4的输入:S4是采样层(池化层),它的输入是C3的输出,即16×10×10的特征映射图
S4的运算:S4采用Size为2×2,步幅为2的池化窗口对输入进行均值池化
与S2类似,原文这里是采样层,即将窗口所有值相加,再乘以一个系数,并加上阈值
池化后为[10/2]×[10/2]=5×5的特征映射图
S4的输出:16×5×5的特征映射图
2.5. LeNet-C5层

C5的输入:C5是卷积层,它的输入是S4层的输出,即16×5×5的特征映射图
C5的运算:C5使用120个16×5×5的卷积核进行卷积,填充为0步幅为1
卷积后的输出则为120个[5/5]×[5/5]=1×1的特征映射图
C5的输出:120×1×1的特征映射图
2.6. LeNet-F6层
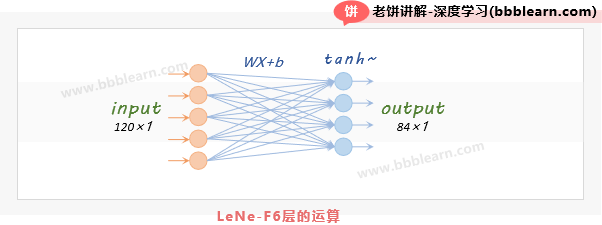
F6的输入:F6是全连接层,它的输入是C5层的输出展平后的向量,即120×1向量
F6的运算:F6是传统神经网络的运算方法,激活函数使用tanh
F6的计算具体如下:
其中,
X:120×1的输入向量
W:权重,84×120的矩阵
b :阈值,84×1的列向量
tanh:双曲正切函数
y:F6层的输出
F6的输出:84×1的列向量
2.7. LeNet-F7层
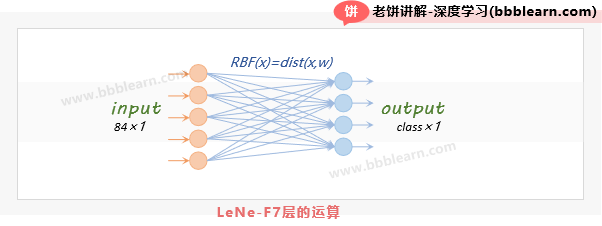
F7的输入:F7是最后的输出层,它是全连接层,它的输入是F6层的输出,即84×1的列向量
F7的运算:有多少个类别,F7就有多少个神经元,F7与F6全连接,用RBF函数作为激活函数
F7的计算公式如下:
其中,
:F7的第i个输出
:F6层第j个神经元与F7第i个神经元的权重
即,F7的第i输出就是F6的输出与Wi的欧基里得距离平方。
F7的输出:类别个数×1的列向量
F7层的意义大概是: 用来代表第个类别的坐标,F6的输出(即F7的输入)与的距离越近,则输出就越小。最终对比F7的所有输出值,如果第k个输出值最小,就判为第k类。有的小伙伴可能会疑问,F7的计算明明是dist函数,为什么说是RBF激活函数呢?其实严格的RBF激活函数应该是,但作为类别判别,只取作为判别值也是一样的。
注意,F6与F7的连接权重是根据背景意义精心设计的,设计完后可以在训练中调整,也可以不调整。
好了,以上就是LeNet-5模型的详细结构了。
LeNet结构也不是很复杂,许多没看论文的人或许不理解为什么我要用3、4天才把它的结构整理出来的,这么说吧,你看它原文的结构图就那样,然后描述呢,并不是一次性说出来的,这一段、那一句,我是边在论文字里行间进行淘沙,边找网文核对,直到论文里找不到漏缺的、各种网文里也对得上时,才拼凑出它的结构来。我这该死的强迫症呀!我现在也不能保证这结构是100%对的,但至少,它应该是你能看到的、最准确的了。
三、LeNet-5的配置表
最后,我们一起看看LeNet-5的整体配置表,如下:
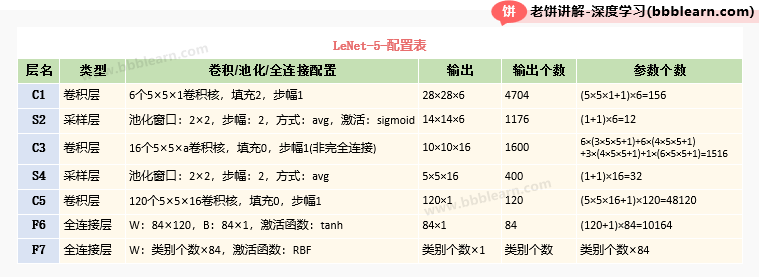
可以看到,整个卷积、池化层,基本是没有多少参数的,主要的参数都在F6中。所以LeNet通过少量参数来压缩了输入特征,再交给MLP,使得训练效果大大提升。
总结
好了,这节我们看了LeNet的整体结构,从中可以看到,它差不多就奠定了卷积神经网络的基本结构。而在一些细节上,例如采样层加入系数来输出高低频信息呀、C3层采用非全连接的卷积方式来捕捉不同角度的信息呀,等等,虽然现在都不用了,但这并不能否定这些思想的启发意义。
 评论
评论
