-
一、Transfomer-学前解说
-
1.1.学前解说
-
- 二、Transfomer-背景内容
- 三、正式学Transfomer啦
- 四、一起来看看BERT
 老饼讲解:一步一步上手深度学习
老饼讲解:一步一步上手深度学习
【模型】RNN-编解码模型-基础模型
上节我们已经了解RNN-编解码模型的大概思想,这节我们来看一个比较经典的、基础的RNN-Encoder-Decoder模型,它出自2014年的论文《Sequence to Sequence Learning with Neural Networks》,原文用它来解决翻译问题。这个模型是非常基础的、可以把它当成一个裸机模型,其它的RNN-Encoder-Decoder模型都是在它的基础上加东西,因此我们不妨称它为RNN-编码码-基础模型。
一、RNN-编解码-基础模型
好了,这节我们要介绍的RNN-编解码-基础模型,它的整体结构如下:
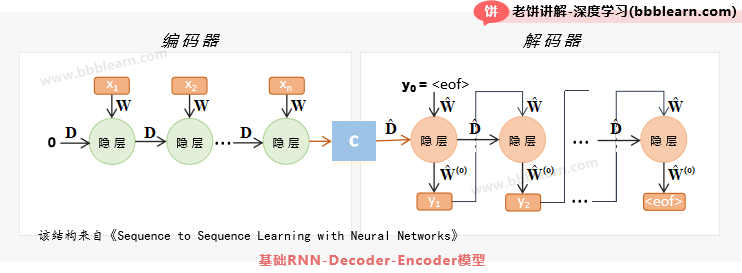
我们一起看一下它的结构,首先,原文是用它来解决翻译问题的,所以它的输入与输出都是词元的one-hot向量。
我们先来看看它的编码器部分。它的编码器是一个没有输出的RNN,然后通过将各时刻的输入不断地投喂给它,它的隐节点就承载了各个时刻的输入信息,最后,将末时刻的隐节点,作为编码C。
接下来是解码器部分,它相对比较复杂些,我们来重点讲解一下它。
Decoder部分是一个带有输出的RNN,下面细看它的实时输入与延迟输入值。
解码器的实时输入:它用上一时刻的输出作为当前时刻的实时输入,即:
实时输入的初始值用终止符来初始化:, 即实时输入为
解码器的延迟输入:解码器的延迟输入用c来初始化, 即延迟输入为:
关于终止条件:解码器不断用前一个输出预测下一个输出,直到输出结束符<eof>则结束。
模型必须先指定一个结束符,不妨假设为"<eof>",模型训练时,每一个训练输出样本都以"<eof>"作为终结符,这样模型预测时,当解码器输出"<eof>"时则认为预测结束。
关于倒序预测:论文《Sequence to Sequence Learning with Neural Networks》一直强调,倒序预测效果会更好。倒序预测是指把输入倒序输入,例如原本用"a,b,c"预测"1,2,3",在输入网络时则输入"c,b,a"来预测"1,2,3",这是因为a与1的相关性更强,倒序输入使最后的隐节点记载了更多与a相关的信息,因此下一个预测1的效果更好。
二、RNN-编码码-基础模型-详细计算流程
好了,下面为了更具体的了解上面所说的RNN-编解码-基础模型,我们一步一步来详细地看一下它的计算流程。它的流程共分为三步:迭代编码器、输出编码C、计算解码器。
1. 编码器的迭代
编码器的迭代公式为:
其中,
按照上述公式,逐时刻计算编码器的隐层就可以了。
2. 输出编码c
编码器计算完后,将它末时刻的隐层作为编码c就可以了,即:
这是因为末时刻的隐层已经承载了所有输入的序列信息,所以直接就把末时刻的隐层作为编码c了。
3. 解码器的迭代
好了,接下来就是把编码c通过解码器转换为输出了。
其中,,
备注:原文中使用的是LSTM,这里笔者为了简化,使用RNN替代LSTM。
三、TeachForcing训练
Encoder-Decoder模型的训练一般以teachForcing的方式进行训练,teachForcing方式是指,在训练阶段以真实的来作为解码器的实时输入,而不是预测值,也就是说,模型训练时的实时输入为,然后期待的输出为 。
模型训练时解码器之所以不用预测的来作为实时输入,是因为初始解是非常糟糕的,在模型初始阶段,很难得到终止符"<eof>"的输出 ,这样解码器模型会不断的预测下去,而反过来,如果以真实值训练成功时,那么模型的预测值与真实值是近似的,也就是说,用真实值训练与用预测值训练,在训练成功时,模型的训练结果是殊途同归的。
这样,输出长度在训练时是确定的,使训练得以实施,同时,这样训练也会更加快些,因为输入是真实的数据。
总结
好了,这节我们看了RNN-编解码的基础模型,它的模型结构是简单的、基础的,然后我们后面再在它的基础上,一步步去看它是如何演化出更复杂的Encoder-Decoder模型的。在原文中,它是用LSTM来作为隐神经元,因为这样效果更好些,但这里作为学习,为了通用性,所以我把它改为了基础RNN神经元来讲述。
 评论
评论
